🦙Llama.cppを始めよう
概要
Open WebUIを使用す��ると、ローカルのLlama.cppサーバーを簡単かつ柔軟に接続して効率的で量子化された言語モデルを実行できます。このガイドでは、Llama.cppを自分でコンパイルした場合でも、または事前にコンパイルされたバイナリを使用している場合でも、以下の手順を説明します:
- Llama.cppサーバーのセットアップ
- 大規模なモデルをローカルでロード
- シームレスなインターフェースのためのOpen WebUIとの統合
さあ、始めましょう!
ステップ 1: Llama.cppをインストールする
Llama.cppを使用してモデルを実行するには、まずローカルにLlama.cppサーバーをインストールする必要があります。
以下のいずれかを選択してください:
- 📦 事前に構築されたバイナリをダウンロードする
- 🛠️ または公式ビルド手順に従ってソースからビルドする
インストール後、llama-serverがローカルシステムのパスで利用可能なことを確認するか、またはその場所をメモしておいてください。
ステップ 2: サポートされるモデルをダウンロードする
Llama.cppを使用して、さまざまなGGUF形式の量子化されたLLMをロードして実行できます。一例として、UnslothAIが最適化したDeepSeek-R1 1.58ビットモデルがあります。このバージョンをダウンロードするには:
- Hugging FaceのUnsloth DeepSeek-R1リポジトリにアクセスします。
- 1.58ビット量子化バージョンをダウンロードします(約131GB)。
あるいは、Pythonを使用してプログラムでダウンロードすることもできます:
# pip install huggingface_hub hf_transfer
from huggingface_hub import snapshot_download
snapshot_download(
repo_id = "unsloth/DeepSeek-R1-GGUF",
local_dir = "DeepSeek-R1-GGUF",
allow_patterns = ["*UD-IQ1_S*"], # 1.58ビットバリアントのみをダウンロード
)
これにより、モデルファイルが次のようなディレクトリにダウンロードされます:
DeepSeek-R1-GGUF/
└── DeepSeek-R1-UD-IQ1_S/
├── DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf
├── DeepSeek-R1-UD-IQ1_S-00002-of-00003.gguf
