🐋 Ejecutar DeepSeek R1 Dinámico 1.58-bit con Llama.cpp
¡Un enorme agradecimiento a UnslothAI por sus increíbles esfuerzos! Gracias a su arduo trabajo, ahora podemos ejecutar el modelo completo DeepSeek-R1 con 671 mil millones de parámetros en su forma dinámica de 1.58-bit cuantificada (comprimido a solo 131GB) en Llama.cpp. ¿La mejor parte? Ya no tienes que desesperarte por necesitar GPU de clase empresarial o servidores masivos: es posible ejecutar este modelo en tu máquina personal (aunque de manera lenta en la mayoría del hardware de consumo).
El único modelo verdadero DeepSeek-R1 en Ollama es la versión 671B disponible aquí: https://ollama.com/library/deepseek-r1:671b. Otras versiones son modelos destilados.
Esta guía se centra en ejecutar el modelo completo DeepSeek-R1 Dynamic 1.58-bit cuantificado utilizando Llama.cpp integrado con Open WebUI. Para este tutorial, demostraremos los pasos en una máquina M4 Max + 128GB RAM. Puedes adaptar la configuración a tu propia instalación.
Paso 1: Instalar Llama.cpp
Puedes:
- Descargar los binarios precompilados
- O compilarlo tú mismo: Sigue las instrucciones aquí: Guía de compilación de Llama.cpp
Paso 2: Descargar el modelo proporcionado por UnslothAI
Dirígete a la página de Hugging Face de Unsloth y descarga la versión dinámica cuantificada apropiada de DeepSeek-R1. Para este tutorial, utilizaremos la versión 1.58-bit (131GB), que está altamente optimizada y sigue siendo sorprendentemente funcional.
Conoce tu "directorio de trabajo" — dónde se está ejecutando tu script Python o sesión de terminal. Los archivos del modelo se descargarán en una subcarpeta de ese directorio por defecto, ¡así que asegúrate de conocer su ruta! Por ejemplo, si estás ejecutando el comando siguiente en /Users/tu_nombre/Documents/projects, tu modelo descargado se guardará bajo /Users/tu_nombre/Documents/projects/DeepSeek-R1-GGUF.
Para entender más sobre el proceso de desarrollo de UnslothAI y por qué estas versiones dinámicamente cuantificadas son tan eficientes, revisa su publicación de blog: UnslothAI Cuantización Dinámica DeepSeek R1.
Aquí está cómo descargar el modelo programáticamente:
# Instala las dependencias de Hugging Face antes de ejecutarlo:
# pip install huggingface_hub hf_transfer
from huggingface_hub import snapshot_download
snapshot_download(
repo_id = "unsloth/DeepSeek-R1-GGUF", # Especifica el repositorio de Hugging Face
local_dir = "DeepSeek-R1-GGUF", # El modelo se descargará en este directorio
allow_patterns = ["*UD-IQ1_S*"], # Solo descargar la versión de 1.58-bit
)
Una vez completada la descarga, encontrarás los archivos del modelo en una estructura de directorios como esta:
DeepSeek-R1-GGUF/
├── DeepSeek-R1-UD-IQ1_S/
│ ├── DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf
│ ├── DeepSeek-R1-UD-IQ1_S-00002-of-00003.gguf
│ ├── DeepSeek-R1-UD-IQ1_S-00003-of-00003.gguf
🛠️ Actualiza las rutas en los pasos posteriores para coincidir con tu estructura de directorios específica. Por ejemplo, si tu script estaba en /Users/tim/Downloads, la ruta completa al archivo GGUF sería:
/Users/tim/Downloads/DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf.
Paso 3: Asegúrate de que Open WebUI esté instalado y ejecutándose
Si aún no tienes instalado Open WebUI, ¡no te preocupes! Es una configuración sencilla. Solo sigue la documentación de Open WebUI aquí. Una vez instalado, inicia la aplicación: la conectaremos en un paso posterior para interactuar con el modelo DeepSeek-R1.
