전용 작업 모델로 성능 개선하기
Open-WebUI는 제목 생성, 태그 생성, 자동완성 및 검색 쿼리 생성과 같은 여러 자동 기능을 제공하여 사용자 경험을 향상합니다. 하지만 이러한 기능은 로컬 모델에 동시에 여러 요청을 생성하여 제한된 리소스를 가진 시스템의 성능에 영향을 미칠 수 있습니다.
이 가이드는 전용 경량 작업 모델을 설정하거나 자동화 기능을 선택적으로 비활성화하여 설정을 최적화하는 방법을 설명합니다. 이를 통해 주요 채팅 기능이 응답적이고 효율적으로 유지될 수 있습니다.
[!TIP]
Open-WebUI가 느리게 느껴지는 이유는 무엇인가요?
기본적으로 Open-WebUI는 마치 마법처럼 보이는 여러 백그라운드 작업을 실행합니다. 하지만 이는 로컬 리소스에 큰 부담을 줄 수 있습니다:
- 제목 생성
- 태그 생성
- 자동완성 생성 (이 기능은 모든 키 입력 시 작동합니다)
- 검색 쿼리 생성
각 기능은 모델에 비동기 요청을 생성합니다. 예를 들어, 자동완성 기능에서 지속적인 호출은 제한된 메모리 또는 처리 능력을 가진 장치, 예를 들어 32GB RAM을 가진 Mac에서 32B 양자화 모델을 실행하는 경우 응답 지연을 유발할 수 있습니다.
작업 모델을 최적화하면 이러한 백그라운드 작업을 주요 채팅 애플리케이션에서 분리하여 전반적인 응답성을 개선할 수 있습니다.
⚡ 작업 모델 성능 최적화 방법
효율적인 작업 모델을 설정하려면 다음 단계를 따르세요:
Step 1: 관리 패널 접근
- 브라우저에서 Open-WebUI를 엽니다.
- 관리 패널로 이동합니다.
- 사이드바에서 설정을 클릭합니다.
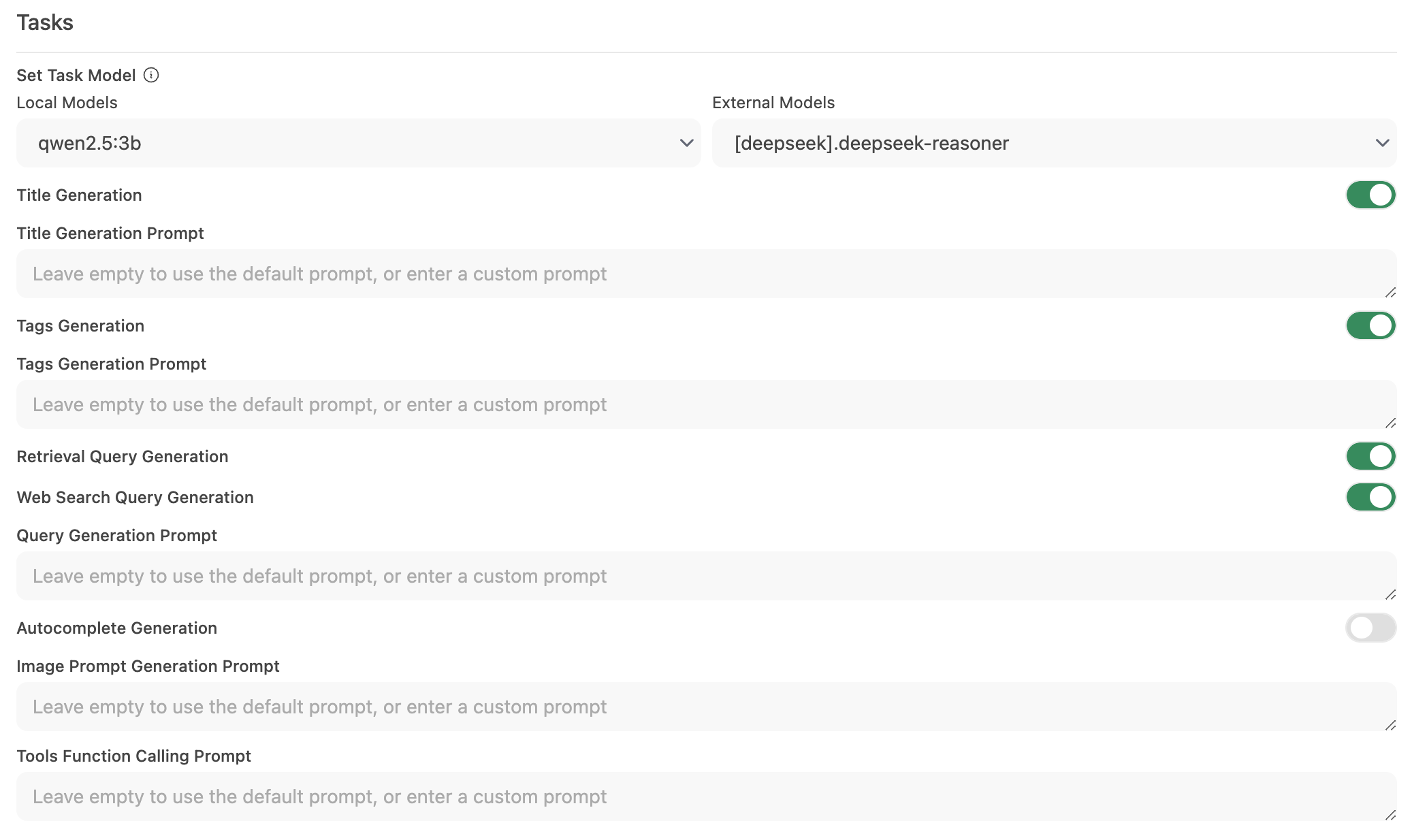
Step 2: 작업 모델 설정
-
인터페이스 > 작업 모델 설정으로 이동합니다.
-
필요에 따라 다음 옵션 중 하나를 선택합니다:
-
경량 로컬 모델 (추천)
- Llama 3.2 3B 또는 Qwen2.5 3B와 같은 컴팩트 모델을 선택합니다.
- 이 모델들은 신속한 응답을 제공하며 시스템 리소스를 적게 소비합니다.
-
