🐋 Llama.cppでDeepSeek R1 Dynamic 1.58-bitを実行
UnslothAIに大感謝!彼らの素晴らしい努力のおかげで、Llama.cppで完全なDeepSeek-R1 671Bパラメーターモデルを動的1.58ビット量子化形式(わずか131GBに圧縮)で実行できるようになりました!しかも最高なことに、大規模なエンタープライズ向けGPUやサーバーを必要とせず、自宅のマシンで実行可能になりました(多くの一般消費者向けハードウェアでは遅い可能性がありますが)。
Ollama上で利用可能な唯一真正のDeepSeek-R1モデルは、以下の671Bバージョンのみです:https://ollama.com/library/deepseek-r1:671b。他のバージョンは蒸留版モデルです。
このガイドは、Open WebUI統合のLlama.cppを使用して完全なDeepSeek-R1 Dynamic 1.58-bit量子化モデルを実行する方法に焦点を当てています。本チュートリアルは、M4 Max + 128GB RAMマシンを使用した手順を示していますが、自身の構成に合わせて設定を調整することが可能です。
ステップ1: Llama.cppをインストール
以下のどちらかを行います:
- プリビルドバイナリをダウンロード
- 自分でビルドする: 以下のガイドを参照してください: Llama.cpp ビルドガイド
ステップ2: UnslothAI提供のモデルをダウンロード
UnslothのHugging Faceページにアクセスし、DeepSeek-R1の適切な動的量子化版をダウンロードしてください。本チュートリアルでは、**1.58-bit (131GB)**版を使用します。この版は高度に最適化さ�れていながら、驚くべきことに非常に機能的です。