Paso 4: Servir el modelo utilizando Llama.cpp
Ahora que el modelo está descargado, el siguiente paso es ejecutarlo utilizando el modo servidor de Llama.cpp. Antes de comenzar:
-
Ubica el binario
llama-server. Si lo compilaste desde el código fuente (como se detalla en el Paso 1), el ejecutablellama-serverestará ubicado enllama.cpp/build/bin. Navega a este directorio usando el comandocd:cd [ruta-a-llama-cpp]/llama.cpp/build/binReemplaza
[ruta-a-llama-cpp]con la ubicación donde clonaste o compilaste Llama.cpp. Por ejemplo:cd ~/Documents/workspace/llama.cpp/build/bin -
Apunta a tu carpeta del modelo. Usa la ruta completa de los archivos GGUF descargados en el Paso 2. Al servir el modelo, especifica la primera parte de los archivos divididos GGUF (por ejemplo,
DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf).
Aquí está el comando para iniciar el servidor:
./llama-server \
--model /[tu-directorio]/DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
--port 10000 \
--ctx-size 1024 \
--n-gpu-layers 40
🔑 Parámetros para personalizar según su máquina:
--model: Sustituya/[your-directory]/con la ruta donde se descargaron los archivos GGUF en el Paso 2.--port: El servidor utiliza por defecto el puerto8080, pero puede cambiarlo según la disponibilidad de su puerto.--ctx-size: Determina la longitud del contexto (número de tokens). Puede aumentarlo si su hardware lo permite, pero tenga cuidado con el aumento en el uso de RAM/VRAM.