専用タスクモデルでパフォーマンスを向上させる
Open-WebUIには、タイトル生成、タグ作成、自動補完、検索クエリ生成などの自動化機能があり、ユーザーエクスペリエンスを向上させます。しかし、これらの機能はローカルモデルに複数の同時リクエストを生成する可能性があり、リソースが限られているシステムではパフォーマンスに影響が出ることがあります。
このガイドでは、専用の軽量タスクモデルを構成する方法や自動化機能を選択的に無効化する方法を説明します。これにより、主なチャット機能が応答性と効率性を維持します。
[!TIP]
Open-WebUIが遅く感じる理由は?
デフォルトでは、Open-WebUIは以下��のようなバックグラウンドタスクを実行しており、魔法のように見せる一方でローカルリソースに負荷をかけることがあります:
- タイトル生成
- タグ生成
- 自動補完生成(この機能はキー入力のたびにトリガーされます)
- 検索クエリ生成
これらの各機能がモデルへの非同期リクエストを行います。例えば、自動補完機能の連続的な呼び出しは、32GBのRAMを搭載したMacで32B量子化モデルを実行しているようなデバイスで応答を大幅に遅らせる可能性があります。
タスクモデルを最適化することで、これらのバックグラウンドタスクを主なチャットアプリケーションから分離し、全体の応答性を向上させることができます。
⚡ タスクモデルのパフォーマンスを最適化する方法
効率的なタスクモデルを構成する手順を以下に示します:
ステップ1: 管理パネルにアクセスする
- ブラウザでOpen-WebUIを開きます。
- 管理パネルに移動します。
- サイドバーの設定をクリックします。
ステップ2: タスクモデルを構成する
-
インターフェース > タスクモデル設定に移動します。
-
ニーズに応じて以下のオプションを選択します:
-
軽量ローカルモデル(推奨)
- Llama 3.2 3B や Qwen2.5 3B といったコンパクトモデルを選択します。
- これらのモデルは迅速な応答を提供しながら、システムリソースの消費を最小限に抑えます。
-
ホストされたAPIエンドポイント(最大速度のため)
- タスク処理を扱うホストされたAPIサービスに接続します。