「作業ディレクトリ」を把握しておいてください — Pythonスクリプトまたはターミナルセッションが動作している場所のことです。モデルファイルはデフォルトでそのディレクトリのサブフォルダにダウンロードされるため、そのパスを確認しておきましょう。例えば、以下のコマンドを/Users/yourname/Documents/projectsで実行している場合、ダウンロードされたモデルは/Users/yourname/Documents/projects/DeepSeek-R1-GGUFに保存されます。
UnslothAIの開発プロセスや、これらの動的量子化版がなぜ効率的であるのかについて詳しく知りたい場合は、彼らのブログ投稿をチェックしてください:UnslothAI DeepSeek R1 動的量子化。
以下はプログラムを使用してモデルをダウンロードする方法です:
# Hugging Faceの依存関係を実行する前にインストールします:
# pip install huggingface_hub hf_transfer
from huggingface_hub import snapshot_download
snapshot_download(
repo_id = "unsloth/DeepSeek-R1-GGUF", # Hugging Faceリポジトリを指定
local_dir = "DeepSeek-R1-GGUF", # このディレクトリにモデルをダウンロード
allow_patterns = ["*UD-IQ1_S*"], # 1.58-bit版のみをダウンロード
)
ダウンロードが完了すると、以下のようなディレクトリ構造でモデルファイルが見つかります:
DeepSeek-R1-GGUF/
├── DeepSeek-R1-UD-IQ1_S/
│ ├── DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf
│ ├── DeepSeek-R1-UD-IQ1_S-00002-of-00003.gguf
│ ├── DeepSeek-R1-UD-IQ1_S-00003-of-00003.gguf
��🛠️ 後の手順で自分の特定のディレクトリ構造に合わせてパスを更新してください。例えば、スクリプトを/Users/tim/Downloadsで実行している場合、GGUFファイルの完全なパスは:
