Améliorez les performances avec des modèles dédiés aux tâches
Open-WebUI propose plusieurs fonctionnalités automatisées—telles que la génération de titres, la création de tags, l'autocomplétion et la génération de requêtes de recherche—pour améliorer l'expérience utilisateur. Cependant, ces fonctionnalités peuvent générer de multiples requêtes simultanées vers votre modèle local, ce qui peut nuire aux performances sur les systèmes avec des ressources limitées.
Ce guide explique comment optimiser votre configuration en configurant un modèle de tâche dédié et léger, ou en désactivant sélectivement les fonctionnalités automatiques, pour garantir que votre fonctionnalité principale de chat reste réactive et efficace.
[!ASTUCE]
Pourquoi Open-WebUI semble lent ?
Par défaut, Open-WebUI possède plusieurs tâches d'arrière-plan qui peuvent donner l'impression de magie, mais qui peuvent également imposer une charge importante sur les ressources locales :
- Génération de titre
- Génération de tags
- Génération d'autocomplétion (cette fonction se déclenche à chaque frappe)
- Génération de requêtes de recherche
Chacune de ces fonctionnalités effectue des requêtes asynchrones vers votre modèle. Par exemple, des appels continus de la fonction d'autocomplétion peuvent considérablement retarder les réponses sur des appareils avec une mémoire ou une puissance de traitement limitées, tels qu'un Mac avec 32 Go de RAM exécutant un modèle quantifié 32B.
L'optimisation du modèle de tâches peut aider à isoler ces tâches d'arrière-plan de votre application principale de chat, améliorant ainsi la réactivité globale.
⚡ Comment optimiser les performances du modèle de tâches
Suivez ces étapes pour configurer un modèle de tâche efficace :
Étape 1 : Accéder au panneau d'administration
- Ouvrez Open-WebUI dans votre navigateur.
- Accédez au panneau d'administration.
- Cliquez sur Paramètres dans le menu latéral.
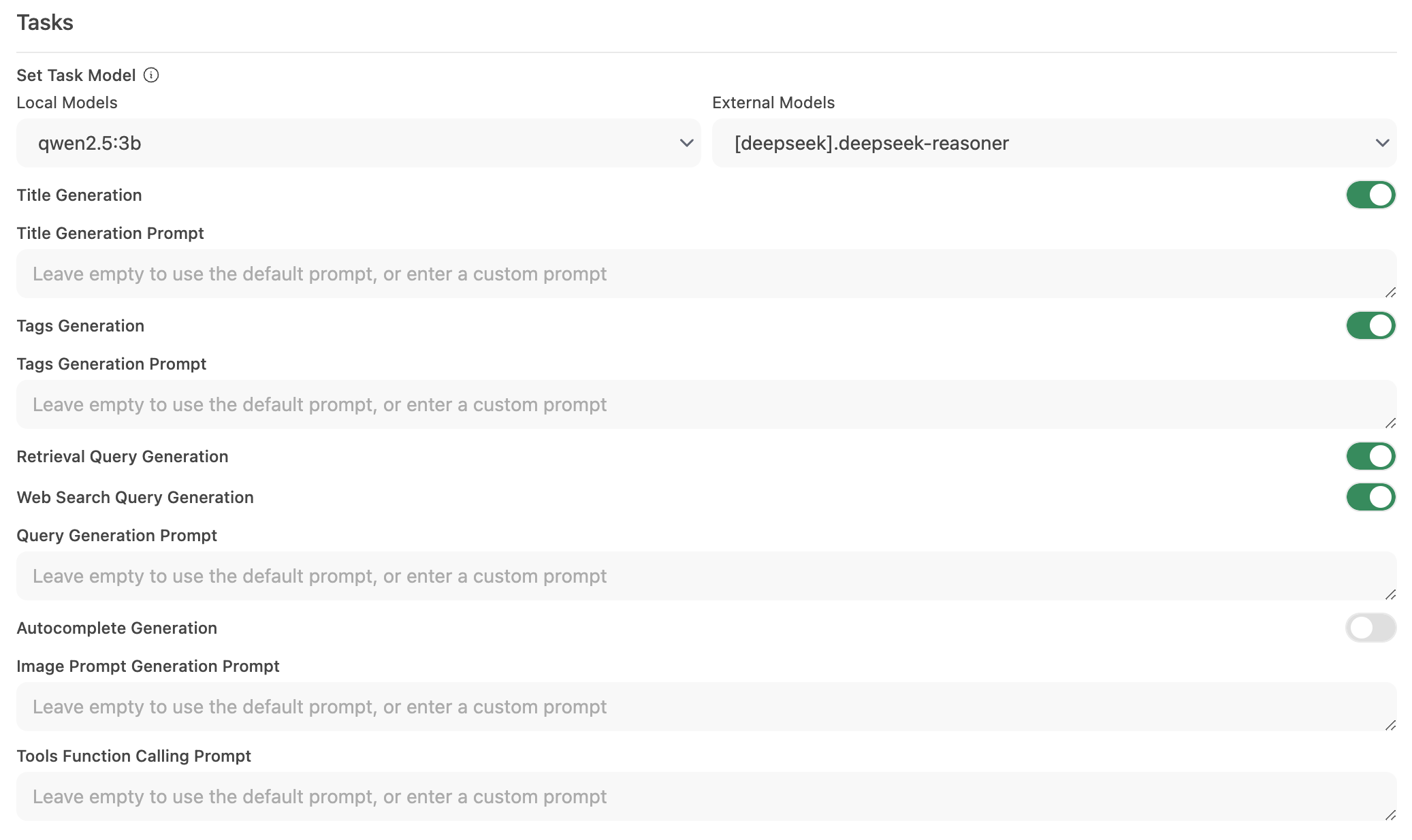
Étape 2 : Configurer le modèle de tâches
-
Allez dans Interface > Définir le modèle de tâches.
-
Choisissez l'une des options suivantes en fonction de vos besoins :
-
Modèle local léger (recommandé)
- Sélectionnez un modèle compact tel que Llama 3.2 3B ou Qwen2.5 3B.
- Ces modèles offrent des réponses rapides tout en consommant peu de ressources système.
-
Point de terminaison API hébergé (pour une vitesse maximale)
