本教程由社群貢獻,並未由 Open WebUI 團隊支援。此教程僅用於演示如何為特定用例自訂 Open WebUI。想要貢獻?請查看貢獻教程。
🎨 圖像生成
Open WebUI 支援通過三種後端生成圖像:AUTOMATIC1111、ComfyUI 和 OpenAI DALL·E。本指南將幫助您設置並使用其中的任一選項。
AUTOMATIC1111
Open WebUI 支援通過 AUTOMATIC1111 API 生成圖像。以下是入門的步驟:
初始設置
-
確保您已安裝 AUTOMATIC1111。
-
使用額外的標誌啟動 AUTOMATIC1111 以啟用 API 訪問:
./webui.sh --api --listen -
如果使用 Docker 安裝並預設了環境變數,使用以下命令:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -e AUTOMATIC1111_BASE_URL=http://host.docker.internal:7860/ -e ENABLE_IMAGE_GENERATION=True -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
在 Open WebUI 中設置 AUTOMATIC1111
-
在 Open WebUI 中,導航到 管理面板 > 設置 > 圖像 菜單。
-
將
圖像生成引擎欄位設置為預設 (Automatic1111)。 -
在 API URL 欄位中輸入 AUTOMATIC1111 API 的可訪問地址:
http://<your_automatic1111_address>:7860/如果您在同一主機上運行 Docker 安裝的 Open WebUI 和 AUTOMATIC1111,請使用
http://host.docker.internal:7860/作為地址。
ComfyUI
ComfyUI 提供了一種替代界面,用於管理和與圖像生成模型交互。更多內容或下載可參考其 GitHub 頁面。以下是與其他工具一同運行 ComfyUI 的設置說明。
初始設置
-
從 GitHub 下載並解壓 ComfyUI 軟體包至所需目錄。
-
運行以下命令啟動 ComfyUI:
python main.py對於低 VRAM 系統,用額外的標誌啟動 ComfyUI 以減少記憶體使用:
python main.py --lowvram -
如果使用 Docker 安裝並預設了環境變數,使用以下命令:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -e COMFYUI_BASE_URL=http://host.docker.internal:7860/ -e ENABLE_IMAGE_GENERATION=True -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
在 Open WebUI 中設置 ComfyUI
