🐋 使用 Llama.cpp 运行 DeepSeek R1 动态 1.58-bit
向 UnslothAI 表示极大的感谢!多亏了他们的努力,我们现在可以在 Llama.cpp 上运行 完整的 DeepSeek-R1 671B 参数模型的动态 1.58-bit 量化版本(压缩到仅 131GB)!最棒的是,你再也不用为需要大型企业级 GPU 或服务器而感到沮丧了 —— 现在可以在你的个人电脑上运行这个模型(尽管对于大多数消费级硬件来说速度较慢)。
Ollama 上唯一真正的 DeepSeek-R1 模型是这里提供的 671B 版本:https://ollama.com/library/deepseek-r1:671b。其他版本是 蒸馏模型。
本指南专注于使用 与 Open WebUI 集成的 Llama.cpp 运行 完整的 DeepSeek-R1 动态 1.58-bit 量化模型。在本教程中,我们将以一台 M4 Max + 128GB RAM 的机器为例,展示步骤。你可以根据自己的配置调整设置。
第一步:安装 Llama.cpp
你��可以选择:
- 下载预编译的二进制文件
- 或者自己构建:按照这里的说明操作:Llama.cpp 构建指南
第二步:下载由 UnslothAI 提供的模型
前往 Unsloth 的 Hugging Face 页面,下载适当的 动态量化版本 的 DeepSeek-R1。对于本教程,我们将使用 1.58-bit(131GB) 版本,这个版本经过高度优化但仍然出奇地高效。
了解你的“工作目录”——就是你的 Python 脚本或终端会话正在运行的地方。默认情况下,模型文件会下载到该目录的一个子文件夹,因此请确保你知道其路径!例如,如果你在 /Users/yourname/Documents/projects 下运行以下命令,下载的模型将保存到 /Users/yourname/Documents/projects/DeepSeek-R1-GGUF。
如果想了解更多关于 UnslothAI 的开发过程以及这些动态量化版本为何如此高效,请查看他们的博客文章:UnslothAI DeepSeek R1 动态量化。
以下是通过编程方式下载模型的方法:
# 在运行此代码之前,请安装 Hugging Face 相关依赖:
# pip install huggingface_hub hf_transfer
from huggingface_hub import snapshot_download
snapshot_download(
repo_id = "unsloth/DeepSeek-R1-GGUF", # 指定 Hugging Face 仓库
local_dir = "DeepSeek-R1-GGUF", # 模型将下载到此目录
allow_patterns = ["*UD-IQ1_S*"], # 仅下载 1.58-bit 版本
)
下载完成后,你会看到模型文件的目录结构如下:
