使用專用任務模型提升性能
Open-WebUI 提供了多種自動化功能,例如標題生成、標籤創建、自動完成和搜尋查詢生成,以提升使用者體驗。這些功能可能會對您的本地模型產生多個同時請求,進而影響資源有限系統的性能表現。
本指南說明如何通過配置專用的輕量級任務模型或有選擇地停用自動化功能來優化設置,從而確保主要聊天功能的響應速度和效率。
[!TIP]
為什麼 Open-WebUI 感覺很慢?
默認情況下,Open-WebUI 有多個背景任務,這些任務讓它感覺像是魔法,但也可能對本地資源帶來巨大負擔:
- 標題生成
- 標籤生成
- 自動完成生成(此功能在每次按鍵時觸發)
- 搜尋查詢生成
這些功能中的每一項都會向您的模型發出異步請求。例如,自動完成功能的持續調用可能會明顯延遲內存或處理能力有限的設備(如運行 32B 量化��模型且擁有 32GB RAM 的 Mac)的響應。
優化任務模型可以幫助將這些背景任務與主要聊天應用隔離,從而提升總體的響應速度。
⚡ 如何優化任務模型性能
按照以下步驟配置高效的任務模型:
步驟 1:進入管理面板
- 在瀏覽器中打開 Open-WebUI。
- 前往 管理面板。
- 點擊側邊欄中的 設置。
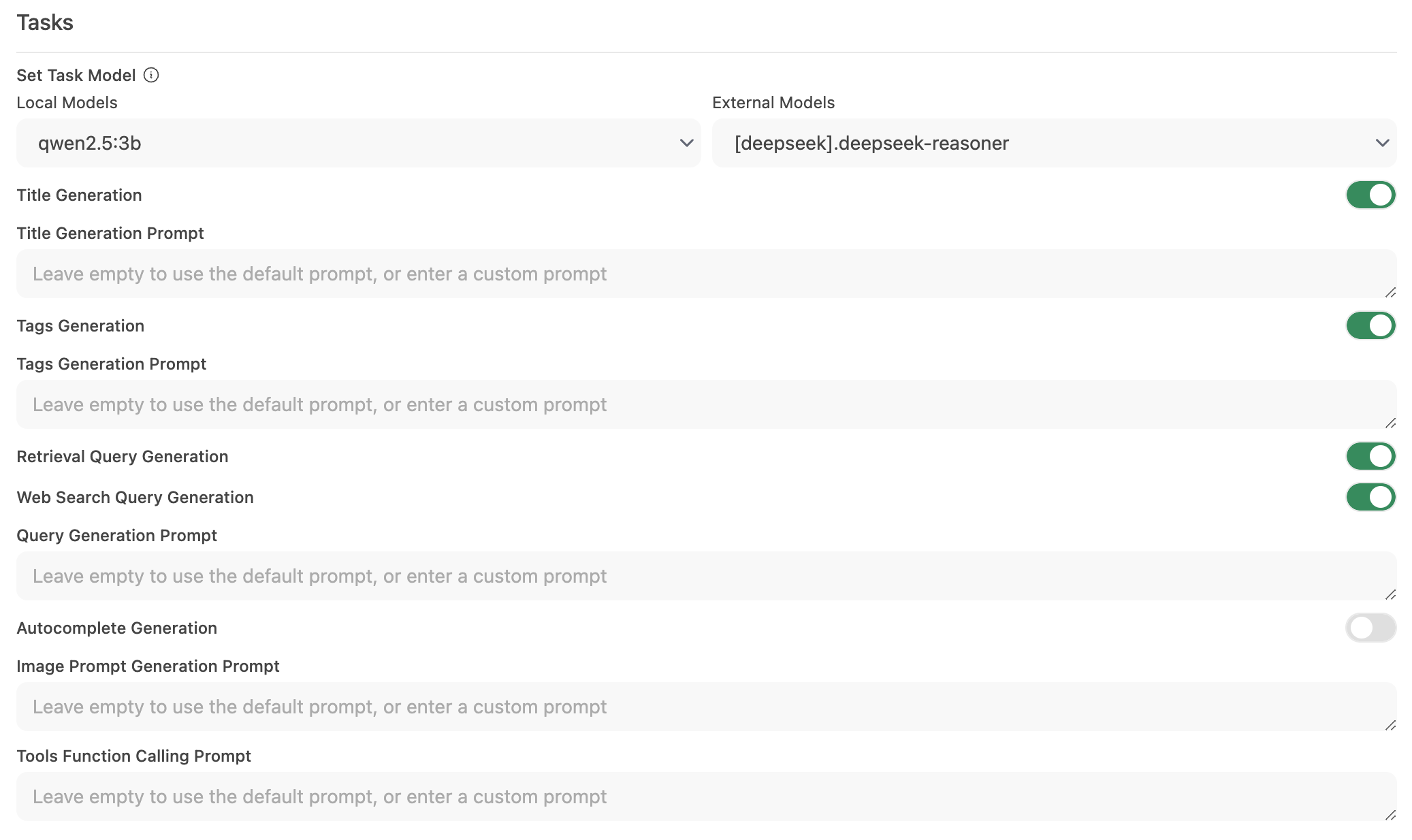
步驟 2:配置任務模型
-
轉到 介面 > 設置任務模型。
-
根據需求選擇以下選項之一:
-
輕量化本地模型(推薦)
- 選擇一個緊湊的模型,例如 Llama 3.2 3B 或 Qwen2.5 3B。
- 這些模型提供快速響應,同時消耗系統資源極少。
-
託管 API 端點(最大速度)
- 連接到託管 API 服務以處理任務。
- 這可能非常便宜。例如,OpenRouter 提供的 Llama 和 Qwen 模型每百萬輸入 token 僅需 1.5 美分以下。
-
停用非必要的自動化功能
- 如果不需要某些自動化功能,可停用它們以減少不必要的背景調用,特別是像自動完成這類功能。
-
步驟 3:保存變更並測試
- 保存新的配置。
- 與您的聊天介面互動並觀察其響應速度。
- 如果需要,可進一步停用未使用的自動化功能或嘗試不同的任務模型。
🚀 本地模型的推薦設置
| 優化策略 | 優點 | 適合對象 |
|---|---|---|
| 輕量化本地模型 | 將資源使用降至最低 | 資源有限的系統 |
| 託管 API 端點 | 提供最快的響應時間 | 具有穩定網路/API 訪問的使用者 |
| 停用自動化功能 | 通過減少負載最大化性能 | 專注於核心聊天功能的使用者 |
實施這些建議可以顯著改善 Open-WebUI 的響應速度,同時讓本地模型高效處理聊天互動。
💡 額外提示
- 監控系統資源: 使用作業系統的工具(如 macOS 的活動監視器或 Windows 的任務管理器)來關注資源使用情況。
- 減少並行模型調用: 限制背景自動化功能以防止同時請求壓垮您的 LLM。
- 嘗試不同配置: 測試不同的輕量化模型或託管端點,以找到速度和功能之間的最佳平衡。
- 保持更新: 定期更新 Open-WebUI,因為更新通常包含性能改進和錯誤修復,確保軟體保持最新。
通過應用這些配置更改,您將能夠支持更響應高效的 Open-WebUI 體驗,使您的本地 LLM 專注於提供高品質的聊天互動而不會出現不必要的延遲。