🐋 Exécuter DeepSeek R1 Dynamic 1.58-bit avec Llama.cpp
Un grand merci à UnslothAI pour leurs efforts incroyables ! Grâce à leur travail acharné, nous pouvons désormais exécuter le modèle complet DeepSeek-R1 de 671 milliards de paramètres dans sa version quantifiée dynamique 1.58-bit (compressée à seulement 131 Go) sur Llama.cpp ! Et le mieux ? Vous n’avez plus besoin de désespérer de ne pas avoir des GPU ou serveurs de classe entreprise gigantesques — il est possible de faire fonctionner ce modèle sur votre ordinateur personnel (certes lentement pour la plupart du matériel grand public).
Le seul vrai modèle DeepSeek-R1 sur Ollama est la version 671B disponible ici : https://ollama.com/library/deepseek-r1:671b. Les autres versions sont des modèles distillés.
Ce guide se concentre sur l'exécution du modèle complet DeepSeek-R1 Dynamic quantifié en 1.58-bit en utilisant Llama.cpp intégré avec Open WebUI. Pour ce tutoriel, nous montrerons les étapes avec une machine M4 Max + 128 Go de RAM. Vous pouvez adapter les paramètres à votre propre configuration.
Étape 1 : Installer Llama.cpp
Vous pouvez soit :
- Télécharger les binaires précompilés
- Ou le construire vous-même : Suivez les instructions ici : Guide de construction de Llama.cpp
Étape 2 : Téléchargez le modèle fourni par UnslothAI
Rendez-vous sur la page Hugging Face d'Unsloth et téléchargez la version quantifiée dynamique appropriée de DeepSeek-R1. Pour ce tutoriel, nous utiliserons la version 1.58-bit (131 Go), qui est fortement optimisée mais reste étonnamment fonctionnelle.
Sachez où se trouve votre "répertoire de travail" — où votre script Python ou session terminal est en cours d'exécution. Les fichiers du modèle seront téléchargés dans un sous-dossier de ce répertoire par défaut, alors assurez-vous de connaître son chemin ! Par exemple, si vous exécutez la commande ci-dessous dans /Users/yourname/Documents/projects, votre modèle téléchargé sera sauvegardé sous /Users/yourname/Documents/projects/DeepSeek-R1-GGUF.
Pour en savoir plus sur le processus de développement d’UnslothAI et pourquoi ces versions quantifiées dynamiques sont si efficaces, consultez leur article de blog : UnslothAI DeepSeek R1 Dynamic Quantization.
Voici comment télécharger le modèle par programmation :
# Installez les dépendances Hugging Face avant d'exécuter ceci :
# pip install huggingface_hub hf_transfer
from huggingface_hub import snapshot_download
snapshot_download(
repo_id = "unsloth/DeepSeek-R1-GGUF", # Indiquer le dépôt Hugging Face
local_dir = "DeepSeek-R1-GGUF", # Le modèle sera téléchargé dans ce répertoire
allow_patterns = ["*UD-IQ1_S*"], # Télécharger uniquement la version 1.58-bit
)
Une fois le téléchargement terminé, vous trouverez les fichiers du modèle dans une structure de répertoires comme celle-ci :
DeepSeek-R1-GGUF/
├── DeepSeek-R1-UD-IQ1_S/
│ ├── DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf
│ ├── DeepSeek-R1-UD-IQ1_S-00002-of-00003.gguf
│ ├── DeepSeek-R1-UD-IQ1_S-00003-of-00003.gguf
🛠️ Mettez à jour les chemins dans les étapes ultérieures pour qu'ils correspondent à votre structure de répertoire spécifique. Par exemple, si votre script était dans /Users/tim/Downloads, le chemin complet vers le fichier GGUF serait :
/Users/tim/Downloads/DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf.
Étape 3 : Assurez-vous qu'Open WebUI est installé et en cours d'exécution
Si vous n'avez pas encore installé Open WebUI, pas de souci ! La configuration est simple. Il suffit de suivre la documentation d'Open WebUI ici. Une fois installé, démarrez l'application — nous la connecterons à une étape ultérieure pour interagir avec le modèle DeepSeek-R1.
