🐋 運行 DeepSeek R1 Dynamic 1.58-bit 使用 Llama.cpp
特別感謝 UnslothAI 的卓越貢獻!多虧了他們的努力,我們現在可以在 Llama.cpp 上運行 完整的 DeepSeek-R1 671B 參數模型,其動態 1.58-bit 量化形式已壓縮到僅 131GB!而最棒的是?您再也不需要絕望的面對需要龐大的企業級 GPU 或伺服器的需求——現在可以在您的個人電腦上運行該模型(雖然對於大多數消費級硬體來說速度較慢)。
Ollama 上唯一真正的 DeepSeek-R1 模型是這裡提供的 671B 版本:https://ollama.com/library/deepseek-r1:671b。其他版本是 精簡模型。
本指南專注於使用 Llama.cpp 與 Open WebUI 集成運行 完整的 DeepSeek-R1 Dynamic 1.58-bit 量化模型。這裡的演示步驟將基於一台 M4 Max + 128GB RAM 的機器。您可以根據自己的配置進行適配。
第一步:安裝 Llama.cpp
您可以選擇:
- 下載預編譯的二進制文件
- 或自行編譯:請按照此處的說明進行:Llama.cpp 編譯指南
第二步:下載由 UnslothAI 提供的模型
前往 Unsloth 的 Hugging Face 頁面 並下載適合的 動態量化版本 DeepSeek-R1。本指南使用的是 1.58-bit(131GB) 版本,這是高度優化但仍然功能強大的版本。
確保了解您的 "工作目錄" 是哪裡——即運行 Python 腳本或終端會話所在的位置。模型文件預設會下載到該目錄的子文件夾中,因此請確保您知道其路徑!例如,如果您在 /Users/yourname/Documents/projects 下運行以下命令,那麼下載的模型將存儲於 /Users/yourname/Documents/projects/DeepSeek-R1-GGUF。
要了解更多關於 UnslothAI 的開發過程以及這些動態量化版本為何如此高效,請查看其部落格文章:UnslothAI DeepSeek R1 Dynamic Quantization。
以下是以編程方式下載模型的方法:
# 在運行之前安裝 Hugging Face 相關依賴:
# pip install huggingface_hub hf_transfer
from huggingface_hub import snapshot_download
snapshot_download(
repo_id = "unsloth/DeepSeek-R1-GGUF", # 指定 Hugging Face 的 repo
local_dir = "DeepSeek-R1-GGUF", # 模型將下載到該目錄
allow_patterns = ["*UD-IQ1_S*"], # 僅下載 1.58-bit 版本
