Mejora el Rendimiento con Modelos Dedicados para Tareas
Open-WebUI ofrece varias funciones automatizadas como generación de títulos, creación de etiquetas, autocompletar y generación de consultas de búsqueda, con el propósito de mejorar la experiencia del usuario. Sin embargo, estas funciones pueden generar múltiples solicitudes simultáneas a tu modelo local, lo que podría afectar el rendimiento en sistemas con recursos limitados.
Esta guía explica cómo optimizar tu configuración mediante la instalación de un modelo ligero dedicado para tareas o desactivando selectivamente funciones automáticas, asegurando que la funcionalidad principal del chat permanezca ágil y eficiente.
[!TIP]
¿Por qué Open-WebUI se siente lento?
Por defecto, Open-WebUI tiene varias tareas en segundo plano que pueden crear una experiencia casi mágica pero, al mismo tiempo, pueden imponer una carga significativa en los recursos locales:
- Generación de Títulos
- Generación de Etiquetas
- Generación de Autocompletado (esta función se activa con cada pulsación de tecla)
- Generación de Consultas de Búsqueda
Cada una de estas funciones realiza solicitudes asíncronas a tu modelo. Por ejemplo, las llamadas continuas de la función de autocompletado pueden retrasar significativamente las respuestas en dispositivos con poca memoria o capacidad de procesamiento, como una Mac con 32GB de RAM que ejecuta un modelo cuantizado de 32 bits.
Optimizar el modelo de tareas puede ayudar a aislar estas tareas de fondo de tu aplicación principal de chat, mejorando la capacidad de respuesta general.
⚡ Cómo Optimizar el Rendimiento del Modelo de Tareas
Sigue estos pasos para configurar un modelo de tareas eficiente:
Paso 1: Accede al Panel de Administración
- Abre Open-WebUI en tu navegador.
- Navega al Panel de Administración.
- Haz clic en Configuraciones en la barra lateral.
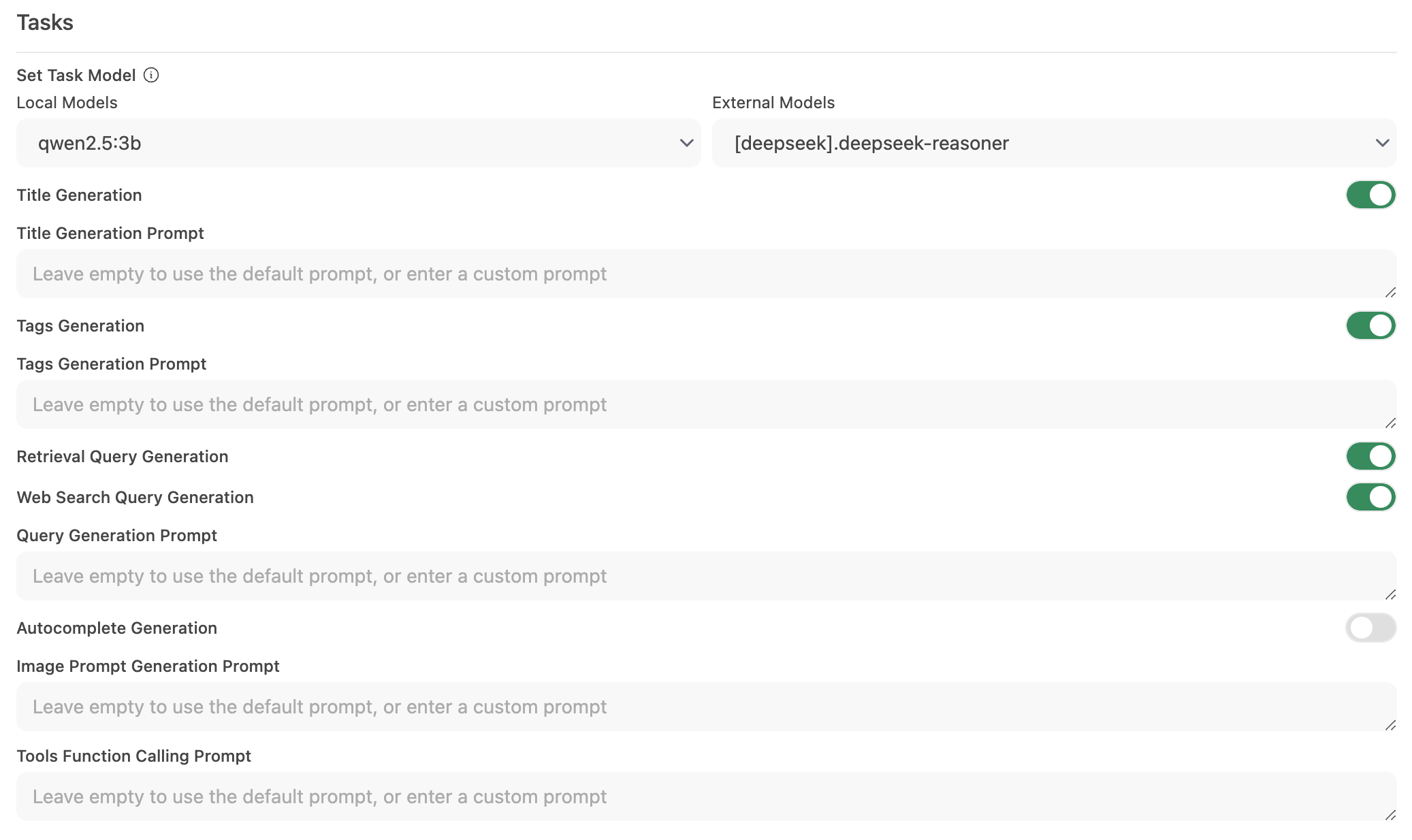
Paso 2: Configura el Modelo de Tareas
-
Ve a Interfaz > Configurar Modelo de Tareas.
-
Elige una de las siguientes opciones según tus necesidades:
-
Modelo Local Ligero (Recomendado)
- Selecciona un modelo compacto como Llama 3.2 3B o Qwen2.5 3B.
- Estos modelos ofrecen respuestas rápidas mientras consumen pocos recursos del sistema.
-
Endpoint de API Hospedada (Para Máxima Velocidad)
