🐋 Запустите DeepSeek R1 Dynamic 1.58-bit с помощью Llama.cpp
Огромная благодарность UnslothAI за их невероятные усилия! Благодаря их упорной работе, мы теперь можем запустить полную модель DeepSeek-R1 с параметрами 671B в ее динамической 1.58-битной квантованной форме (сжатой до всего 131GB) на Llama.cpp! А самое лучшее? Вам больше не нужно расстраиваться из-за необходимости иметь огромные серверы или GPUs корпоративного класса — эту модель можно запустить на вашем персональном компьютере (хотя для большинства потребительского оборудования это будет медленно).
Единственная настоящая DeepSeek-R1 модель на Ollama — это версия 671B, доступная по ссылке: https://ollama.com/library/deepseek-r1:671b. Остальные версии — это дистиллированные модели.
Этот гид посвящен запуску полной DeepSeek-R1 Dynamic 1.58-bit квантованной модели с использованием Llama.cpp, интегрированной с Open WebUI. В этом уроке мы покажем шаги на примере компьютера M4 Max + 128GB RAM. Вы можете адаптировать настройки к вашей конфигурации.
Шаг 1: Установите Llama.cpp
Вы можете либо:
- Скачать готовые бинарники
- Или собрать са�мостоятельно: Следуйте инструкциям здесь: Llama.cpp Build Guide
Шаг 2: Скачайте модель, предоставленную UnslothAI
Перейдите на страницу Unsloth на Hugging Face и скачайте подходящую динамически квантованную версию DeepSeek-R1. В этом руководстве мы используем 1.58-битную (131GB) версию, которая оптимизирована и остается удивительно функциональной.
Знайте свою "рабочую директорию" — где работает ваш Python-скрипт или сеанс терминала. Файлы модели скачиваются в подпапку этой директории по умолчанию, поэтому убедитесь, что знаете путь! Например, если вы выполняете команду в /Users/yourname/Documents/projects, ваша скачанная модель будет сохранена в /Users/yourname/Documents/projects/DeepSeek-R1-GGUF.
Чтобы лучше понять процесс разработки UnslothAI и почему эти динамически квантованные версии настолько эффективны, ознакомьтесь с их статьей в блоге: UnslothAI DeepSeek R1 Dynamic Quantization.
Вот как можно программно скачать модель:
# Установите зависимости Hugging Face перед выполнением этого:
# pip install huggingface_hub hf_transfer
from huggingface_hub import snapshot_download
snapshot_download(
repo_id = "unsloth/DeepSeek-R1-GGUF", # Укажите репозиторий Hugging Face
local_dir = "DeepSeek-R1-GGUF", # Модель будет скачана в эту директорию
allow_patterns = ["*UD-IQ1_S*"], # Скачайте только 1.58-битную версию
)
После завершения скачивания вы найдете файлы модели в структуре директорий, похожей на эту:
DeepSeek-R1-GGUF/
├── DeepSeek-R1-UD-IQ1_S/
│ ├── DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf
│ ├── DeepSeek-R1-UD-IQ1_S-00002-of-00003.gguf
│ ├── DeepSeek-R1-UD-IQ1_S-00003-of-00003.gguf
🛠️ Обновите пути на следующих шагах в соответствии с вашей конкретной структурой директорий. Например, если ваш скрипт находился в /Users/tim/Downloads, полный путь к файлу GGUF будет:
/Users/tim/Downloads/DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf.
Шаг 3: Убедитесь, что Open WebUI установлен и запущен
Если у вас еще нет Open WebUI, не волнуйтесь! Установка проста. Просто следуйте документации Open WebUI здесь. После установки запустите приложение — мы свяжем его на следующем шаге для взаимодействия с моделью DeepSeek-R1.