)
下載完成後,您會在類似下面的目錄結構中找到模型文件:
DeepSeek-R1-GGUF/
├── DeepSeek-R1-UD-IQ1_S/
│ ├── DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf
│ ├── DeepSeek-R1-UD-IQ1_S-00002-of-00003.gguf
│ ├── DeepSeek-R1-UD-IQ1_S-00003-of-00003.gguf
🛠️ 在後續步驟中更新路徑以 匹配您的特定目錄結構。例如,如果您的腳本在 /Users/tim/Downloads 中運行,那麼 GGUF 文件的完整路徑將是:
/Users/tim/Downloads/DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf。
第三步:確保已安裝並運行 Open WebUI
如果您尚未安裝 Open WebUI,不用擔心!安裝過程非常簡單。只需按照 Open WebUI 文檔 的說明進行操作。安裝完成後啟動應用程序——稍後我們將連接以與 DeepSeek-R1 模型互動。
第四步:使用 Llama.cpp 提供模型服務
現在模型已下載,接下來的步驟是使用 Llama.cpp 的服務器模式 運行它。在開始之前:
-
找到
llama-server二進制文件。 如果是從源代碼自行構建(如第 1 步所述),llama-server可執行文件位於llama.cpp/build/bin中。使用cd命令導航到此目錄:cd [path-to-llama-cpp]/llama.cpp/build/bin將
[path-to-llama-cpp]替換為您克隆或構建 Llama.cpp 的位置。例如:cd ~/Documents/workspace/llama.cpp/build/bin -
指向您的模型文件夾。 使用第 2 步中下載的 GGUF 文件的完整路徑。在提供模型服務時,請指定分割 GGUF 文件的第一部分(例如
DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf)。
啟動服務器的命令如下:
./llama-server \
--model /[your-directory]/DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
--port 10000 \
--ctx-size 1024 \
--n-gpu-layers 40
🔑 根據您的機器自定義參數:
--model: 將/[your-directory]/替換為在第2步中下載GGUF文件的路徑。--port: 伺服器預設端口是8080,但可根據可用的端口進行更改。--ctx-size: 確定上下文長度(標記數量)。如果硬件允許,可以增加它,但請注意RAM/VRAM使用量可能會上升。--n-gpu-layers: 設定您希望卸載到GPU上的層數以提高推理速度。具體數量取決於GPU的記憶容量—請參考Unsloth的表格以獲取具體建議。
