Verbesserung der Leistung mit dedizierten Aufgabenmodellen
Open-WebUI stellt mehrere automatisierte Funktionen bereit – wie die Generierung von Titeln, die Erstellung von Tags, die Autovervollständigung und die Generierung von Suchanfragen, um das Benutzererlebnis zu verbessern. Allerdings können diese Funktionen mehrere gleichzeitige Anfragen an Ihr lokales Modell auslösen, was die Leistung auf Systemen mit begrenzten Ressourcen beeinträchtigen könnte.
Dieser Leitfaden erklärt, wie Sie Ihre Einrichtung optimieren, indem Sie ein dediziertes, leichtgewichtiges Aufgabenmodell konfigurieren oder automatisierte Funktionen gezielt deaktivieren, um sicherzustellen, dass Ihre Haupt-Chat-Funktionalität reaktionsschnell und effizient bleibt.
[!TIPP]
Warum fühlt sich Open-WebUI langsam an?
Standardmäßig hat Open-WebUI mehrere Hintergrundaufgaben, die wie Magie wirken können, aber auch eine hohe Belastung für lokale Ressourcen darstellen können:
- Titelerstellung
- Tag-Erstellung
- Autovervollständigung (Diese Funktion wird bei jedem Tastendruck ausgelöst)
- Suchanfragenerstellung
Jede dieser Funktionen führt asynchrone Anfragen an Ihr Modell aus. Beispielsweise können kontinuierliche Anrufe der Autovervollständigungsfunktion die Antworten auf Geräten mit begrenztem Arbeitsspeicher oder Rechenleistung erheblich verzögern, wie einem Mac mit 32 GB RAM, der ein 32B quantisiertes Modell ausführt.
Die Optimierung des Aufgabenmodells kann helfen, diese Hintergrundaufgaben von Ihrer Haupt-Chat-Anwendung zu isolieren und somit die Gesamtreaktionsfähigkeit zu verbessern.
⚡ Wie man die Leistung des Aufgabenmodells optimiert
Folgen Sie diesen Schritten, um ein effizientes Aufgabenmodell zu konfigurieren:
Schritt 1: Zugriff auf das Admin-Panel
- Öffnen Sie Open-WebUI in Ihrem Browser.
- Navigieren Sie zum Admin-Panel.
- Klicken Sie auf Einstellungen in der Seitenleiste.
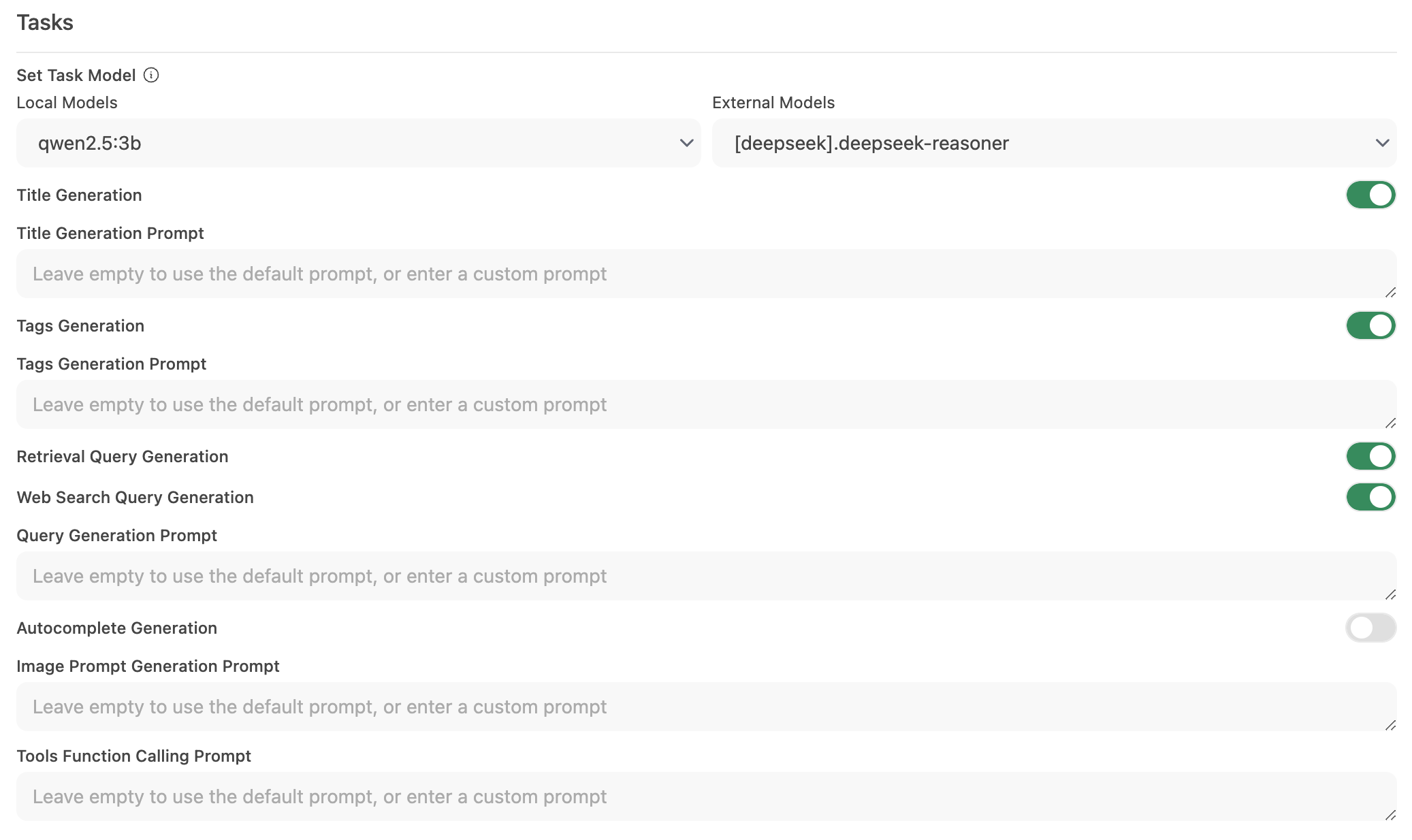
Schritt 2: Konfigurieren Sie das Aufgabenmodell
-
Gehen Sie zu Interface > Aufgabenmodell festlegen.
