�🐋 Führe DeepSeek R1 Dynamic 1.58-bit mit Llama.cpp aus
Ein großes Dankeschön an UnslothAI für ihre unglaublichen Bemühungen! Dank ihrer Arbeit können wir jetzt das vollständige DeepSeek-R1 Modell mit 671 Milliarden Parametern in seiner dynamischen 1.58-bit quantisierten Form (auf nur 131 GB komprimiert) auf Llama.cpp ausführen! Und das Beste daran? Sie müssen nicht mehr verzweifeln, weil Sie riesige GPU-Cluster auf Unternehmensniveau oder Server benötigen – es ist möglich, dieses Modell auf Ihrem persönlichen Computer auszuführen (wenn auch langsam auf den meisten Verbrauchergeräten).
Das einzige echte DeepSeek-R1 Modell auf Ollama ist die 671B-Version, die hier verfügbar ist: https://ollama.com/library/deepseek-r1:671b. Andere Versionen sind distillierte Modelle.
Dieser Leitfaden konzentriert sich darauf, das vollständige DeepSeek-R1 Dynamic 1.58-bit quantisierte Modell mit Llama.cpp zu verwenden, das in Open WebUI integriert ist. In diesem Tutorial demonstrieren wir die Schritte mit einem M4 Max + 128 GB RAM Rechner. Sie können die Einstellungen an Ihre eigene Konfiguration anpassen.
Schritt 1: Installieren Sie Llama.cpp
Sie können entweder:
- Die vorkompilierten Binärdateien herunterladen
- Oder selbst kompilieren: Befolgen Sie die Anleitung hier: Llama.cpp Build Guide
Schritt 2: Laden Sie das Modell von UnslothAI herunter
Besuchen Sie die Hugging Face Seite von Unsloth und laden Sie die passende dynamisch quantisierte Version von DeepSeek-R1 herunter. Für dieses Tutorial verwenden wir die 1.58-bit-Version (131 GB), die hoch optimiert ist und dennoch überraschend funktional bleibt.
Kennen Sie Ihr „Arbeitsverzeichnis“ – den Ort, an dem Ihr Python-Skript oder Ihre Terminal-Sitzung ausgeführt wird. Die Mod-Dateien werden standardmäßig in einem Unterordner dieses Verzeichnisses heruntergeladen, daher achten Sie darauf, den Pfad zu kennen! Wenn Sie beispielsweise den folgenden Befehl unter /Users/IhrName/Documents/projects ausführen, wird Ihr heruntergeladenes Modell unter /Users/IhrName/Documents/projects/DeepSeek-R1-GGUF gespeichert.
Um mehr über den Entwicklungsprozess von UnslothAI und warum diese dynamischen quantisierten Versionen so effizient sind zu erfahren, lesen Sie ihren Blogbeitrag: UnslothAI DeepSeek R1 Dynamic Quantization.
So laden Sie das Modell programmgesteuert herunter:
# Installieren Sie Hugging Face-Abhängigkeiten vor dem Ausführen:
# pip install huggingface_hub hf_transfer
from huggingface_hub import snapshot_download
snapshot_download(
repo_id = "unsloth/DeepSeek-R1-GGUF", # Hugging Face Repository angeben
local_dir = "DeepSeek-R1-GGUF", # Das Modell wird in dieses Verzeichnis heruntergeladen
allow_patterns = ["*UD-IQ1_S*"], # Nur die 1.58-bit-Version herunterladen
)
Nach Abschluss des Downloads finden Sie die Mod-Dateien in einer Ordnerstruktur wie dieser:
DeepSeek-R1-GGUF/
├── DeepSeek-R1-UD-IQ1_S/
│ ├── DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf
│ ├── DeepSeek-R1-UD-IQ1_S-00002-of-00003.gguf
│ ├── DeepSeek-R1-UD-IQ1_S-00003-of-00003.gguf
🛠️ Aktualisieren Sie die Pfade in den folgenden Schritten, damit sie zu Ihrer spezifischen Ordnerstruktur passen. Wenn Ihr Skript beispielsweise unter /Users/tim/Downloads war, wäre der vollständige Pfad zur GGUF-Datei:
/Users/tim/Downloads/DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf.
Schritt 3: Stellen Sie sicher, dass Open WebUI installiert und ausgeführt wird
Falls Sie Open WebUI noch nicht installiert haben, keine Sorge! Die Einrichtung ist einfach. Befolgen Sie einfach die Open WebUI Dokumentation hier. Sobald installiert, starten Sie die Anwendung – wir verbinden sie später, um mit dem DeepSeek-R1 Modell zu interagieren.