/Users/tim/Downloads/DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.ggufとなります。
ステップ3: Open WebUIがインストールされ稼働していることを確認
Open WebUIがまだインストールされていない場合でも心配ありません!簡単にセットアップできます。Open WebUIの公式ドキュメントを参照してください。インストールが完了したら、アプリケーションを起動します。後の手順でDeepSeek-R1モデルと接続するために使用します。
ステップ4: Llama.cppを使用してモデルを提供
モデルをダウンロードしたら、次のステップはLlama.cppのサーバーモードを使用して実行することです。開始する前に:
-
llama-serverバイナリを見つけます。 ソースからビルドしている場合(ステップ1を参照)、llama-server実行ファイルはllama.cpp/build/binにあります。cdコマンドを使用してこのディレクトリに移動します:cd [path-to-llama-cpp]/llama.cpp/build/bin[path-to-llama-cpp]を、Llama.cppをクローンまたはビルドした場所で置き換えます。例えば:cd ~/Documents/workspace/llama.cpp/build/bin -
モデルフォルダを指定。 ステップ2で作成したダウンロードされたGGUFファイルのフルパスを使用します。モデルを提供する際、分割GGUFファイルの最初の部分を指定します(例:
DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf)。
以下は、サーバーを起動するためのコマンドです:
./llama-server \
--model /[your-directory]/DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