--n-gpu-layers: Establezca el número de capas que desea descargar a su GPU para una inferencia más rápida. El número exacto depende de la capacidad de memoria de su GPU — consulte la tabla de Unsloth para recomendaciones específicas.
Por ejemplo, si su modelo se descargó en /Users/tim/Documents/workspace, su comando se vería así:
./llama-server \
--model /Users/tim/Documents/workspace/DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
--port 10000 \
--ctx-size 1024 \
--n-gpu-layers 40
Cuando el servidor comience, alojará un endpoint API local compatible con OpenAI en:
http://127.0.0.1:10000
🖥️ Servidor Llama.cpp en ejecución
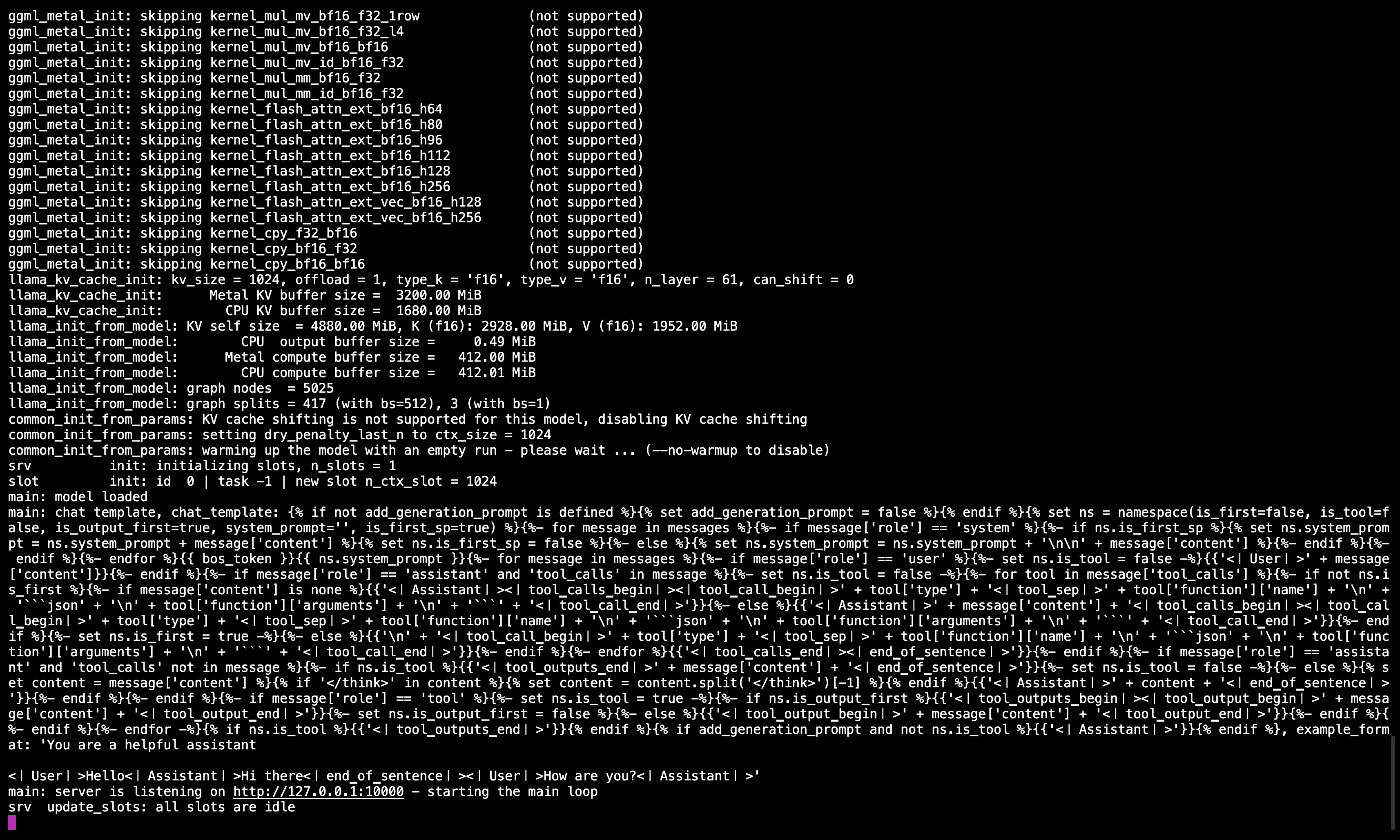
Después de ejecutar el comando, debería ver un mensaje que confirma que el servidor está activo y escuchando en el puerto 10000.
Asegúrese de mantener esta sesión del terminal activa, ya que sirve el modelo para todos los pasos subsecuentes.
Paso 5: Conectar Llama.cpp a Open WebUI
- Vaya a Configuración de administrador en Open WebUI.
- Navegue a Conexiones > Conexiones OpenAI.
- Añada los siguientes detalles para la nueva conexión:
- URL:
http://127.0.0.1:10000/v1(ohttp://host.docker.internal:10000/v1si está ejecutando Open WebUI en Docker) - Clave API:
none
- URL:
🖥️ Agregando conexión en Open WebUI
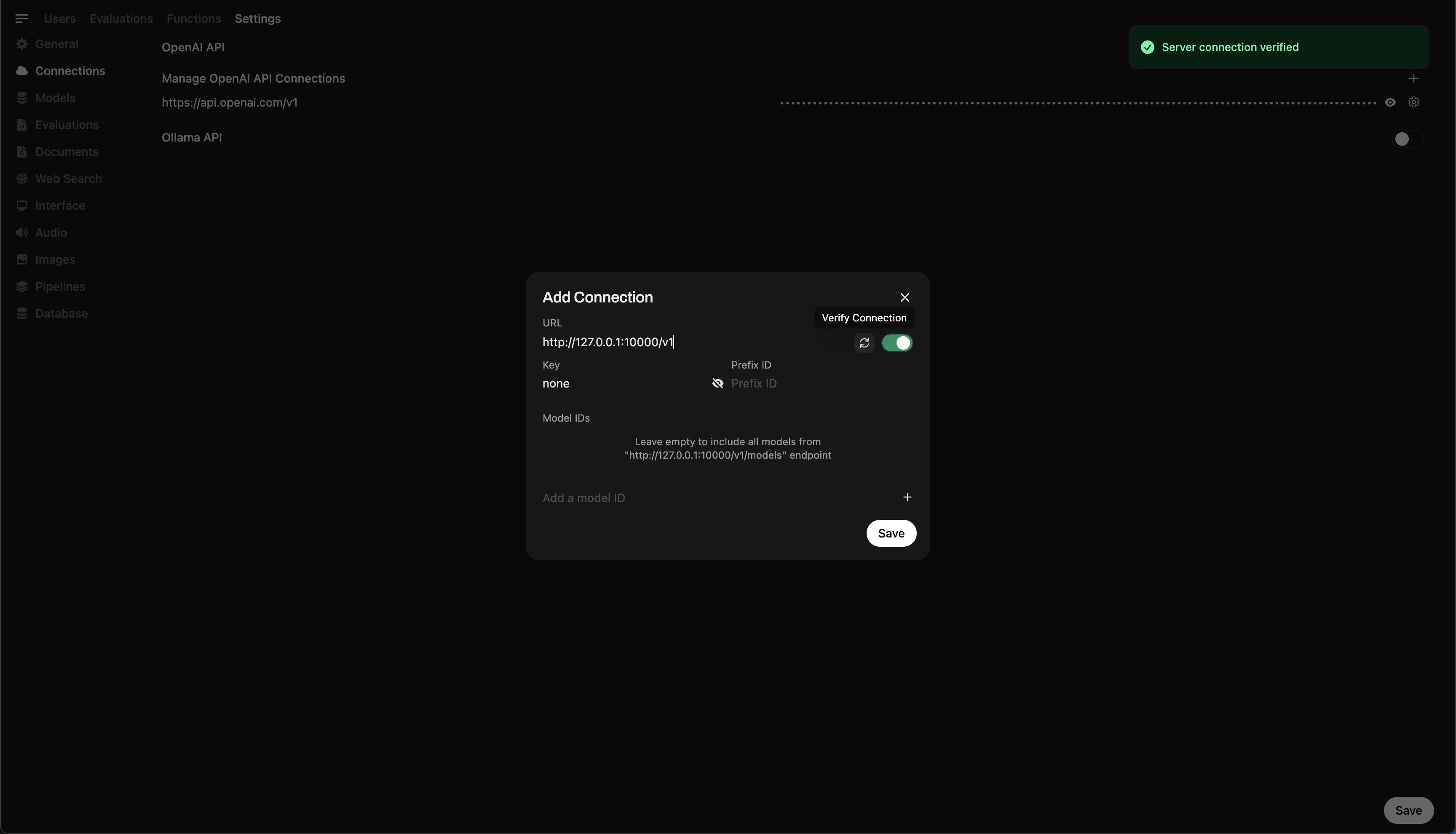