Schritt 4: Das Modell mit Llama.cpp bereitstellen
Jetzt, da das Modell heruntergeladen ist, führen Sie es mit dem Servermodus von Llama.cpp aus. Bevor Sie beginnen:
-
Lokalisieren Sie die
llama-server-Binärdatei. Wenn Sie die Quelle wie in Schritt 1 beschrieben gebaut haben, befindet sich die ausführbare Dateillama-serverunterllama.cpp/build/bin. Wechseln Sie zu diesem Verzeichnis mit dem Befehlcd:cd [Pfad-zu-llama-cpp]/llama.cpp/build/binErsetzen Sie
[Pfad-zu-llama-cpp]durch den Speicherort, an dem Sie Llama.cpp geklont oder erstellt haben. Zum Beispiel:cd ~/Documents/workspace/llama.cpp/build/bin -
Weisen Sie auf Ihren Modellordner hin. Verwenden Sie den vollständigen Pfad zu den heruntergeladenen GGUF-Dateien, die in Schritt 2 erstellt wurden. Geben Sie beim Bereitstellen des Modells den ersten Teil der geteilten GGUF-Dateien an (z. B.
DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf).
Hier ist der Befehl, um den Server zu starten:
./llama-server \
--model /[Ihr-Verzeichnis]/DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
--port 10000 \
--ctx-size 1024 \
--n-gpu-layers 40
🔑 Parameter zur Anpassung basierend auf Ihrer Maschine:
--model: Ersetzen Sie/[your-directory]/durch den Pfad, an dem die GGUF-Dateien in Schritt 2 heruntergeladen wurden.--port: Der Standardserver-Port ist8080, aber Sie können ihn entsprechend Ihrer Portverfügbarkeit ändern.--ctx-size: Bestimmt die Kontextlänge (Anzahl der Tokens). Sie können diese erhöhen, wenn Ihre Hardware dies erlaubt, aber achten Sie auf den steigenden RAM/VRAM-Bedarf.