--port 10000 \
--ctx-size 1024 \
--n-gpu-layers 40
🔑 マシンに基づいたカスタマイズ可能なパラメータ:
--model: ステップ2でGGUFファイルをダウンロードしたディレクトリのパスを/[your-directory]/に置き換えてください。--port: サーバーのデフォルトポートは8080ですが、使用可能なポートに応じて変更できます。--ctx-size: コンテキスト長(トークン数)を決定します。ハードウェアが許せば増やすことができますが、RAM/VRAM使用��量増加に注意してください。--n-gpu-layers: 推論速度を上げるためGPUにオフロードするレイヤー数を設定します。具体的な数はGPUのメモリ容量によって異なります。Unslothのテーブルを参考にしてください。
例えば、モデルが/Users/tim/Documents/workspaceにダウンロードされた場合、コマンドは以下のようになります:
./llama-server \
--model /Users/tim/Documents/workspace/DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
--port 10000 \
--ctx-size 1024 \
--n-gpu-layers 40
サーバーが起動すると、以下のローカルOpenAI互換APIエンドポイントをホストします:
http://127.0.0.1:10000
🖥️ Llama.cppサーバーが実行中
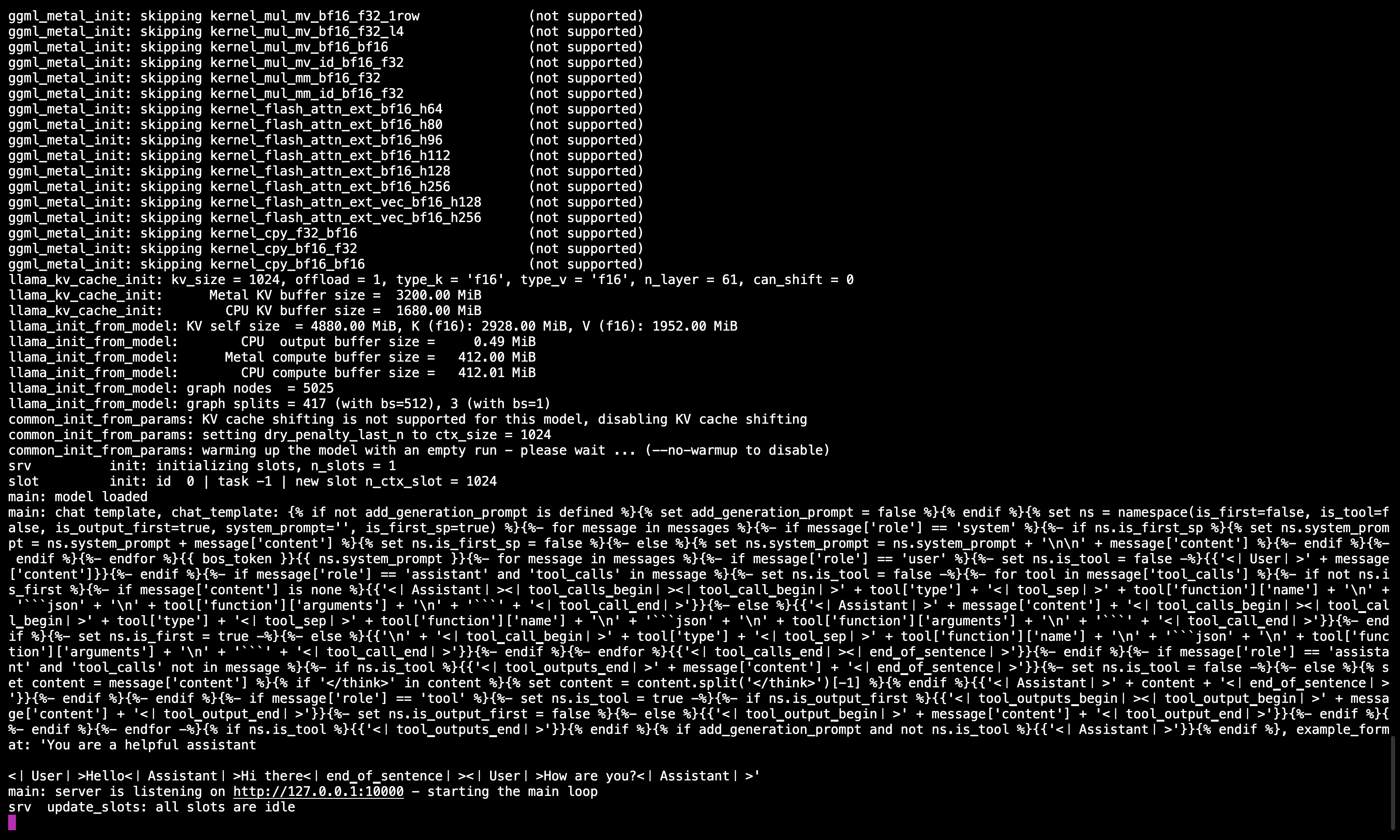
コマンドを実行後、ポート10000でサーバーがアクティブであるこ��とを確認するメッセージが表示されます。
このターミナルセッションを終了しないでください。次のステップでモデルを提供するために必要です。
ステップ5: Llama.cppをOpen WebUIに接続する
- Open WebUIの管理設定に移動してください。
