此教學為社群貢獻,並未由 Open WebUI 團隊支援。僅作為自訂 Open WebUI 以符合您特定用例的示範。如果有意貢獻,請參考貢獻教學。
本指南已使用 手動安裝 設置的 Open WebUI 進行驗證。
使用 IPEX-LLM 在 Intel GPU 上設定本地 LLM
IPEX-LLM 是一個基於 PyTorch 的庫,用於在 Intel 的 CPU 和 GPU(例如:配備 iGPU 的本地電腦、Arc A 系列、Flex 和 Max 等獨立 GPU)上以非常低的延遲運行 LLM。
本教學展示如何使用 IPEX-LLM 加速的 Ollama 後端並託管於 Intel GPU 上 設置 Open WebUI。通過遵循本指南,即使僅在低成本的電腦(例如僅配備集成 GPU)上,您也能獲得流暢的使用體驗。
在 Intel GPU 上啟動 Ollama Serve
請參考 IPEX-LLM 官方文檔的 此指南,了解如何安裝和運行由 IPEX-LLM 加速並在 Intel GPU 上執行的 Ollama Serve。
如果您希望從其他設備訪問 Ollama 服務,請在執行指令 ollama serve 前,確保設置或輸出環境變數 OLLAMA_HOST=0.0.0.0。
配置 Open WebUI
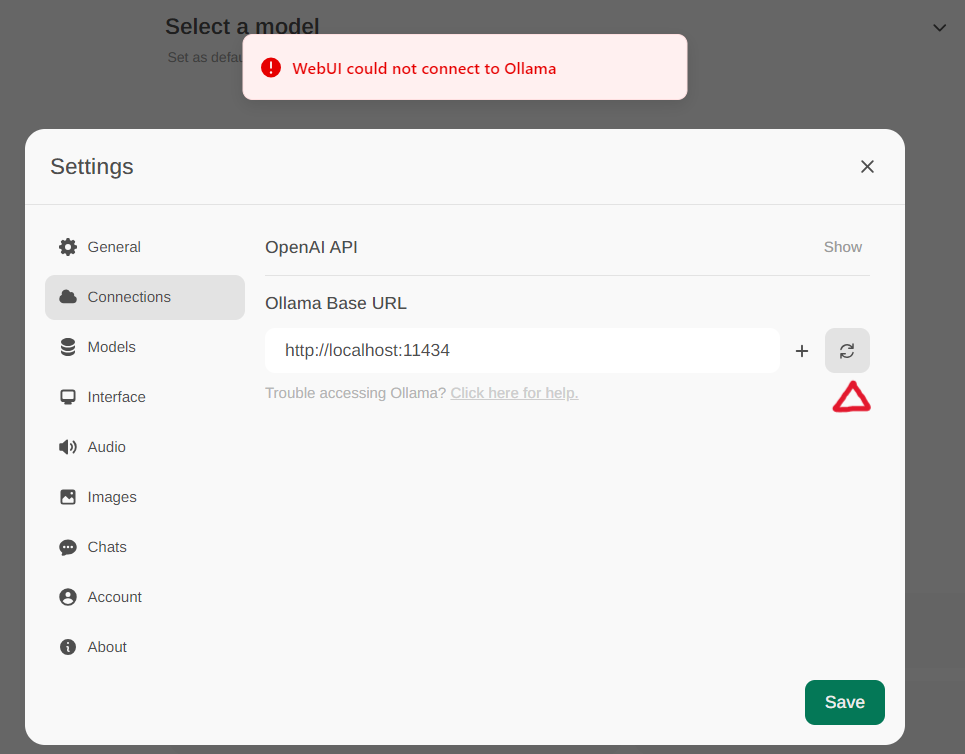
通過選單中的 設定 -> 連接 訪問 Ollama 設置。預設情況下,Ollama 基本 URL 被設置為 https://localhost:11434,如下圖所示。要驗證 Ollama 服務連接狀態,請點擊文本框旁邊的 刷新按鈕。如果 WebUI 無法與 Ollama 服務器建立連接,您將看到錯誤消息 WebUI could not connect to Ollama。
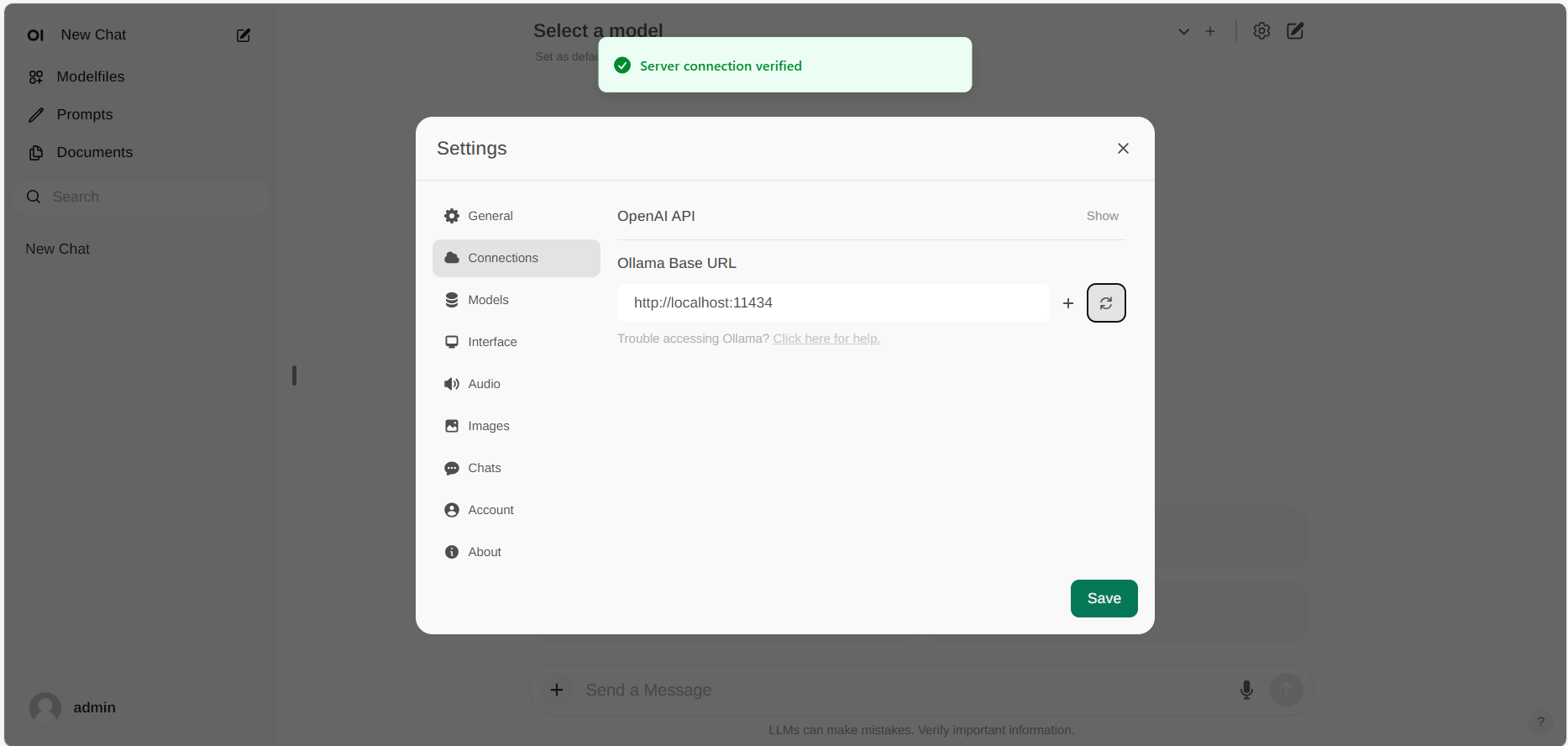
如果連接成功,您將看到消息 Service Connection Verified,如下圖所示。
如果您希望使用其他 URL 託管的 Ollama 服務器,只需將 Ollama 基本 URL 更新為新 URL 並按 刷新按鈕 重新確認與 Ollama 的連接。