Шаг 4: Запустите модель через Llama.cpp
Теперь, когда модель скачана, следующим шагом будет ее запуск с использованием режима сервера Llama.cpp. Прежде чем начать:
-
Найдите исполняемый файл
llama-server. Если вы собирали из исходного кода (как указано в Шаге 1), исполняемый файлllama-serverбудет �находиться вllama.cpp/build/bin. Перейдите в эту директорию, используя командуcd:cd [path-to-llama-cpp]/llama.cpp/build/binЗамените
[path-to-llama-cpp]на путь, где вы клонировали или собрали Llama.cpp. Например:cd ~/Documents/workspace/llama.cpp/build/bin -
Укажите вашу папку с моделью. Используйте полный путь к скачанным файлам GGUF из Шага 2. При запуске модели укажите первую часть разделенных файлов GGUF (например,
DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf).
Вот команда для запуска сервера:
./llama-server \
--model /[your-directory]/DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
--port 10000 \
--ctx-size 1024 \
--n-gpu-layers 40
🔑 Параметры для настройки в зависимости от вашей машины:
--model: Замените/[your-directory]/на путь, куда вы загрузили файлы GGUF на Шаге 2.--port: По умолчанию сервер использует8080, но вы можете изменить его в зависимости от доступности порта.--ctx-size: Определяет длину контекста (количество токенов). Вы можете увеличить это значение, если ваше оборудова�ние позволяет, но будьте осторожны с увеличением использования ОЗУ/VRAM.