Después de ejecutar el comando, debería ver un mensaje que confirma que el servidor está activo y escuchando en el puerto 10000.
Una vez que la conexión se haya guardado, ¡puede comenzar a consultar DeepSeek-R1 directamente desde Open WebUI! 🎉
Ejemplo: Generación de respuestas
Ahora puede usar la interfaz de chat de Open WebUI para interactuar con el modelo dinámico DeepSeek-R1 de 1.58 bits.
Notas y consideraciones
-
Rendimiento: Ejecutar un modelo masivo de 131GB como DeepSeek-R1 en hardware personal será lento. Incluso con nuestra M4 Max (128GB RAM), las velocidades de inferencia fueron modestas. Pero el hecho de que funcione es un testimonio de las optimizaciones de UnslothAI.
-
Requisitos de VRAM/Memoria: Asegúrese de tener suficiente VRAM y RAM del sistema para un rendimiento óptimo. Con GPUs de gama baja o configuraciones sólo CPU, espere velocidades más lentas (pero ¡aún es posible!).
Gracias a UnslothAI y Llama.cpp, ejecutar uno de los modelos de razonamiento más grandes de código abierto, DeepSeek-R1 (versión de 1.58 bits), finalmente es accesible para particulares. Aunque es desafiante ejecutar tales modelos en hardware de consumo, la capacidad de hacerlo sin infraestructura computacional masiva es un hito tecnológico significativo.
⭐ Muchas gracias a la comunidad por expandir los límites de la investigación en IA abierta.
¡Feliz experimentación! 🚀