例如,如果您的模型下載到 /Users/tim/Documents/workspace,您的命令看起來像這樣:
./llama-server \
--model /Users/tim/Documents/workspace/DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
--port 10000 \
--ctx-size 1024 \
--n-gpu-layers 40
當伺服器啟動時,它將在以下地址託管本地兼容OpenAI的API端點:
http://127.0.0.1:10000
🖥️ Llama.cpp 伺服器運行中
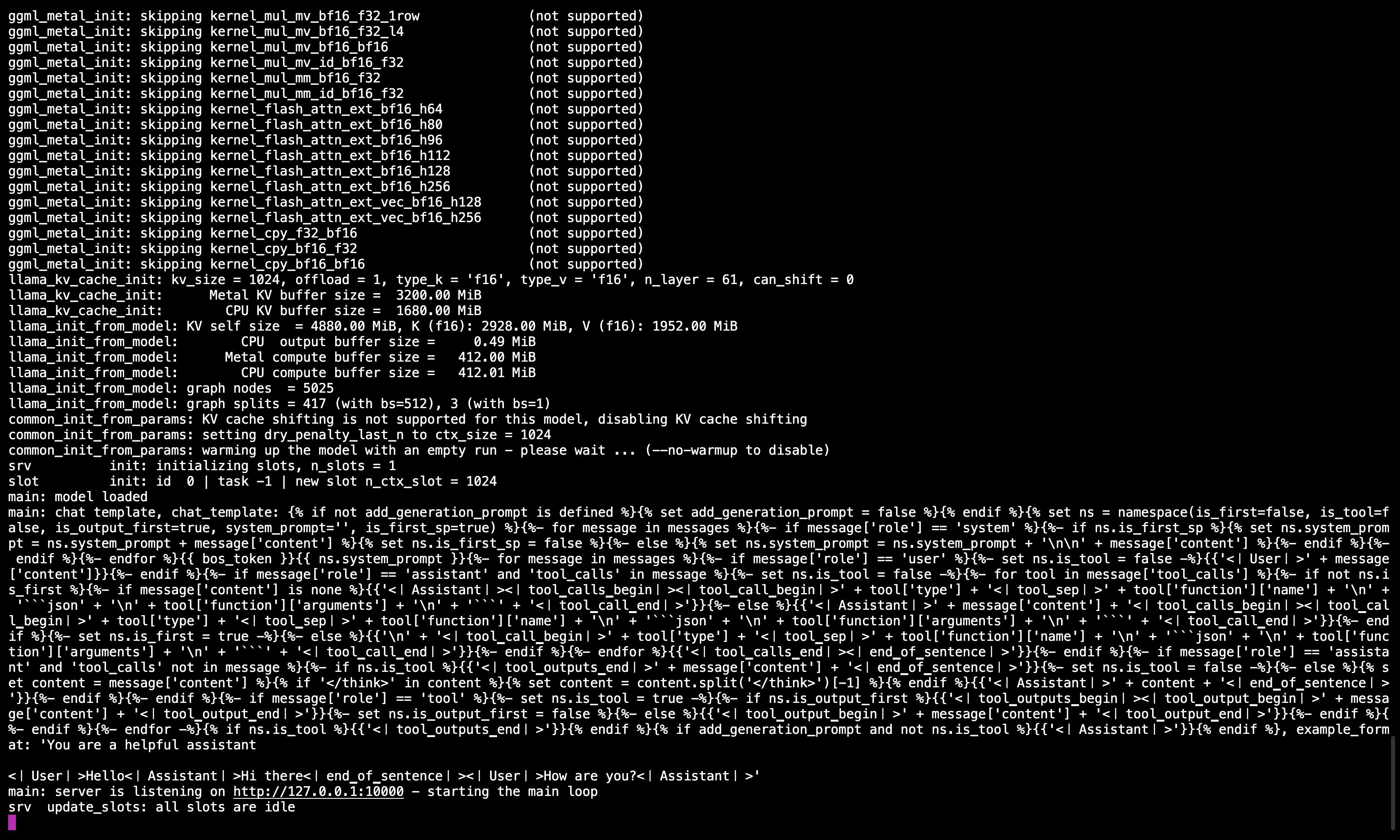
執行命令後,您應該會看到一條消息確認伺服器正在運行並在端口10000上等待。
請確保保持此終端會話運行,因為它負責為後續步驟提供模型服務。
步驟5:將Llama.cpp連接到Open WebUI
- 前往Open WebUI中的管理員設置。
- 導航到連接 > OpenAI連接。
- 為新的連接添加以下詳細信息:
- URL:
http://127.0.0.1:10000/v1(或在docker中運行Open WebUI時為http://host.docker.internal:10000/v1) - API Key:
none
- URL:
🖥️ 在Open WebUI中添加連接
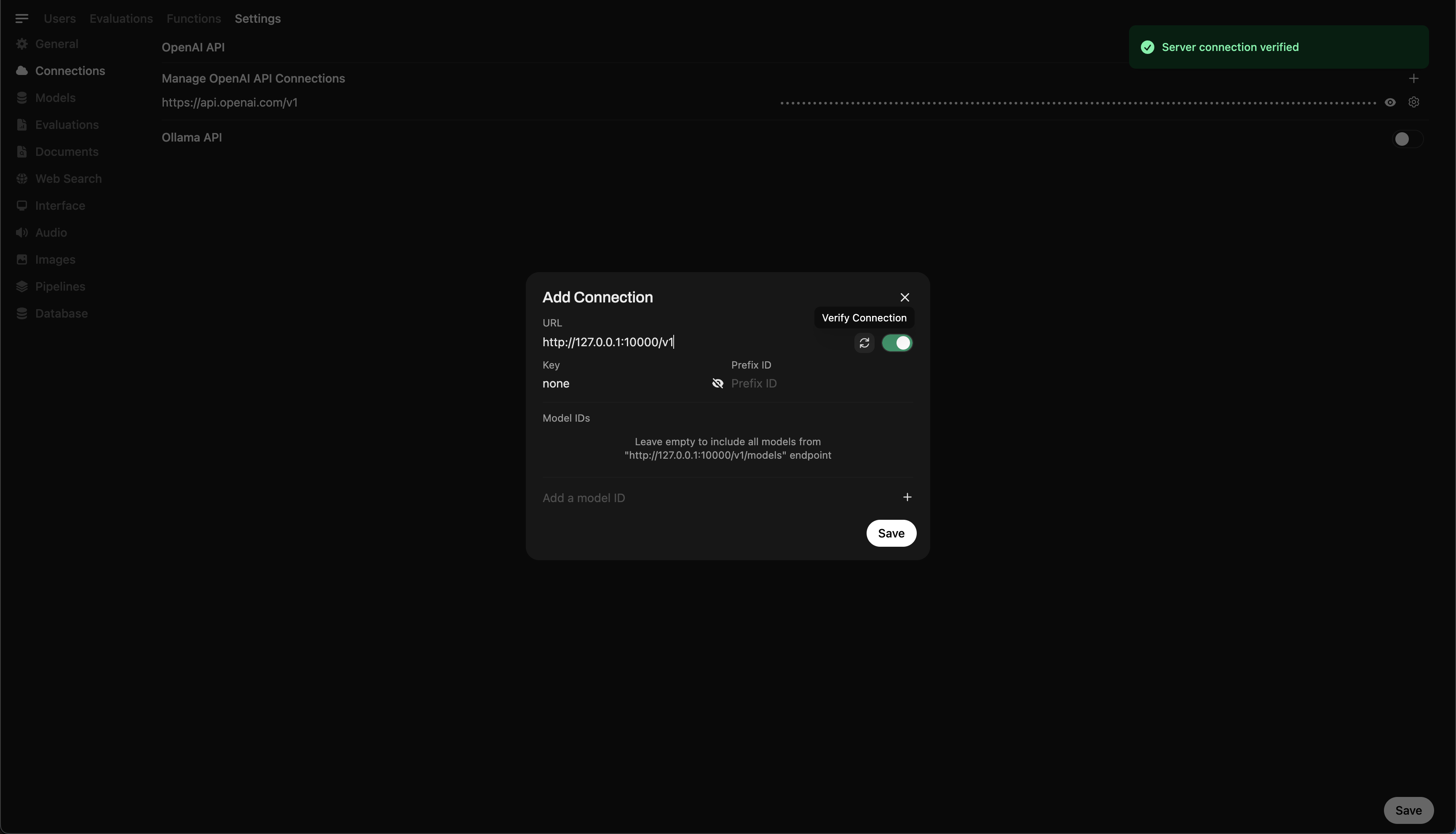
執行命令後,您應該會看到一條消息確認伺服器正在運行並在端口10000上等待。
保存連接後,您可以直接從Open WebUI開始查詢DeepSeek-R1! 🎉
範例:生成響應
現在您可以使用Open WebUI的聊天界面與DeepSeek-R1動態1.58位模型進行互動。
注意事項和考量
-
性能: 在個人硬件上運行像DeepSeek-R1這樣的大型131GB模型會很慢。即使使用我們的M4 Max(128GB RAM),推理速度也較為緩慢。但能夠運行它本身已經是UnslothAI優化的一個證明。
-
VRAM/記憶體需求: 確保有足夠的VRAM和系統RAM以獲取最佳性能。對於低端GPU或僅CPU的設置,預期會有較慢速度(但仍然可以運行!)。
感謝UnslothAI和Llama.cpp的努力,運行目前最大的開源推理模型之一——DeepSeek-R1(1.58位版本)現在終於對個人使用者開放。儘管在消費型硬件上運行這類模型是具有挑戰的,但能夠不用龐大的計算基礎設施而做到這一點是科技的一個重要里程碑。
⭐ 感謝社群不斷推動開源AI研究的邊界。
祝您實驗成功!🚀