Este tutorial es una contribución de la comunidad y no está respaldado por el equipo de Open WebUI. Sirve únicamente como una demostración sobre cómo personalizar Open WebUI para tu caso de uso específico. ¿Quieres contribuir? Consulta el tutorial de contribuciones.
🎨 Generación de Imágenes
Open WebUI admite la generación de imágenes a través de tres backends: AUTOMATIC1111, ComfyUI y OpenAI DALL·E. Esta guía te ayudará a configurar y utilizar cualquiera de estas opciones.
AUTOMATIC1111
Open WebUI soporta la generación de imágenes mediante la API de AUTOMATIC1111. Aquí están los pasos para comenzar:
Configuración Inicial
-
Asegúrate de tener AUTOMATIC1111 instalado.
-
Inicia AUTOMATIC1111 con las banderas adicionales para habilitar el acceso a la API:
./webui.sh --api --listen -
Para la instalación en Docker de WebUI con las variables de entorno ya configuradas, utiliza el siguiente comando:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -e AUTOMATIC1111_BASE_URL=http://host.docker.internal:7860/ -e ENABLE_IMAGE_GENERATION=True -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Configuración de Open WebUI con AUTOMATIC1111
-
En Open WebUI, navega al menú de Panel de Admin > Configuraciones > Imágenes.
-
Configura el campo
Motor de Generación de ImágenesaDefault (Automatic1111). -
En el campo de URL de la API, ingresa la dirección donde la API de AUTOMATIC1111 está accesible:
http://<tu_dirección_automatic1111>:7860/Si estás ejecutando una instalación Docker de Open WebUI y AUTOMATIC1111 en el mismo host, utiliza
http://host.docker.internal:7860/como tu dirección.
ComfyUI
ComfyUI proporciona una interfaz alternativa para gestionar e interactuar con modelos de generación de imágenes. Aprende más o descárgalo desde su página GitHub. A continuación, las instrucciones para configurar ComfyUI junto a tus otras herramientas.
Configuración Inicial
-
Descarga y extrae el paquete de software ComfyUI desde GitHub en tu directorio deseado.
-
Para iniciar ComfyUI, ejecuta el siguiente comando:
python main.pyPara sistemas con baja memoria VRAM, inicia ComfyUI con banderas adicionales para reducir el uso de memoria:
python main.py --lowvram -
Para la instalación en Docker de WebUI con las variables de entorno configuradas, utiliza el siguiente comando:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -e COMFYUI_BASE_URL=http://host.docker.internal:7860/ -e ENABLE_IMAGE_GENERATION=True -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Configuración de Open WebUI con ComfyUI
Configuración de Modelos FLUX.1
- Checkpoints de Modelo:
- Descarga el modelo
FLUX.1-schnelloFLUX.1-devdesde la página HuggingFace de black-forest-labs. - Coloca el(los) checkpoint(s) del modelo en los directorios
models/checkpointsymodels/unetde ComfyUI. Alternativamente, puedes crear un enlace simbólico entremodels/checkpointsymodels/unetpara asegurarte de que ambos directorios contengan los mismos checkpoints del modelo.
- Modelo VAE:
- Descarga el VAE
ae.safetensorsdesde aquí. - Colócalo en el directorio
models/vaede ComfyUI.
- Modelo CLIP:
- Descarga
clip_l.safetensorsdesde aquí. - Colócalo en el directorio
models/clipde ComfyUI.
- Modelo T5XXL:
- Descarga el modelo
t5xxl_fp16.safetensorsot5xxl_fp8_e4m3fn.safetensorsdesde aquí. - Colócalo en el directorio
models/clipde ComfyUI.
Para integrar ComfyUI en Open WebUI, sigue estos pasos:
Paso 1: Configura las Opciones de Open WebUI
- Navega al Panel de Admin en Open WebUI.
- Haz clic en Configuraciones y luego selecciona la pestaña Imágenes.
- En el campo
Motor de Generación de Imágenes, eligeComfyUI. - En el campo URL de la API, ingresa la dirección donde la API de ComfyUI está accesible, siguiendo este formato:
http://<tu_dirección_comfyui>:8188/.- Configura la variable de entorno
COMFYUI_BASE_URLa esta dirección para asegurarte de que persista dentro del WebUI.