- Connectez-vous à un service API hébergé pour gérer le traitement des tâches.
- Cela peut être très économique. Par exemple, OpenRouter propose les modèles Llama et Qwen à moins de 1,5 cent par million de tokens d'entrée.
-
Désactiver les automatisations inutiles
- Si certaines fonctionnalités automatisées ne sont pas nécessaires, désactivez-les pour réduire les appels d'arrière-plan inutiles—surtout les fonctionnalités comme l'autocomplétion.
-
Étape 3 : Enregistrer vos modifications et tester
- Enregistrez la nouvelle configuration.
- Interagissez avec votre interface de chat et observez la réactivité.
- Si nécessaire, ajustez en désactivant davantage les fonctionnalités automatisées inutilisées, ou en expérimentant différents modèles de tâches.
🚀 Configuration recommandée pour les modèles locaux
| Stratégie d'optimisation | Avantage | Recommandé pour |
|---|---|---|
| Modèle local léger | Réduit l'utilisation des ressources | Systèmes avec matériel limité |
| Point de terminaison API hébergé | Offre les temps de réponse les plus rapides | Utilisateurs avec accès internet/API fiable |
| Désactiver les fonctionnalités automatisées | Maximise les performances en réduisant la charge | Ceux axés sur la fonctionnalité principale de chat |
Mettre en œuvre ces recommandations peut grandement améliorer la réactivité d'Open-WebUI tout en permettant à vos modèles locaux de gérer efficacement les interactions de chat.
💡 Conseils supplémentaires
- Surveillez les ressources système : Utilisez les outils de votre système d'exploitation (comme le Moniteur d'activité sur macOS ou le Gestionnaire des tâches sous Windows) pour surveiller l'utilisation des ressources.
- Réduisez les appels parallèles au modèle : Limiter les automatisations d'arrière-plan empêche les requêtes simultanées de surcharger votre LLM.
- Expérimentez les configurations : Testez différents modèles légers ou points de terminaison hébergés pour trouver un équilibre optimal entre vitesse et fonctionnalité.
- Restez à jour : Les mises à jour régulières d'Open-WebUI incluent souvent des améliorations de performances et des corrections de bugs, veillez donc à tenir votre logiciel à jour.
En appliquant ces modifications de configuration, vous soutiendrez une expérience Open-WebUI plus réactive et efficace, permettant à votre LLM local de se concentrer sur la fourniture d'interactions de chat de haute qualité sans délais inutiles.