└── DeepSeek-R1-UD-IQ1_S-00003-of-00003.gguf
📍 最初のGGUFファイルへのフルパスをメモしておいてください—ステップ3で必要になります。
ステップ 3: Llama.cppでモデルを提供する
モデルサーバーを起動するには、llama-serverバイナリを使用します。llama.cppフォルダ(例: build/bin)に移動し、以下を実行します:
./llama-server \
--model /your/full/path/to/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
--port 10000 \
--ctx-size 1024 \
--n-gpu-layers 40
🛠️ マシンに応じてパラメーターを調整してください:
- --model: .ggufモデルファイルのパス
- --port: 10000(または別の空いているポートを選択)
- --ctx-size: トークンコンテキスト長(RAMが許す場合は増加可能)
- --n-gpu-layers: GPUにオフロードするレイヤー数(パフォーマンス向上)
サーバーが実行されると、次のローカルOpenAI互換APIが公開されます:
http://127.0.0.1:10000
ステッ�プ 4: Llama.cppをOpen WebUIに接続する
Open WebUIから直接ローカルで実行中のモデルを制御およびクエリするには:
- ブラウザでOpen WebUIを開く
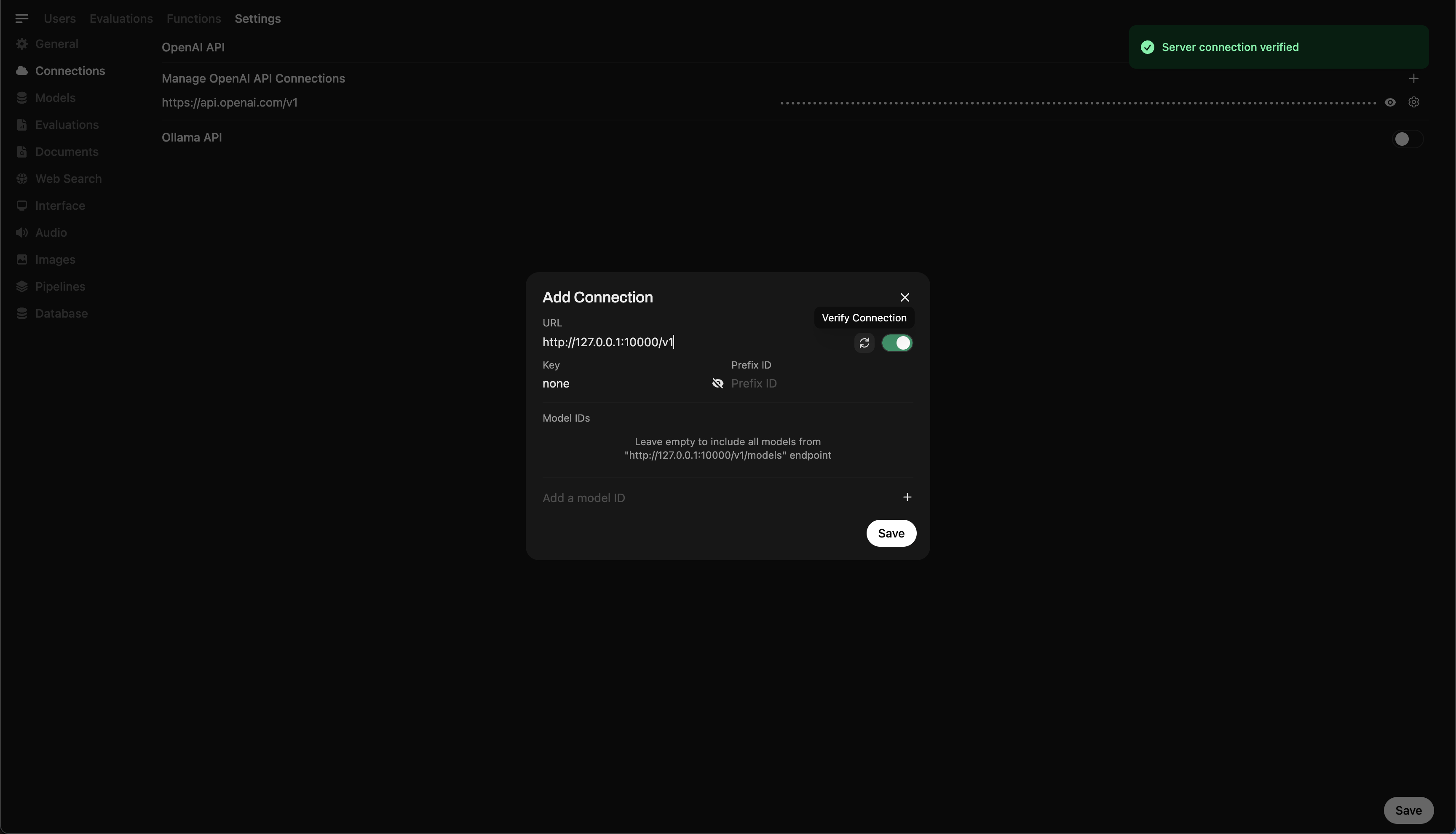
- ⚙️ 管理設定 → 接続 → OpenAI接続に移動
- ➕ 接続を追加 をクリックして次を入力:
- URL:
http://127.0.0.1:10000/v1
(WebUIをDocker内で実行している場合はhttp://host.docker.internal:10000/v1を使用) - APIキー:
none(空のままにする)
💡 保存後、Open WebUIはローカルのLlama.cppサーバーをバックエンドとして使用し始めます!
ワンポイント: チャットインターフェースを使ってモデルを試す
接続後、Open WebUIのチャットメニューからモデルを選択してインタラクションを開始しましょう!
準備完了です!
設定が完了したら、Open WebUIを使用して以下が簡単に行えます:
- Llama.cppが提供するローカルモデルの管理および切り替え
- APIキー不要のOpenAI互換APIの利用
- DeepSeek-R1のような大規模モデルを手元のマシンで試す
🚀 楽しんで実験し、構築してください!