--n-gpu-layers: Установите количество слоев, которые вы хотите выгрузить на ваш GPU для более быстрого вывода. Точное число зависит от объема памяти вашего GPU — смотрите таблицу Unsloth для конкретных рекомендаций.
Например, если ваша модель была загружена в каталог /Users/tim/Documents/workspace, ваша команда будет выглядеть так:
./llama-server \
--model /Users/tim/Documents/workspace/DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
--port 10000 \
--ctx-size 1024 \
--n-gpu-layers 40
После запуска сервера он будет размещать локальный API-эндпоинт, совместимый с OpenAI, по следующему адресу:
http://127.0.0.1:10000
🖥️ Сервер Llama.cpp запущен
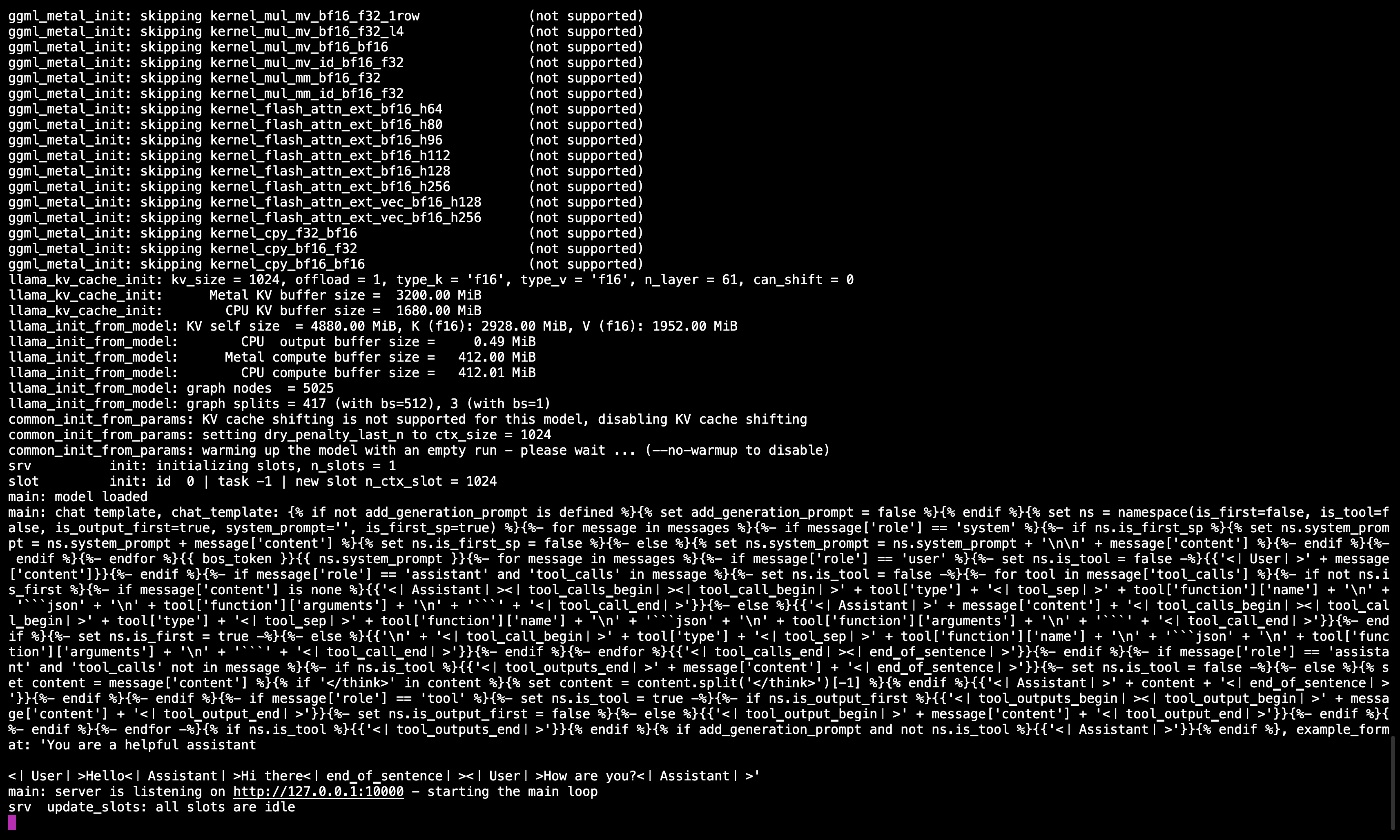
После выполнения команды вы должны увидеть сообщение, подтверждающее, что сервер активен и слушает порт 10000.
Убедитесь, что эта сессия терминала остается активной, так как она обслуживает модель для всех последующих шагов.
Шаг 5: Подключение Llama.cpp к Open WebUI
- Перейдите в Настройки администратора в Open WebUI.
- Перейдите в Соединения > Подключения OpenAI.
- Добавьте следующие данные для нового подключения:
- URL:
http://127.0.0.1:10000/v1(илиhttp://host.docker.internal:10000/v1, если вы запускаете Open WebUI в Docker) - API Key:
none
- URL:
🖥️ Добавление подключения в Open WebUI
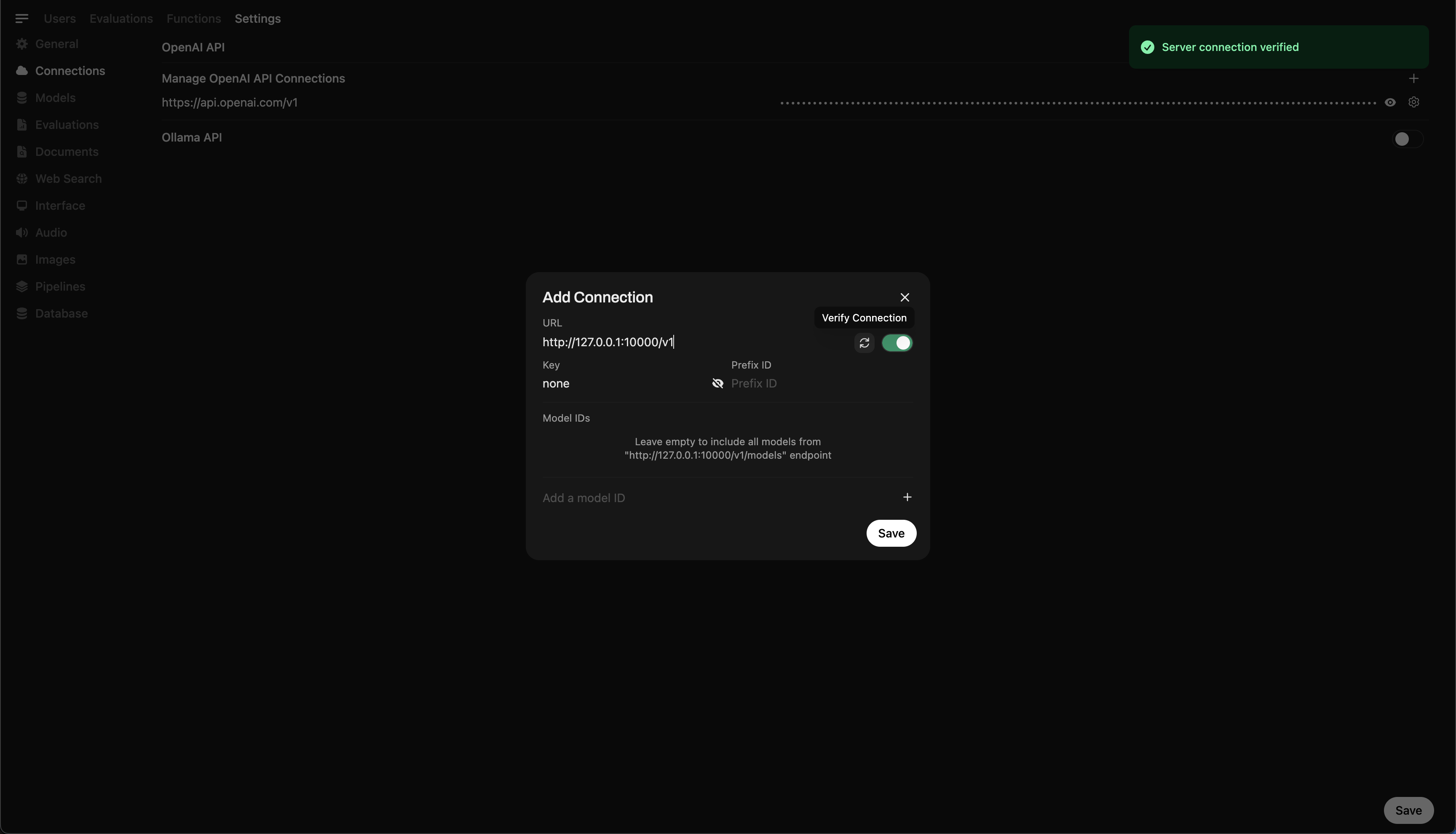