- Connections > OpenAI Connectionsに進んでください。
- 新しい接続の詳細を以下のように追加してください:
- URL:
http://127.0.0.1:10000/v1(またはOpen WebUIをDockerで実行する場合はhttp://host.docker.internal:10000/v1) - APIキー:
none
- URL:
🖥️ Open WebUIでの接続の追加
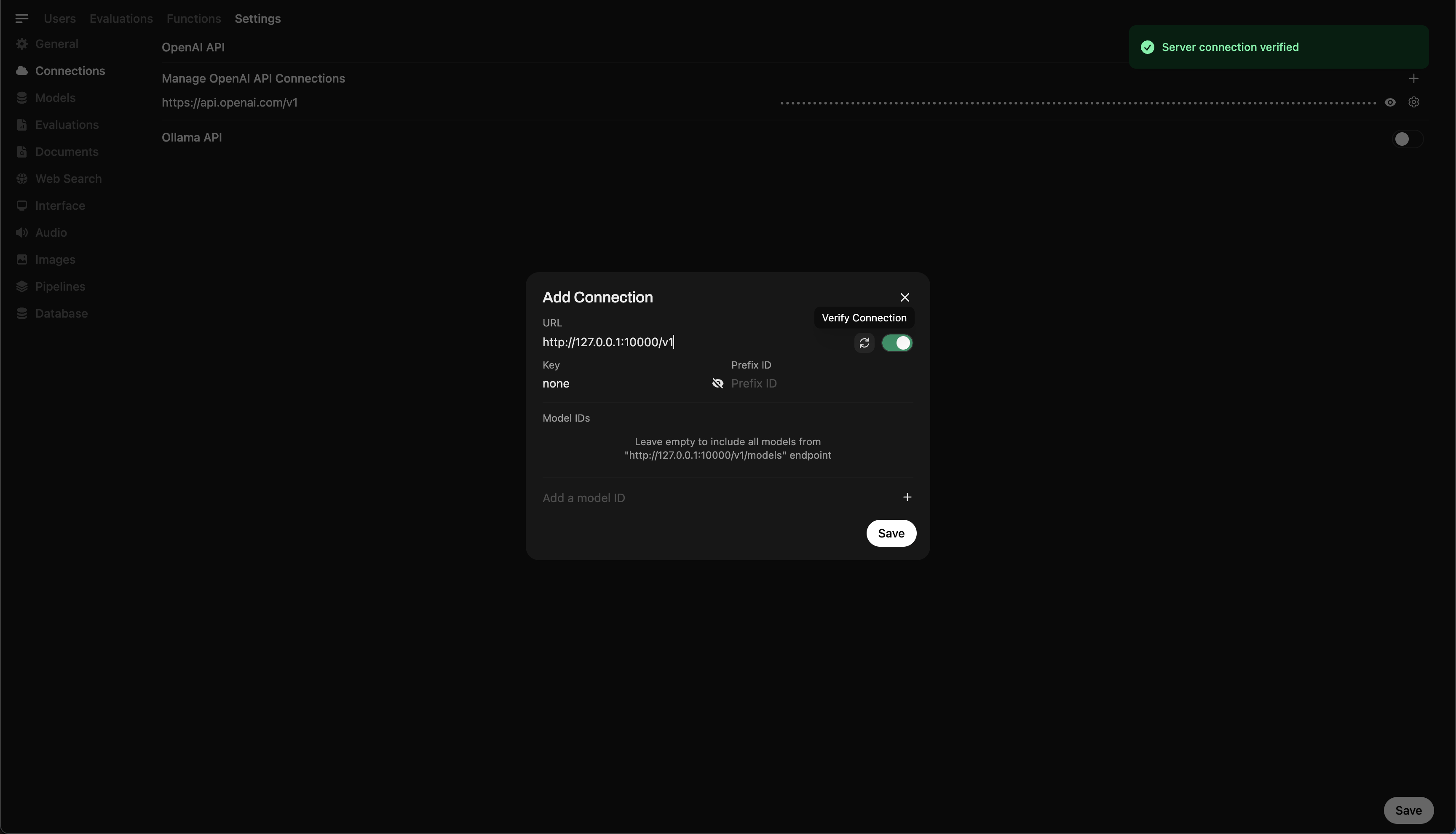
コマンドを実行後、ポート10000でサーバーがアクティブであることを確認するメッセージが表示されます。
接続を保存すると、Open WebUIからDeepSeek-R1を直接クエリできるようになります! 🎉
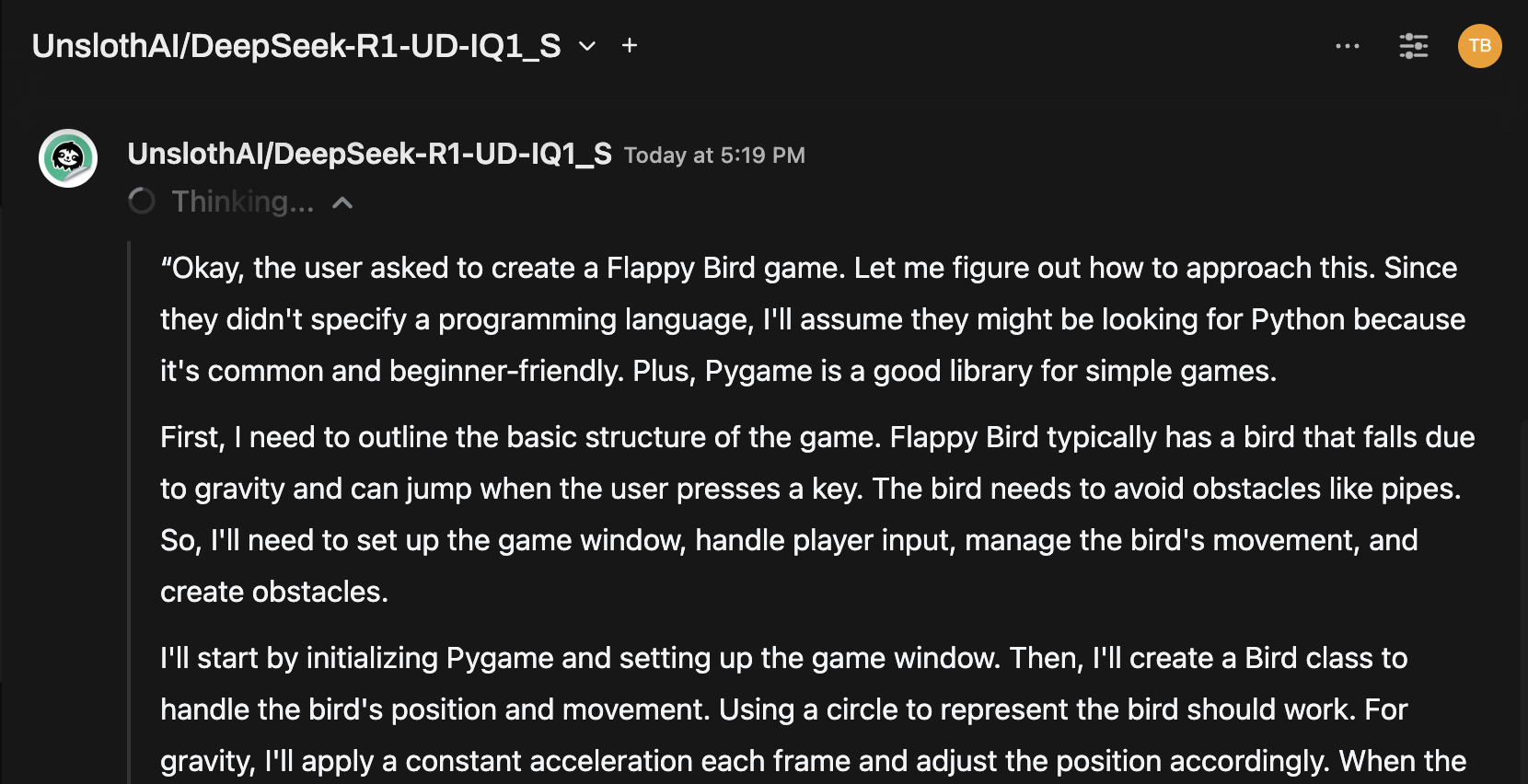
例: 応答の生成
Open WebUIのチャットインターフェースを使用して、DeepSeek-R1 Dynamic 1.58-bitモデルと対話できます。
注意事項と検討
-
パフォーマンス:
DeepSeek-R1のような131GBの大規模モデルを個人のハードウェアで実行するのは遅いです。M4 Max(128GB RAM)を使用しても推論速度は控えめでした。ただ、それが動作するという事実は、UnslothAIの最適化の証です。 -
VRAM/メモリ要求:
最適なパフォーマンスのために十分なVRAMとシステムRAMを確保してください。低スペックのGPUやCPUのみのセットアップでは、速度が遅くなりますが、それでも実行可能です。
UnslothAIとLlama.cppのおかげで、オープンソースの最大級の推論モデルであるDeepSeek-R1(1.58-bitバージョン)の実行が個人の手にも届きました。このようなモデルを消費者ハードウェアで実行するのは難しいですが、大規模な計算インフラなしで実行で��きる能力は重要な技術的マイルストーンです。
⭐ オープンAI研究の限界を押し広げるコミュニティに心から感謝します。
実験を楽しんでください! 🚀