Melhorar o Desempenho com Modelos de Tarefa Dedicados
Open-WebUI oferece vários recursos automatizados—como geração de título, criação de tags, autocompletar e geração de consultas de pesquisa—para melhorar a experiência do usuário. No entanto, esses recursos podem gerar múltiplas solicitações simultâneas ao seu modelo local, o que pode impactar o desempenho em sistemas com recursos limitados.
Este guia explica como otimizar sua configuração configurando um modelo de tarefa dedicado e leve ou desativando seletivamente os recursos de automação, garantindo que sua funcionalidade principal de chat permaneça responsiva e eficiente.
[!TIP]
Por que o Open-WebUI Parece Lento?
Por padrão, o Open-WebUI possui várias tarefas em segundo plano que podem fazer com que pareça mágica, mas também podem sobrecarregar os recursos locais:
- Geração de Título
- Geração de Tags
- Geração de Autocompletar (esta função é acionada a cada tecla pressionada)
- Geração de Consulta de Pesquisa
Cada um desses recursos faz solicitações assíncronas ao seu modelo. Por exemplo, chamadas contínuas da função de autocompletar podem atrasar significativamente as respostas em dispositivos com memória limitada ou poder de processamento, como um Mac com 32GB de RAM executando um modelo quantizado de 32B.
Otimizar o modelo de tarefa pode ajudar a isolar essas tarefas em segundo plano de sua aplicação principal de chat, melhorando a responsividade geral.
⚡ Como Otimizar o Desempenho do Modelo de Tarefa
Siga estes passos para configurar um modelo de tarefa eficiente:
Passo 1: Acesse o Painel de Administração
- Abra o Open-WebUI no seu navegador.
- Navegue até o Painel de Administração.
- Clique em Configurações na barra lateral.
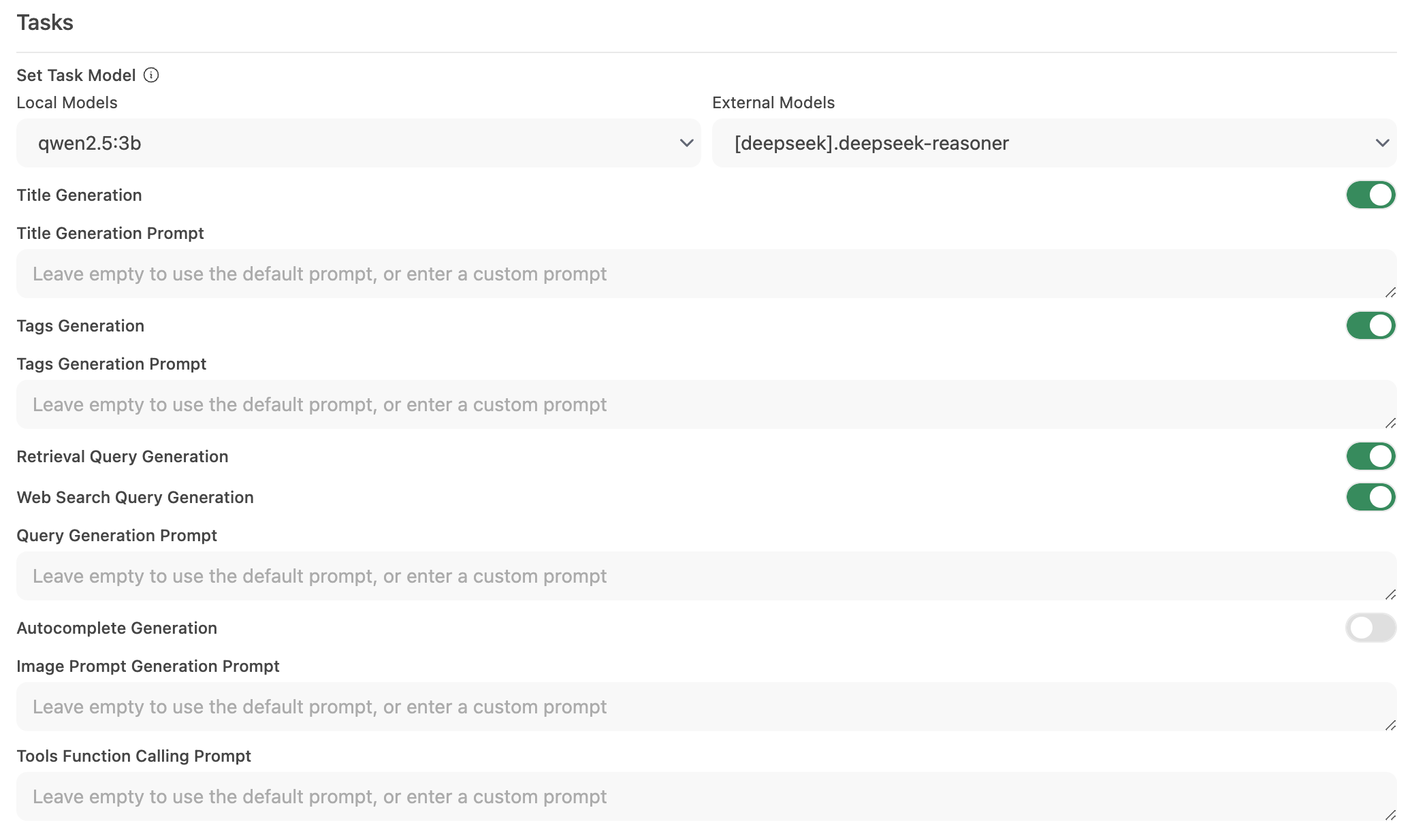
Passo 2: Configure o Modelo de Tarefa
-
Vá para Interface > Definir Modelo de Tarefa.
-
Escolha uma das seguintes opções com base nas suas necessidades:
-
Modelo Local Leve (Recomendado)
- Selecione um modelo compacto como Llama 3.2 3B ou Qwen2.5 3B.
- Esses modelos oferecem respostas rápidas enquanto consomem poucos recursos do sistema.
-
Ponto de Extremidade de API Hospedado (Para Máxima Velocidade)