- Conéctate a un servicio de API hospedada para procesos de tareas.
- Esto puede ser muy económico. Por ejemplo, OpenRouter ofrece modelos Llama y Qwen por menos de 1.5 centavos por millón de tokens de entrada.
-
Desactivar Automatización Innecesaria
- Si no necesitas ciertas funciones automatizadas, desactívalas para reducir las llamadas de fondo innecesarias, especialmente funciones como autocompletado.
-
Paso 3: Guarda los Cambios y Prueba
- Guarda la nueva configuración.
- Interactúa con la interfaz de chat y observa la capacidad de respuesta.
- Si es necesario, ajusta desactivando más funciones automatizadas o experimenta con diferentes modelos de tareas.
🚀 Configuración Recomendada para Modelos Locales
| Estrategia de Optimización | Beneficio | Recomendado Para |
|---|---|---|
| Modelo Local Ligero | Minimiza el uso de recursos | Sistemas con hardware limitado |
| Endpoint de API Hospedada | Ofrece los tiempos de respuesta más rápidos | Usuarios con acceso fiable a internet/API |
| Desactivar Funciones de Automatización | Maximiza rendimiento reduciendo la carga | Aquellos enfocados en funcionalidad principal del chat |
Implementar estas recomendaciones puede mejorar significativamente la capacidad de respuesta de Open-WebUI, permitiendo que tus modelos locales manejen interacciones de chat de manera eficiente.
💡 Consejos Adicionales
- Monitorea los Recursos del Sistema: Utiliza las herramientas de tu sistema operativo (como Monitor de Actividad en macOS o Administrador de Tareas en Windows) para vigilar el consumo de recursos.
- Reduce las Llamadas Paralelas al Modelo: Limitar la automatización de fondo evita que solicitudes simultáneas saturen tu LLM.
- Experimenta con Configuraciones: Prueba distintos modelos ligeros u endpoints hospedados para encontrar el equilibrio óptimo entre velocidad y funcionalidad.
- Mantente Actualizado: Las actualizaciones regulares de Open-WebUI suelen incluir mejoras de rendimiento y corrección de errores, por lo que es importante mantener tu software al día.
Aplicando estos cambios de configuración, tendrás una experiencia Open-WebUI más receptiva y eficiente, permitiendo que tu LLM local se enfoque en ofrecer interacciones de chat de alta calidad sin retrasos innecesarios.