設置 FLUX.1 模型
- 模型檢查點:
- 從 black-forest-labs HuggingFace 頁面 下載
FLUX.1-schnell或FLUX.1-dev模型。 - 將模型檢查點放置在 ComfyUI 的
models/checkpoints和models/unet目錄下。或者,您可以在models/checkpoints和models/unet之間創建符號鏈接,以確保兩個目錄都包含相同的模型檢查點。
- VAE 模型:
- 從 此處 下載
ae.safetensorsVAE。 - 將其放置在 ComfyUI 的
models/vae目錄下。
- CLIP 模型:
- 從 此處 下載
clip_l.safetensors。 - 將其放置在 ComfyUI 的
models/clip目錄下。
- T5XXL 模型:
- 從 此處 下載
t5xxl_fp16.safetensors或t5xxl_fp8_e4m3fn.safetensors模型。 - 將其放置在 ComfyUI 的
models/clip目錄下。
要將 ComfyUI 集成到 Open WebUI,請按照以下步驟:
第一步:配置 Open WebUI 設置
- 導航到 Open WebUI 中的 管理面板。
- 點擊 設置,然後選擇 圖像 標籤。
- 在
圖像生成引擎欄位中,選擇ComfyUI。 - 在 API URL 欄位中,輸入 ComfyUI API 的可訪問地址,格式如下:
http://<your_comfyui_address>:8188/。- 設置環境變數
COMFYUI_BASE_URL為此地址,以確保其在 WebUI 中持久化。
- 設置環境變數
第二步:驗證連接並啟用圖像生成
- 確保 ComfyUI 正在運行,並且您已成功驗證與 Open WebUI 的連接。在成功連接之前,您將無法繼續。
- 一旦連接驗證成功,切換開啟 圖像生成 (實驗性)。您將看到更多選項。
- 繼續進行步驟3完成最終設定步驟。
步驟3:設定 ComfyUI 設定並匯入工作流程
- 在 ComfyUI 中啟用開發者模式。要執行此操作,請找到 ComfyUI 中 Queue Prompt 按鈕上方的齒輪圖示,並啟用
Dev Mode切換。 - 使用
Save (API Format)按鈕以API 格式從 ComfyUI 匯出所需工作流程。正確執行的話,檔案將下載為workflow_api.json。 - 返回 Open WebUI 並點擊 點擊這裡上傳 workflow.json 文件 按鈕。
- 選擇
workflow_api.json檔案以將從 ComfyUI 匯出的工作流程導入至 Open WebUI。 - 導入工作流程後,您需要根據導入的工作流程節點 ID 映射
ComfyUI Workflow Nodes。 - 將
Set Default Model設置為所使用模型檔案的名稱,例如flux1-dev.safetensors。