- Conecte-se a um serviço de API hospedado para lidar com o processamento de tarefas.
- Isso pode ser muito barato. Por exemplo, o OpenRouter oferece modelos Llama e Qwen por menos de 1,5 centavos por milhão de tokens de entrada.
-
Desativar Automação Desnecessária
- Se certos recursos automatizados não forem necessários, desative-os para reduzir chamadas adicionais em segundo plano—especialmente recursos como autocompletar.
-
Passo 3: Salve As Alterações e Teste
- Salve a nova configuração.
- Interaja com sua interface de chat e observe a responsividade.
- Se necessário, ajuste desativando mais recursos de automação não utilizados ou experimentando diferentes modelos de tarefa.
🚀 Configuração Recomendada para Modelos Locais
| Estratégia de Otimização | Benefício | Recomendado Para |
|---|---|---|
| Modelo Local Leve | Minimiza o uso de recursos | Sistemas com hardware limitado |
| Ponto de Extremidade de API | Oferece os tempos de resposta mais rápidos | Usuários com acesso à internet/API confiável |
| Desativar Recursos Automáticos | Maximiza o desempenho ao reduzir a carga | Aqueles focados na funcionalidade principal de chat |
Implementar essas recomendações pode melhorar significativamente a responsividade do Open-WebUI enquanto permite que seus modelos locais lidem eficientemente com interações de chat.
💡 Dicas Adicionais
- Monitorar Recursos do Sistema: Use as ferramentas do sistema operacional (como o Monitor de Atividade no macOS ou o Gerenciador de Tarefas no Windows) para observar o uso dos recursos.
- Reduzir Chamadas Paralelas ao Modelo: Limitar automação em segundo plano evita que solicitações simultâneas sobrecarreguem seu LLM.
- Experimentar Configurações: Teste diferentes modelos leves ou pontos de extremidade hospedados para encontrar o equilíbrio ideal entre velocidade e funcionalidade.
- Manter Atualizado: Atualizações regulares do Open-WebUI frequentemente incluem melhorias de desempenho e correções de bugs, então mantenha seu software atualizado.
Ao aplicar essas mudanças de configuração, você dará suporte a uma experiência Open-WebUI mais responsiva e eficiente, permitindo que seu LLM local se concentre em entregar interações de chat de alta qualidade sem atrasos desnecessários.