호스팅 API 엔드포인트 (최대 속도용)
- 작업 처리를 위한 호스팅 API 서비스에 연결합니다.
- 비용이 매우 저렴할 수 있습니다. 예를 들어, OpenRouter는 1.5센트 미만의 백만 입력 토큰에 대해 Llama와 Qwen 모델을 제공합니다.
-
불필요한 자동화 비활성화
- 특정 자동 기능이 필요하지 않은 경우 이를 비활성화하여 불필요한 백그라운드 호출을 줄입니다. 특히 자동완성과 같은 기능.
-
Step 3: 변경사항 저장 및 테스트
- 새 구성을 저장합니다.
- 채팅 인터페이스와 상호작용하며 응답 속도를 관찰합니다.
- 필요 시 사용하지 않는 자동화 기능을 추가로 비활성화하거나 다른 작업 모델을 실험하여 조정합니다.
🚀 로컬 모델을 위한 추천 설정
| 최적화 전략 | 이점 | 추천 대상 |
|---|---|---|
| 경량 로컬 모델 | 리소스 사용 최소화 | 제한된 하드웨어를 가진 시스템 |
| 호스팅 API 엔드포인트 | 가장 빠른 응답 시간 제공 | 안정적인 인터넷/API 접근 가능한 사용자 |
| 자동화 기능 비활성화 | 부하를 줄여 성능 극대화 | 핵심 채팅 기능에 집중하는 사용자 |
이 추천 사항을 구현하면 Open-WebUI의 응답성을 크게 개선하고 로컬 모델이 채팅 상호작용을 효율적으로 처리할 수 있게 됩니다.
💡 추가 팁
- 시스템 리소스 모니터링: macOS의 활동 모니터 또는 Windows의 작업 관리자와 같은 운영 체제 툴을 사용하여 리소스 사용을 모니터링하세요.
- 병렬 모델 호출 감소: 백그라운드 자동화를 제한하여 LLM이 동시 요청에 압도당하는 것을 방지합니다.
- 구성 실험: 다양한 경량 모델 또는 호스팅 엔드포인트를 테스트하여 속도와 기능의 최적 균형을 찾으세요.
- 최신 상태 유지: Open-WebUI의 정기 업데이트는 성능 향상 및 버그 수정이 포함되는 경우가 많으므로 소프트웨어를 최신 상태로 유지하세요.
이 구성 변경을 적용하면 Open-WebUI 경험이 더 반응적이고 효율적으로 개선되어 로컬 LLM이 불필요한 지연 없이 고품질 채팅 상호작용 제공에 집중할 수 있습니다.