--n-gpu-layers: Legen Sie die Anzahl der Schichten fest, die Sie für schnelleres Inferencing auf Ihre GPU auslagern möchten. Die genaue Anzahl hängt von der Speicherkapazität Ihrer GPU ab — nutzen Sie die Tabelle von Unsloth als Referenz für spezifische Empfehlungen.
Wenn Ihr Modell beispielsweise in /Users/tim/Documents/workspace heruntergeladen wurde, würde Ihr Befehl folgendermaßen aussehen:
./llama-server \
--model /Users/tim/Documents/workspace/DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
--port 10000 \
--ctx-size 1024 \
--n-gpu-layers 40
Sobald der Server startet, hostet er einen lokalen OpenAI-kompatiblen API-Endpunkt unter:
http://127.0.0.1:10000
🖥️ Llama.cpp-Server läuft
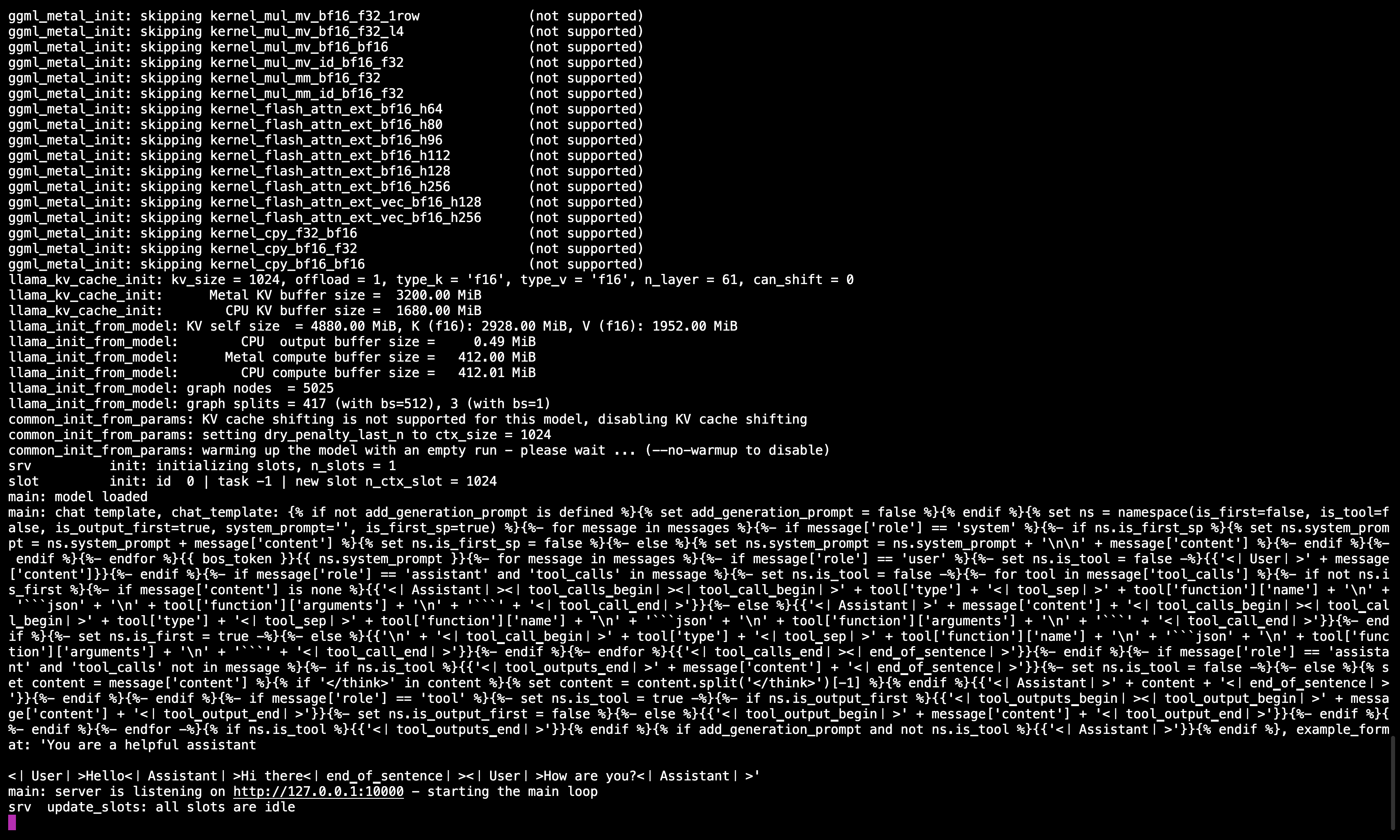
Nachdem Sie den Befehl ausgeführt haben, sollten Sie eine Nachricht sehen, die bestätigt, dass der Server aktiv ist und auf Port 10000 lauscht.
Stellen Sie sicher, dass Sie dieses Terminal geöffnet halten, da es das Modell für alle nachfolgenden Schritte bereitstellt.
Schritt 5: Verbinden Sie Llama.cpp mit Open WebUI
- Gehen Sie zu Admin Settings in Open WebUI.
- Navigieren Sie zu Connections > OpenAI Connections.
- Fügen Sie die folgenden Details für die neue Verbindung hinzu:
- URL:
http://127.0.0.1:10000/v1(oderhttp://host.docker.internal:10000/v1, wenn Sie Open WebUI in Docker verwenden) - API-Schlüssel:
none
- URL:
🖥️ Verbindung in Open WebUI hinzufügen
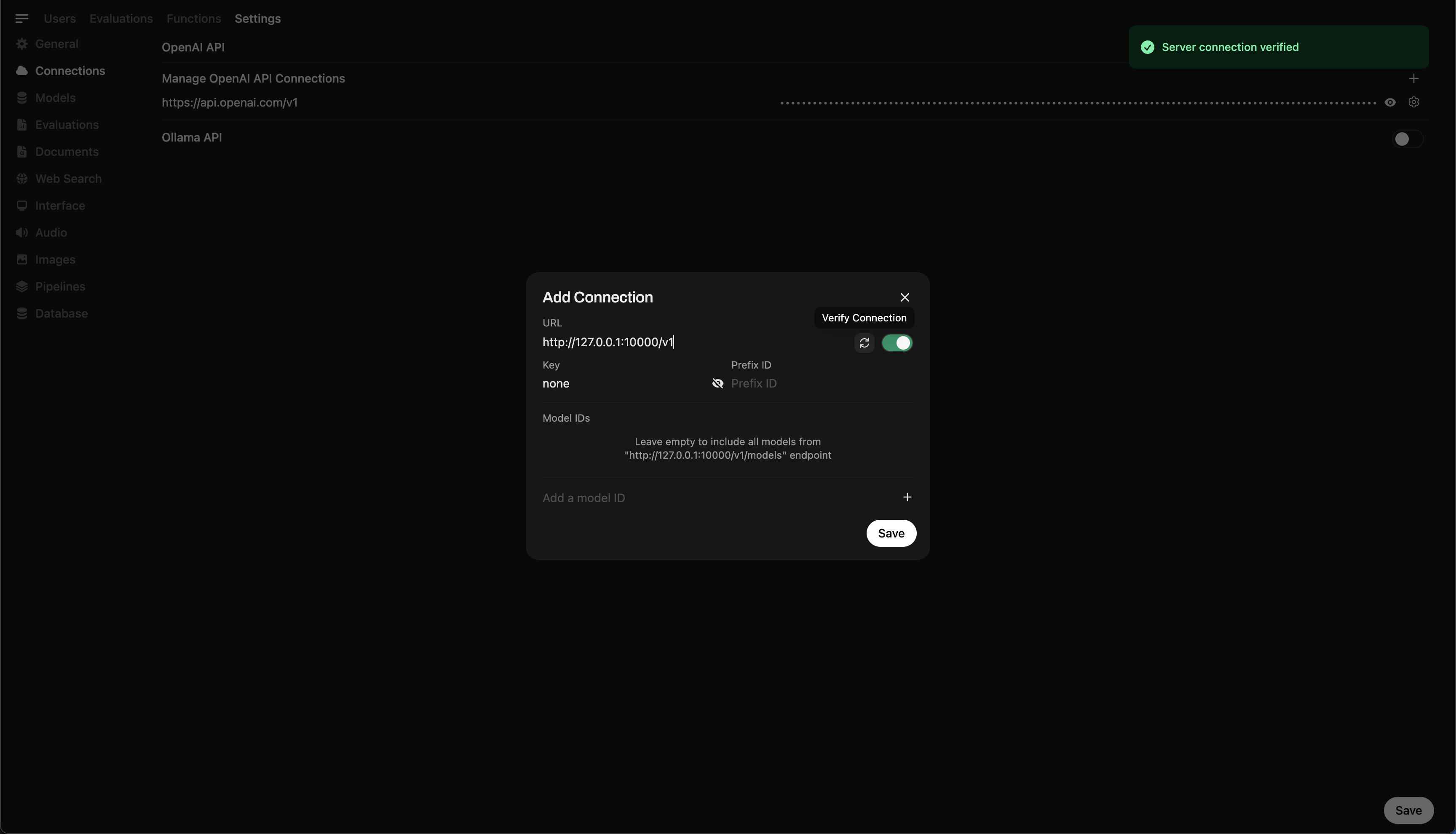