Étape 4 : Servir le modèle en utilisant Llama.cpp
Maintenant que le modèle est téléchargé, l'étape suivante consiste à l'exécuter en utilisant le mode serveur de Llama.cpp. Avant de commencer :
-
Localisez le binaire
llama-server. Si vous avez construit à partir de la source (comme indiqué à l'étape 1), l'exécutablellama-serverse trouvera dansllama.cpp/build/bin. Naviguez vers ce répertoire en utilisant la commandecd:cd [path-to-llama-cpp]/llama.cpp/build/binRemplacez
[path-to-llama-cpp]par l’endroit où vous avez cloné ou construit Llama.cpp. Par exemple :cd ~/Documents/workspace/llama.cpp/build/bin -
Indiquez votre dossier de modèle. Utilisez le chemin complet vers les fichiers GGUF téléchargés créés à l'étape 2. Lors de la mise en service du modèle, spécifiez la première partie des fichiers GGUF divisés (par exemple,
DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf).
Voici la commande pour démarrer le serveur :
./llama-server \
--model /[your-directory]/DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
--port 10000 \
--ctx-size 1024 \
--n-gpu-layers 40
🔑 Paramètres à personnaliser en fonction de votre machine :
--model: Remplacez/[your-directory]/par le chemin où les fichiers GGUF ont été téléchargés à l'Étape 2.--port: Le port par défaut du serveur est8080, mais n'hésitez pas à le modifier en fonction de la disponibilité de vos ports.--ctx-size: Détermine la longueur du contexte (nombre de tokens). Vous pouvez l'augmenter si votre matériel le permet, mais faites attention à l'augmentation de l'utilisation de la RAM/VRAM.