- Configura la variable de entorno
Paso 2: Verifica la Conexión y Habilita la Generación de Imágenes
- Asegúrate de que ComfyUI esté ejecutándose y que hayas verificado exitosamente la conexión con Open WebUI. No podrás continuar sin una conexión exitosa.
- Una vez que la conexión esté verificada, activa Generación de Imágenes (Experimental). Se te presentarán más opciones.
- Continúa con el paso 3 para los pasos finales de configuración.
Paso 3: Configurar los ajustes de ComfyUI e importar el flujo de trabajo
- Activa el modo desarrollador dentro de ComfyUI. Para hacerlo, busca el ícono de engranaje sobre el botón Queue Prompt dentro de ComfyUI y activa la opción
Dev Mode. - Exporta el flujo de trabajo deseado desde ComfyUI en formato
API formatutilizando el botónSave (API Format). El archivo se descargará comoworkflow_api.jsonsi se realiza correctamente. - Regresa a Open WebUI y haz clic en el botón Click here to upload a workflow.json file.
- Selecciona el archivo
workflow_api.jsonpara importar el flujo de trabajo exportado de ComfyUI a Open WebUI. - Después de importar el flujo de trabajo, debes mapear los
ComfyUI Workflow Nodesde acuerdo con los IDs de nodos importados en el flujo de trabajo. - Configura
Set Default Modelcon el nombre del archivo del modelo que se está utilizando, comoflux1-dev.safetensors.
Es posible que necesites ajustar una Input Key o dos en la sección ComfyUI Workflow Nodes de Open WebUI para que coincidan con un nodo dentro de tu flujo de trabajo.
Por ejemplo, seed puede necesitar ser renombrado a noise_seed para coincidir con un ID de nodo en tu flujo de trabajo importado.
Algunos flujos de trabajo, como aquellos que utilizan cualquier modelo Flux, pueden requerir múltiples IDs de nodos que son necesarios para llenar sus campos de entrada de nodos dentro de Open WebUI. Si un campo de entrada de nodo necesita múltiples IDs, los IDs de nodos deben estar separados por comas (ejemplo: 1 o 1, 2).
- Haz clic en
Savepara aplicar los ajustes y disfruta de la generación de imágenes con ComfyUI integrado en Open WebUI.
Después de completar estos pasos, tu configuración de ComfyUI debería estar integrada con Open WebUI, y podrás usar los modelos Flux.1 para la generación de imágenes.
Configuración con SwarmUI
SwarmUI utiliza ComfyUI como su backend. Para lograr que Open WebUI funcione con SwarmUI, deberás añadir ComfyBackendDirect a la ComfyUI Base URL. Además, querrás configurar SwarmUI con acceso a la LAN. Después de los ajustes mencionados, configurar SwarmUI para trabajar con Open WebUI será igual que Paso uno: Configurar ajustes de Open WebUI como se detalla arriba.
URL de API de SwarmUI
La dirección que introducirás como ComfyUI Base URL será algo como: http://<your_swarmui_address>:7801/ComfyBackendDirect
OpenAI DALL·E
Open WebUI también soporta la generación de imágenes a través de las APIs de OpenAI DALL·E. Esta opción incluye un selector para elegir entre DALL·E 2 y DALL·E 3, cada uno soporta diferentes tamaños de imágenes.
Configuración Inicial
- Obtén una clave de API de OpenAI.
Configurando Open WebUI
- En Open WebUI, navega al menú Admin Panel > Settings > Images.
- Configura el campo
Image Generation EngineaOpen AI (Dall-E). - Ingresa tu clave de API de OpenAI.
- Elige el modelo de DALL·E que deseas utilizar. Ten en cuenta que las opciones de tamaño de imagen dependerán del modelo seleccionado:
- DALL·E 2: Soporta imágenes de
256x256,512x512o1024x1024. - DALL·E 3: Soporta imágenes de
1024x1024,1792x1024o1024x1792.
- DALL·E 2: Soporta imágenes de
Azure OpenAI
Usar Azure OpenAI DALL-E directamente no está soportado, pero puedes configurar un proxy LiteLLM que es compatible con el motor de generación de imágenes Open AI (Dall-E).
