Улучшение производительности с помощью специализированных моделей для задач
Open-WebUI предоставляет несколько автоматических функций, таких как генерация заголовков, создание тегов, автозаполнение и генерация поисковых запросов, чтобы улучшить пользовательский опыт. Однако эти функции могут создавать множественные одновременно выполняющиеся запросы к вашей локальной модели, что может повлиять на производительность на системах с ограниченными ресурсами.
Этот гид объясняет, как оптимизировать вашу конфигурацию, настроив специализированную легковесную модель для задач или избирательно отключив автоматические функции, чтобы гарантировать, что основная функция чата остается отзывчивой и эффективной.
[!TIP]
Почему Open-WebUI работает медленно?
По умолчанию Open-WebUI имеет несколько фоновых задач, которые могут показаться магическими, но в то же время создают значительную нагрузку на локальные ресурсы:
- Генерация заголовков
- Создание тегов
- Генерация автозаполнения (эта функция активируется на каждом нажатии клавиши)
- Генерация поисковых запросов
Каждая из этих функций выполняет асинхронные запросы к вашей модели. Например, непрерывные вызовы функции автозаполнения могут значительно задерживать ответы на устройствах с ограниченной памятью или вычислительной мощностью, таких как Mac с 32 ГБ оперативной памяти, работающий на 32B квантованной модели.
Оптимизация модели задач может помочь изолировать эти фоновые задачи от вашего основного приложения для чата, улучшая общую отзывчивость.
⚡ Как оптимизировать производительность модели задач
Следуйте этим шагам для настройки эффективной модели для задач:
Шаг 1: Доступ к панели администратора
- Откройте Open-WebUI в вашем браузере.
- Перейдите в Панель администратора.
- Нажмите на Настройки в боковой панели.
Шаг 2: Настройка модели задач
-
Перейдите в Интерфейс > Установить модель задач.
-
Выберите один из следующих вариантов в зависимости от ваших нужд:
-
Легковесная локальная модель (рекомендуется)
- Выберите компактную модель, такую как Llama 3.2 3B или Qwen2.5 3B.
- Эти модели обеспечивают быстрые ответы при минимальном потреблении системных ресурсов.
-
Хостируемый конечный API (для максимальной скорости)
- Подключитесь к хостируемому API-сервису для обработки задач.