--n-gpu-layers: Définissez le nombre de couches que vous souhaitez décharger sur votre GPU pour une inférence plus rapide. Le nombre exact dépend de la capacité mémoire de votre GPU — consultez le tableau d'Unsloth pour des recommandations spécifiques.
Par exemple, si votre modèle a été téléchargé dans /Users/tim/Documents/workspace, votre commande ressemblerait à ceci :
./llama-server \
--model /Users/tim/Documents/workspace/DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
--port 10000 \
--ctx-size 1024 \
--n-gpu-layers 40
Une fois le serveur démarré, il hébergera un point de terminaison API local compatible OpenAI à :
http://127.0.0.1:10000
🖥️ Serveur Llama.cpp en cours d'exécution
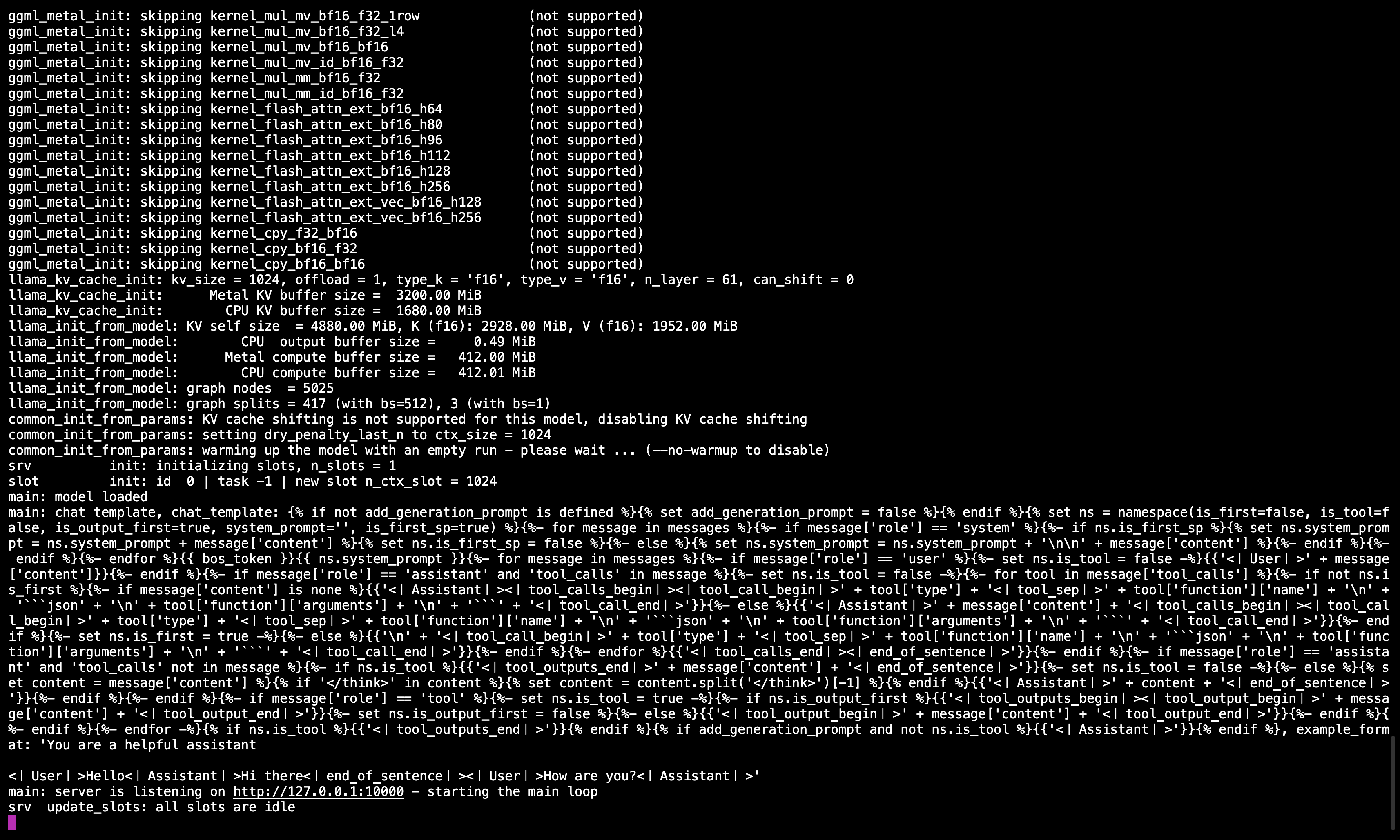
Après avoir exécuté la commande, vous devriez voir un message confirmant que le serveur est actif et à l'écoute sur le port 10000.
Assurez-vous de garder cette session terminal ouverte car elle sert le modèle pour toutes les étapes suivantes.
Étape 5 : Connecter Llama.cpp à Open WebUI�
- Accédez aux Paramètres Admin dans Open WebUI.
- Naviguez jusqu'à Connections > OpenAI Connections.
- Ajoutez les détails suivants pour la nouvelle connexion :
- URL :
http://127.0.0.1:10000/v1(ouhttp://host.docker.internal:10000/v1si vous utilisez Open WebUI via Docker) - Clé API :
none
- URL :
🖥️ Ajouter une connexion dans Open WebUI
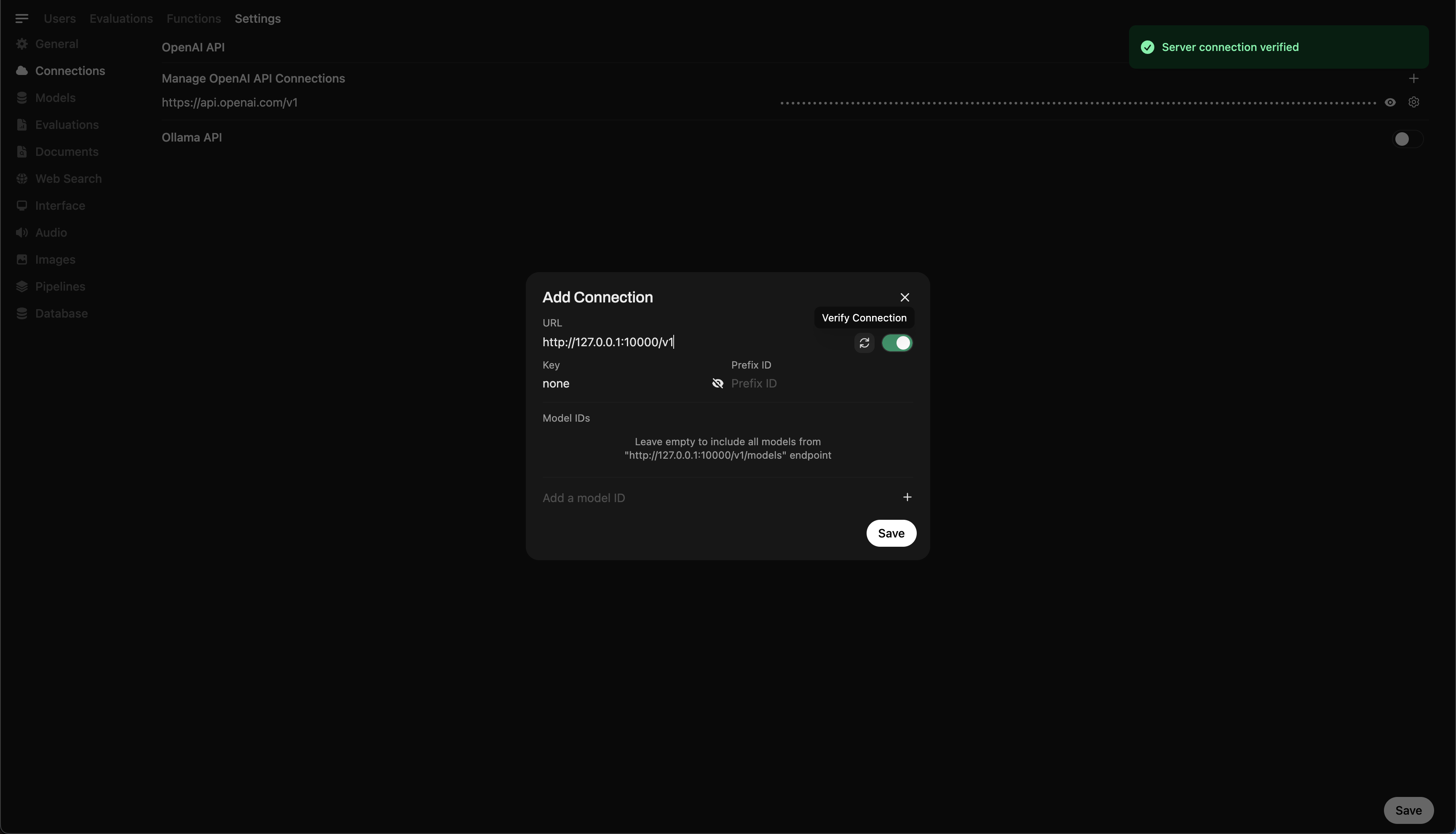