После выполнения команды вы должны увидеть сообщение, подтверждающее, что сервер активен и слушает порт 10000.
После сохранения подключения вы можете начинать выполнять запросы к DeepSeek-R1 прямо из Open WebUI! 🎉
Пример: Генерация ответов
Теперь вы можете использовать интерфейс чата Open WebUI для взаимодействия с моделью DeepSeek-R1 Dynamic 1.58-bit.
Замечания и рекомендации
-
Производительность: Запуск массивной модели объемом 131 ГБ, такой как DeepSeek-R1, на персональном оборудовании будет медленным. Даже с нашим M4 Max (128 ГБ ОЗУ) скорость вывода была умеренной. Но тот факт, что это вообще работает, является свидетельством оптимизаций UnslothAI.
-
Требования к VRAM/памяти: Убедитесь, что у вас достаточно VRAM и системной памяти для оптимальной производительности. С низкопроизводительными GPU или конфигурацией только на CPU ожидайте более низкой скорости (но это все еще возможно!).
Благодаря UnslothAI и Llama.cpp, запуск одной из крупнейших моделей open-source для рассуждений, DeepSeek-R1 (версия 1.58 бит), стал возможен для отдельных пользователей. Хотя запуск таких моделей на бытовом оборудовании является вызовом, возможность сделать это без массивной вычислительной инфраструктуры — это значительный технологический прорыв.
⭐ Огромное спасибо сообществу за продвижение границ открытых ИИ-исследований.
Удачных экспериментов! 🚀