- Это может быть очень дешево. Например, OpenRouter предлагает модели Llama и Qwen по цене менее 1.5 цента за миллион входных токенов.
-
Отключение ненужных автоматических функций
- Если определенные автоматические функции не требуются, отключите их, чтобы уменьшить лишние фоновые вызовы — особенно такие функции, как автозаполнение.
-
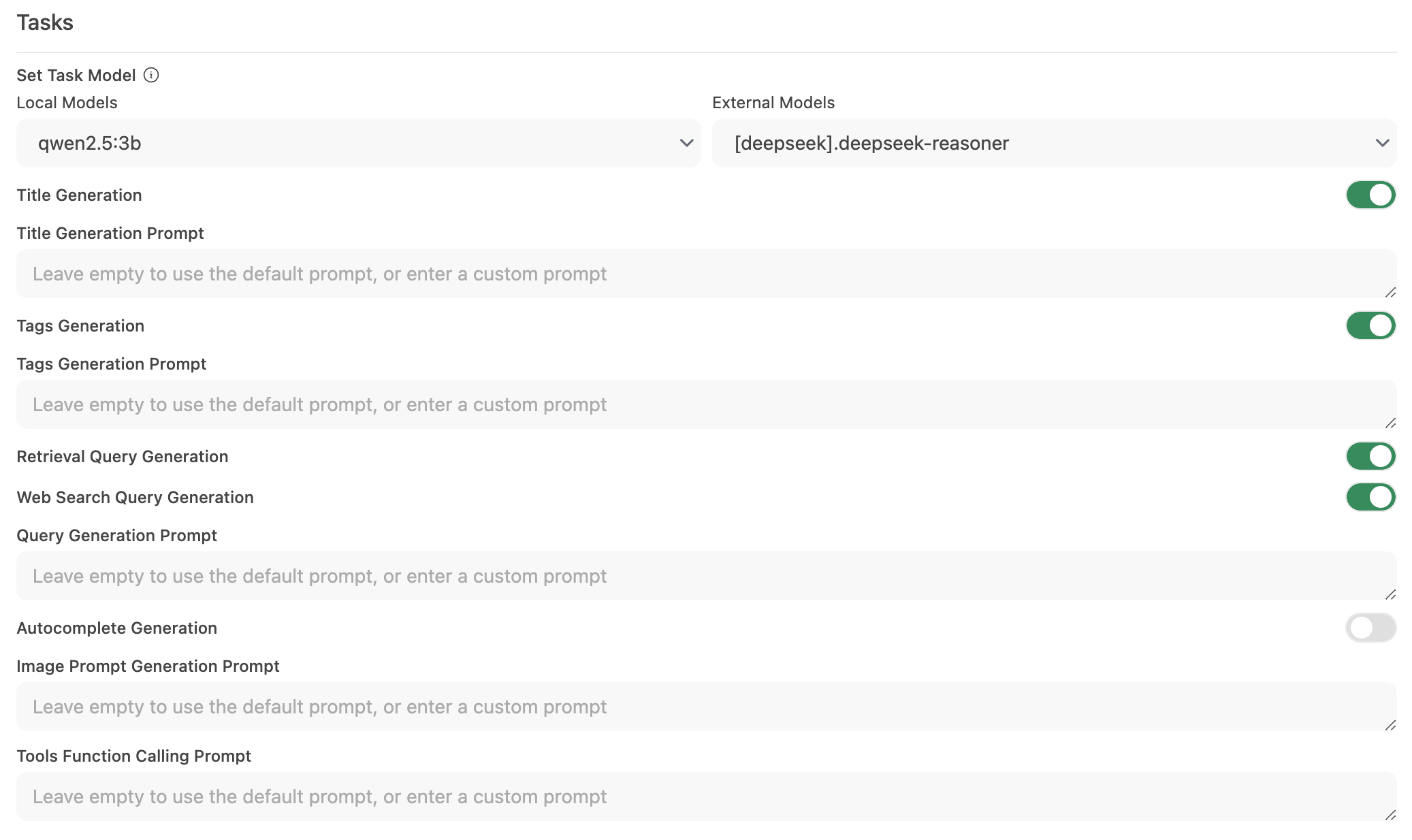
Шаг 3: Сохраните изменения и протестируйте
- Сохраните новую конфигурацию.
- Взаимодействуйте с интерфейсом чата и наблюдайте за отзывчивостью.
- При необходимости настройте, еще больше отключив неиспользуемые автоматические функции или экспериментируя с различными моделями задач.
🚀 Рекомендуемая конфигурация для локальных моделей
| Стратегия оптимизации | Преимущество | Рекомендуется для |
|---|---|---|
| Легковесная локальная модель | Минимизирует использование ресурсов | Системы с ограниченным оборудованием |
| Хостируемый конечный API | Обеспечивает самые быстрые времена отклика | Пользователи с надежным доступом к интернет/API |
| Отключение автоматических функций | Максимизирует производительность, уменьшив нагрузку | Те, кто сосредоточен только на функциональности чата |
Реализация этих рекомендаций может значительно улучшить отзывчивость Open-WebUI, позволяя вашим локальным моделям эффективно обрабатывать взаимодействия в чате.
💡 Дополнительные советы
- Мониторинг системны�х ресурсов: Используйте инструменты вашей операционной системы (такие как Activity Monitor на macOS или Диспетчер задач на Windows), чтобы следить за использованием ресурсов.
- Сокращение параллельных вызовов модели: Ограничение фоновой автоматизации предотвращает переполнение LLM запросами.
- Экспериментируйте с конфигурациями: Тестируйте различные легковесные модели или хостируемые конечные точки, чтобы найти оптимальный баланс между скоростью и функциональностью.
- Будьте в курсе обновлений: Регулярные обновления Open-WebUI часто включают улучшения производительности и исправления ошибок, так что поддерживайте ваше ПО в актуальном состоянии.
Применяя эти изменения конфигурации, вы обеспечите более отзывчивый и эффективный опыт работы с Open-WebUI, позволяя вашей локальной модели LLM сосредоточиться на предоставлении высококачественных взаимодействий в чате без ненужных задержек.