Nachdem Sie den Befehl ausgeführt haben, sollten Sie eine Nachricht sehen, die bestätigt, dass der Server aktiv ist und auf Port 10000 lauscht.
Sobald die Verbindung gespeichert ist, können Sie DeepSeek-R1 direkt aus Open WebUI anfragen! 🎉
Beispiel: Antworten generieren
Sie können nun die Chat-Oberfläche von Open WebUI verwenden, um mit dem DeepSeek-R1 Dynamic 1.58-bit Model zu interagieren.
Hinweise und Überlegungen
-
Leistung: Das Ausführen eines enormen 131GB-Modells wie DeepSeek-R1 auf persönlicher Hardware wird langsam sein. Selbst mit unserem M4 Max (128GB RAM) waren die Inferenzgeschwindigkeiten bescheiden. Aber die Tatsache, dass es überhaupt funktioniert, ist ein Beweis für die Optimierungen von UnslothAI.
-
VRAM-/Speicheranforderungen: Stellen Sie sicher, dass ausreichend VRAM und Systemspeicher für eine optimale Leistung verfügbar sind. Bei GPUs mit niedriger Leistung oder CPU-only-Setups erwarten Sie langsamere Geschwindigkeiten (aber es ist trotzdem machbar!).
Dank UnslothAI und Llama.cpp ist es endlich möglich, eines der größten Open-Source-Reasoning-Modelle, DeepSeek-R1 (1.58-bit Version), für Einzelpersonen zugänglich zu machen. Während es herausfordernd ist, solche Modelle auf Verbraucherhardware auszuführen, ist die Fähigkeit, dies ohne massiven Recheninfrastruktur zu tun, ein bedeutender technologischer Meilenstein.
⭐ Ein großes Dankeschön an die Community, die die Grenzen der offenen KI-Forschung verschiebt.
Viel Spaß beim Experimentieren! 🚀