Usando la Generación de Imágenes
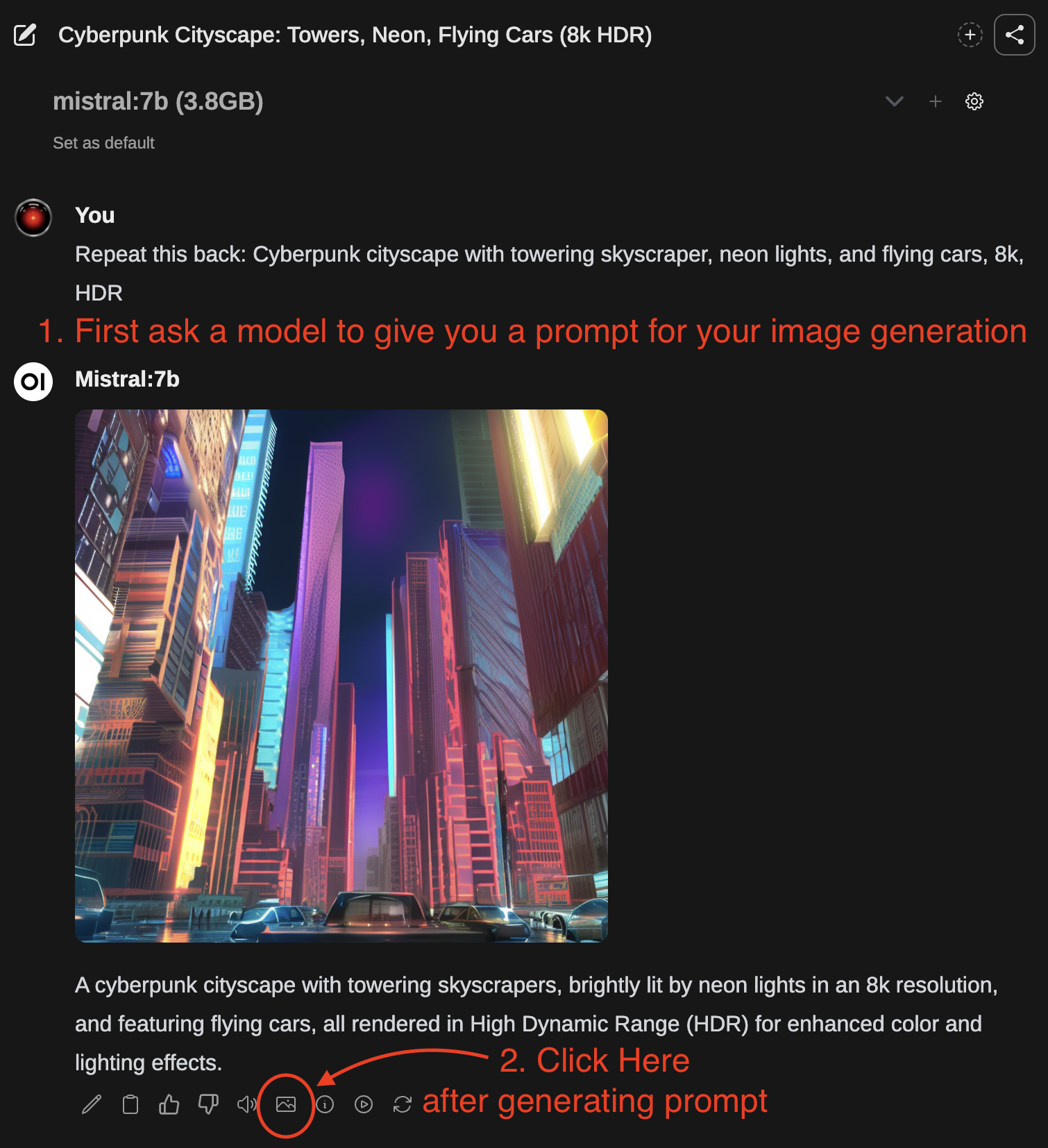
- Primero, utiliza un modelo de generación de texto para redactar un prompt para la generación de imágenes.
- Una vez finalizada la respuesta, puedes hacer clic en el ícono de imagen para generar una imagen.
- Después de que la imagen haya terminado de generarse, será devuelta automáticamente en el chat.
También puedes editar la respuesta del LLM y escribir tu prompt de generación de imágenes como el mensaje para enviarlo para la generación de imágenes en lugar de usar la respuesta proporcionada por el LLM.