Après avoir exécuté la commande, vous devriez voir un message confirmant que le serveur est actif et à l'écoute sur le port 10000.
Une fois la connexion enregistrée, vous pouvez commencer à interroger DeepSeek-R1 directement depuis Open WebUI ! 🎉
Exemple : Génération de réponses
Vous pouvez désormais utiliser l'interface de discussion d'Open WebUI pour interagir avec le modèle DeepSeek-R1 Dynamic 1.58-bit.
Notes et considérations
-
Performance : Exécuter un modèle massif de 131 Go comme DeepSeek-R1 sur du matériel personnel sera lent. Même avec notre M4 Max (128 Go de RAM), les vitesses d'inférence étaient modestes. Mais le simple fait que cela fonctionne témoigne des optimisations d'UnslothAI.
-
Exigences VRAM/Mémoire : Assurez-vous de disposer de suffisamment de VRAM et de RAM système pour des performances optimales. Avec des GPU bas de gamme ou des configurations uniquement CPU, attendez-vous à des vitesses plus lentes (mais c'est toujours faisable !).
Grâce à UnslothAI et Llama.cpp, l'exécution de l'un des plus grands modèles de raisonnement open-source, DeepSeek-R1 (version 1,58-bit), est enfin accessible aux particuliers. Bien qu'il soit difficile de faire tourner de tels modèles sur du matériel grand public, la possibilité de le faire sans infrastructure informatique massive est un jalon technologique important.
⭐ Un grand merci à la communauté pour repousser les limites de la recherche en IA ouverte.
Bonnes expérimentations ! 🚀