DeepSeek-R1-GGUF/
├── DeepSeek-R1-UD-IQ1_S/
│ ├── DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf
│ ├── DeepSeek-R1-UD-IQ1_S-00002-of-00003.gguf
│ ├── DeepSeek-R1-UD-IQ1_S-00003-of-00003.gguf
🛠️ 在后续步骤中更新路径以 匹配你的特定目录结构。例如,如果你的脚本位于 /Users/tim/Downloads,则 GGUF 文件的完整路径将是:
/Users/tim/Downloads/DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf。
第三步:确保安装并运行 Open WebUI
如果你尚未安装 Open WebUI,不必担心!安装过程非常简单。按照 Open WebUI 文档 进行操作。安装完成后,启动应用程序——我们将在后续步骤中将其连接到 DeepSeek-R1 模型以进行交互。
第四步:使用 Llama.cpp 启动模型服务
现在模型已下载,下一步是通�过 Llama.cpp 的服务模式 运行它。在开始之前:
-
找到
llama-server二进制文件。 如果是从源码构建的(如步骤 1 所述),llama-server可执行文件将位于llama.cpp/build/bin中。使用cd命令导航到此目录:cd [path-to-llama-cpp]/llama.cpp/build/bin将
[path-to-llama-cpp]替换为你克隆或构建 Llama.cpp 的位置。例如:cd ~/Documents/workspace/llama.cpp/build/bin -
指向你的模型文件夹。 使用步骤 2 中下载的 GGUF 文件的完整路径。提供分割 GGUF 文件的第一部分(例如
DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf)。
以下是启动服务器的命令:
./llama-server \
--model /[your-directory]/DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
--port 10000 \
--ctx-size 1024 \
--n-gpu-layers 40
🔑 根据您的机器自定义参数:
--model: 将/[your-directory]/替换为步骤 2 中下载 GGUF 文件的路径。--port: 服务器默认端口是8080,但可以根据您的端口可用性进行更改。--ctx-size: 确定上下文长度(令牌数量)。如果硬件允许,可以增加此值,但需注意 RAM/VRAM 使用量上升。--n-gpu-layers: 设置要卸载到 GPU 上以加速推理的层数。确切数量取决于 GPU 的内存容量 — 请参考 Unsloth 的表格以获取具体建议。