-
Wählen Sie eine der folgenden Optionen basierend auf Ihren Bedürfnissen:
-
Leichtgewichtiges lokales Modell (empfohlen)
- Wählen Sie ein kompaktes Modell wie Llama 3.2 3B oder Qwen2.5 3B.
- Diese Modelle bieten schnelle Antworten bei minimalem Ressourcenverbrauch.
-
Gehosteter API-Endpunkt (für maximale Geschwindigkeit)
- Verbinden Sie sich mit einem gehosteten API-Dienst, um die Aufgabenbearbeitung zu übernehmen.
- Dies kann sehr kostengünstig sein. Zum Beispiel bietet OpenRouter Llama- und Qwen-Modelle für weniger als 1,5 Cent pro Million Eingangstoken an.
-
Deaktivieren unnötiger Automatisierung
- Wenn bestimmte automatisierte Funktionen nicht benötigt werden, deaktivieren Sie diese, um überflüssige Hintergrundanfragen – insbesondere Funktionen wie Autovervollständigung – zu reduzieren.
-
Schritt 3: Änderungen speichern und testen
- Speichern Sie die neue Konfiguration.
- Interagieren Sie mit Ihrer Chat-Oberfläche und beobachten Sie die Reaktionsfähigkeit.
- Falls erforderlich, passen Sie die Einstellungen weiter an, indem Sie ungenutzte Automatisierungsfunktionen deaktivieren oder mit anderen Aufgabenmodellen experimentieren.
🚀 Empfohlene Einrichtung für lokale Modelle
| Optimierungsstrategie | Vorteil | Empfohlen für |
|---|---|---|
| Leichtgewichtiges lokales Modell | Minimiert Ressourcenverbrauch | Systeme mit begrenzter Hardware |
| Gehosteter API-Endpunkt | Bietet die schnellsten Antwortzeiten | Benutzer mit zuverlässigem Internet-API-Zugriff |
| Automatisierungsfunktionen deaktivieren | Maximiert die Leistung durch Reduzierung der Belastung | Benutzer, die sich auf die Kern-Chat-Funktionalität konzentrieren |
Die Implementierung dieser Empfehlungen kann die Reaktionsfähigkeit von Open-WebUI erheblich verbessern, während Ihre lokalen Modelle effizient Chat-Interaktionen verarbeiten können.
💡 Zusätzliche Tipps
- Systemressourcen überwachen: Verwenden Sie die Tools Ihres Betriebssystems (wie Aktivitätsmonitor auf macOS oder Task-Manager auf Windows), um die Ressourcennutzung im Auge zu behalten.
- Parallele Modellaufrufe reduzieren: Begrenzt Hintergrundautomatisierung, um zu verhindern, dass gleichzeitige Anfragen Ihr LLM überfordern.
- Mit Konfigurationen experimentieren: Testen Sie verschiedene leichte Modelle oder gehostete Endpunkte, um die optimale Balance zwischen Geschwindigkeit und Funktionalität zu finden.
- Aktuell bleiben: Regelmäßige Updates für Open-WebUI enthalten oft Leistungsverbesserungen und Fehlerbehebungen – halten Sie Ihre Software auf dem neuesten Stand.
Durch die Anwendung dieser Konfigurationsänderungen unterstützen Sie eine reaktionsschnellere und effizientere Open-WebUI-Erfahrung, sodass Ihr lokales LLM sich auf qualitativ hochwertige Chat-Interaktionen konzentrieren kann, ohne unnötige Verzögerungen.