您可能需要在 Open WebUI 的 ComfyUI Workflow Nodes 區域內調整一或兩個 Input Key 以匹配您工作流程中的某個節點。
例如,seed 可能需要重命名為 noise_seed 以匹配您導入工作流程中的節點 ID。
某些工作流程,例如使用任何 Flux 模型的工作流程,可能會使用多個節點 ID 作為其節點輸入字段所需的內容。在 Open WebUI 中輸入多個節點 ID 時,節點 ID 應以逗號分隔(例如:1 或 1, 2)。
- 點擊
Save以應用設定,並享受將 ComfyUI 結合至 Open WebUI 後的影像生成功能!
完成這些步驟後,您的 ComfyUI 應該已經與 Open WebUI 結合,並能使用 Flux.1 模型進行影像生成。
與 SwarmUI 設定
SwarmUI 使用 ComfyUI 作為其後端。要讓 Open WebUI 與 SwarmUI 一起運作,您需要在 ComfyUI Base URL 中添加 ComfyBackendDirect,並設定 SwarmUI 的局域網 (LAN) 訪問功能。在完成上述調整後,將 SwarmUI 與 Open WebUI 配置的方法與 步驟1:配置 Open WebUI 設定 相同。
SwarmUI API URL
您輸入作為 ComfyUI Base URL 的地址將如下所示:http://<your_swarmui_address>:7801/ComfyBackendDirect
OpenAI DALL·E
Open WebUI 也支援通過 OpenAI DALL·E APIs 進行影像生成。此選項包括��一個選擇器,允許在 DALL·E 2 和 DALL·E 3 之間切換,每種模型支援不同的影像大小。
初始設定
- 從 OpenAI 獲取一個 API 金鑰。
配置 Open WebUI
- 在 Open WebUI 中,導航至 Admin Panel > Settings > Images 菜單。
- 將
Image Generation Engine字段設置為Open AI (Dall-E)。 - 輸入您的 OpenAI API 金鑰。
- 選擇您希望使用的 DALL·E 模型。請注意,影像大小選項將取決於所選模型:
- DALL·E 2:支援
256x256、512x512或1024x1024影像。 - DALL·E 3:支援
1024x1024、1792x1024或1024x1792影像。
- DALL·E 2:支援
Azure OpenAI
直接使用 Azure OpenAI Dall-E 未被支援,但您可以 設置 LiteLLM 代理,此代理與 Open AI (Dall-E) 影像生成引擎兼容。
使用影像生成
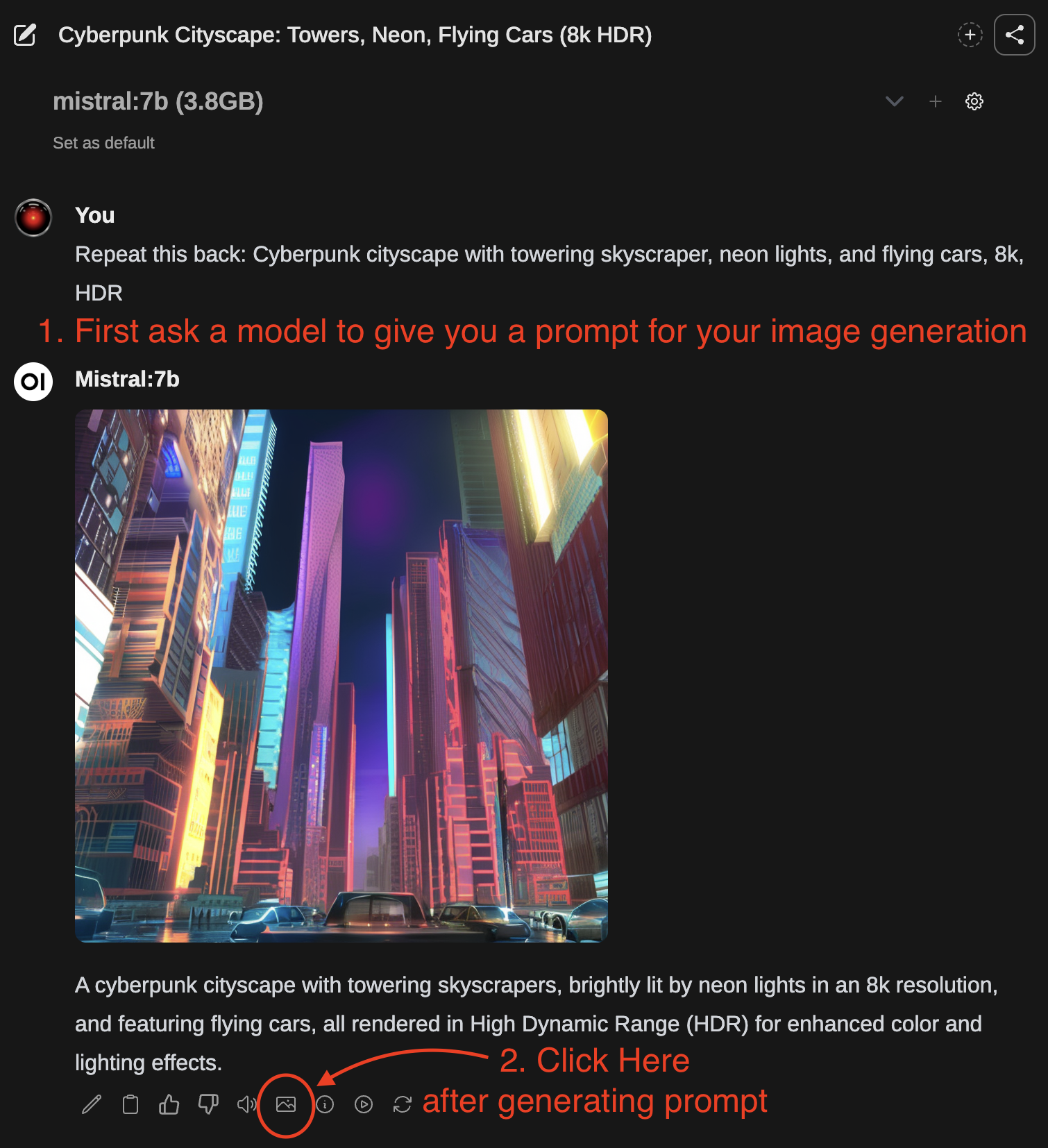
- 首先,使用文本生成模型撰寫一段影像生成提示詞。
- 當響應完成後,您可以點擊圖片圖示生成影像。
- 影像生成完成後,它將自動返回至聊天中。
您也可以編輯 LLM 的回應,將影像生成提示詞作為訊息輸入, 以生成影像,而不是使用 LLM 提供的實際回應。