例如,如果您的模型下载到 /Users/tim/Documents/workspace,您的命令将如下所示:
./llama-server \
--model /Users/tim/Documents/workspace/DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
--port 10000 \
--ctx-size 1024 \
--n-gpu-layers 40
一旦服务器启动,它将在以下位置托管一个本地 OpenAI 兼容 API 端点:
http://127.0.0.1:10000
🖥️ Llama.cpp 服务器正在运行
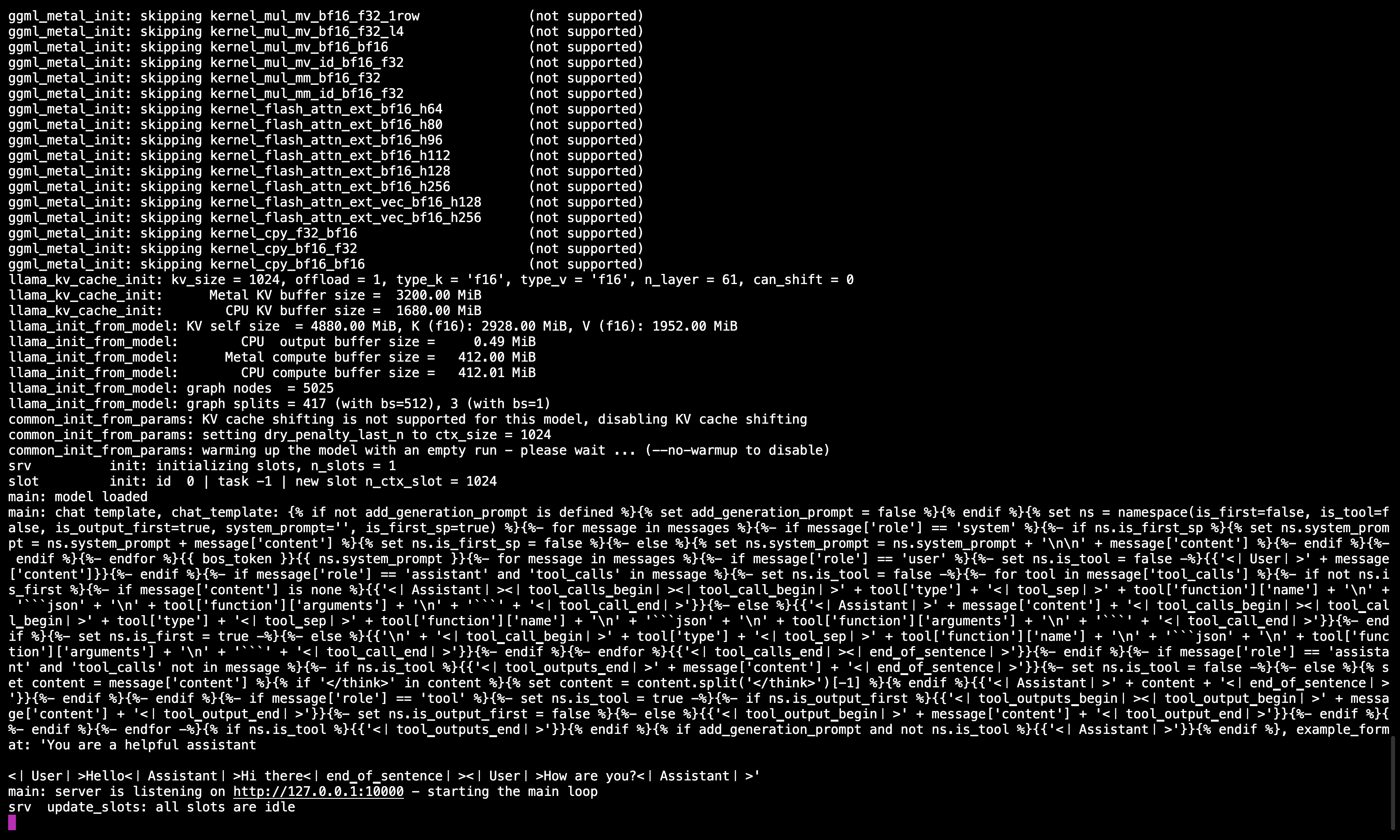
运行命令后,您应该会看到一个消息,确认服务器已启动并正在监听端口 10000。
请确保保持这个终端会话运行,因为它为后续的所有步骤提供模型服务。
第 5 步:将 Llama.cpp 连接到 Open WebUI
- 前往 Open WebUI 的 管理设置。
- 转到 连接 > OpenAI 连接�。
- 为新连接添加以下详细信息:
- URL:
http://127.0.0.1:10000/v1(或者当在 docker 中运行 Open WebUI 时,使用http://host.docker.internal:10000/v1) - API 密钥:
none
- URL:
🖥️ 在 Open WebUI 中添加连接
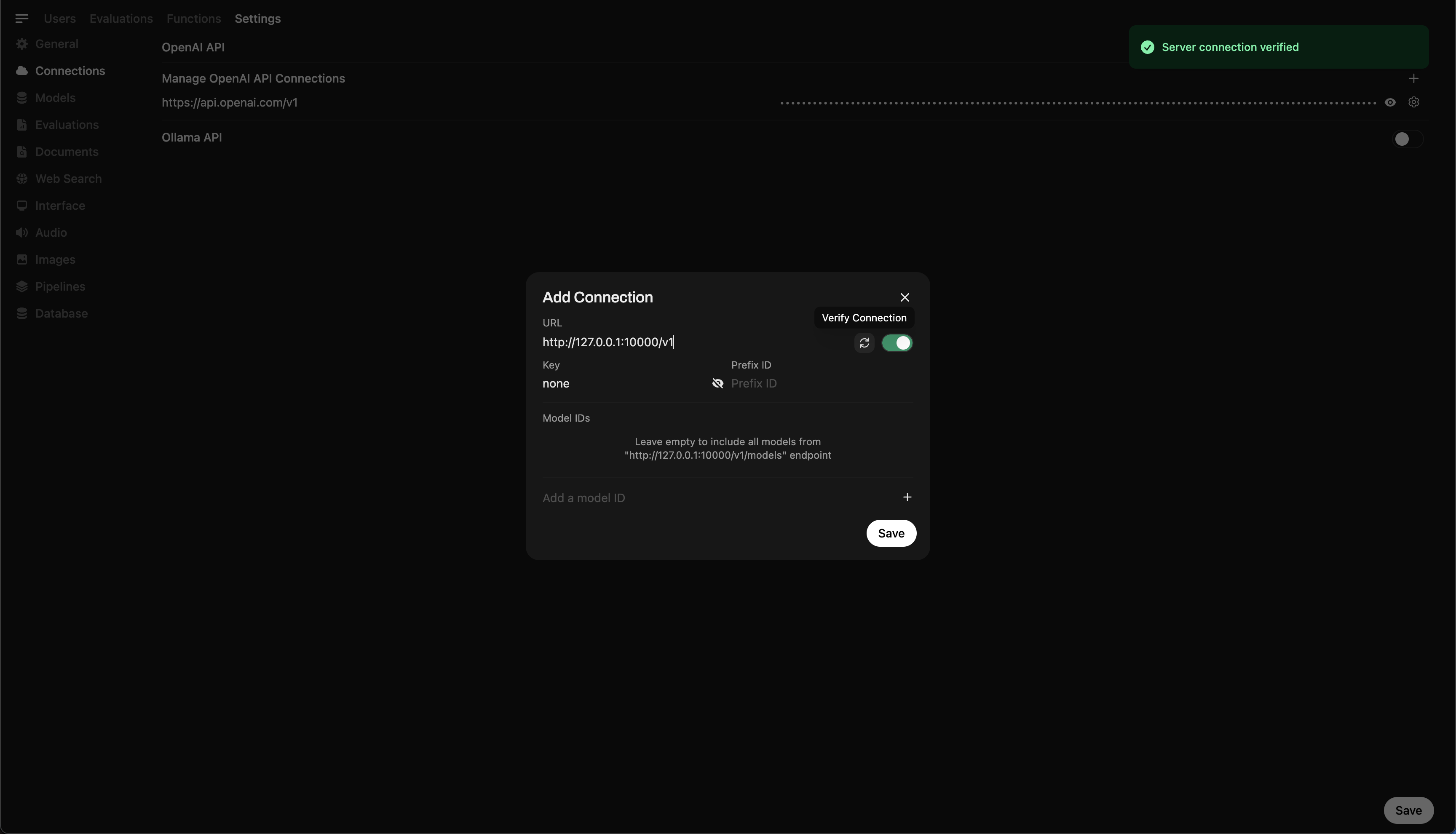
保存后,您应看到服务器已启动并正在监听端口 10000 的确认信息。
一旦连接保存,您就可以直接从 Open WebUI 开始查询 DeepSeek-R1 了! 🎉
示例:生成回复
现在,您可以使用 Open WebUI 的聊天界面与DeepSeek-R1 动态 1.58 位模型互动。
注意事项
-
性能: 在个人硬件上运行 131GB 的大�型模型 DeepSeek-R1 会非常缓慢。即使使用我们的 M4 Max(128GB 内存),推理速度也较为一般。但它的可行性证明了 UnslothAI 的优化效果。
-
VRAM/内存要求: 确保有足够的 VRAM 和系统内存以获得最佳性能。在低端 GPU 或仅使用 CPU 的设置中,请预期其速度会更慢(但仍然可行!)。
感谢 UnslothAI 和 Llama.cpp,终于让运行这一最大开源推理模型之一的 DeepSeek-R1(1.58 位版本)成为个人可能实现的任务。尽管在消费级硬件上运行这些模型具有挑战性,但能够在没有庞大的计算基础设施的情况下实现这一点是一项重大的技术里程碑。
⭐ 特别感谢社区推动开源 AI 研究的边界。
祝您测试愉快!🚀