- これは非常に安価です。例えば、OpenRouterではLlamaおよびQwenモデルが100万インプットトークンあたり1.5セント以下で提供されています。
-
不要な自動化を無効化する
- 特定の自動化機能が必要ない場合、それらを無効化して余分なバックグラウンド呼び出しを削減します。特に自動補完機能など。
-
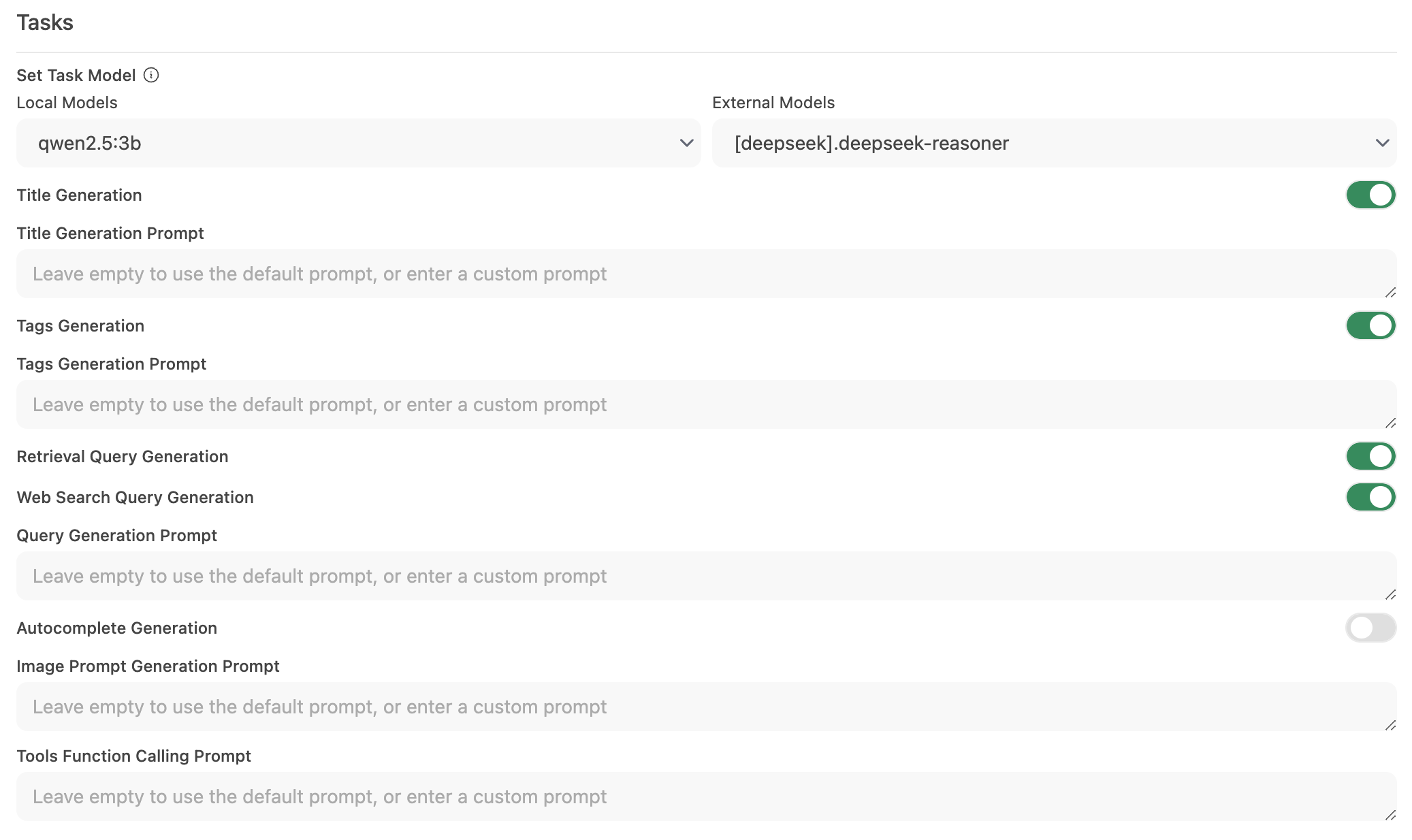
ステップ3: 変更を保存してテストする
- 新しい構成を保存します。
- チャットインターフェースを操作し、応答性を観察します。
- 必要に応じて、使用していない自動化機能をさらに無効化するか、異なるタスクモデルを試して調整します。
🚀 ローカルモデル用の推奨設定
| 最適化戦略 | 利点 | 推奨対象 |
|---|---|---|
| 軽量ローカルモデル | リソース使用量を最小化 | ハードウェアが制限されたシステム |
| ホストされたAPIエンドポイント | 最速の応答時間を提供 | 安定したインターネット/APIアクセスのあるユーザー |
| 自動化機能を無効化 | 負荷を軽減してパフォーマンスを最大化 | コアチャット機能に集中するユーザー |
これらの推奨事項を実施することで、Open-WebUIの応答性が大幅に向上し、ローカルモデルが効率的にチャットインタラクションを処理できるようになります。
💡 �追加のヒント
- システムリソースの監視: macOSのアクティビティモニタやWindowsのタスクマネージャーなど、OSのツールを使用してリソース使用状況を確認します。
- 並行モデル呼び出しの削減: バックグラウンド自動化を制限することでLLMの同時リクエストによる負荷を防ぎます。
- 構成の試行: 軽量モデルやホストエンドポイントを試して、速度と機能性の最適なバランスを見つけてください。
- 最新状態を維持: Open-WebUIの定期的なアップデートには、パフォーマンス改善やバグ修正が含まれるため、ソフトウェアを最新状態に保ちましょう。
これらの構成変更を適用することで、高品質のチャットインタラクションを提供しつつ、不必要な遅延を防ぎ、Open-WebUIの応答性と効率性を向上させることができます。