🦙Начало работы с Llama.cpp
Обзор
Open WebUI делает процесс подключения и управления локальным сервером Llama.cpp простым и гибким, позволяя запускать эффективные, квантованные языковые модели. Независимо от того, компилировали вы Llama.cpp самостоятельно или используете предварительно скомпилированные двоичные файлы, это руководство поможет вам:
- Настроить сервер Llama.cpp
- Загружать крупные модели локально
- Интегрироваться с Open WebUI для удобного интерфейса
Давайте начнем!
Шаг 1: Установите Llama.cpp
Для запуска моделей с помощью Llama.cpp сначала необходимо установить сервер Llama.cpp локально.
Вы можете:
- 📦 Скачать предварительно собранные файлы
- 🛠️ Или собрать его из исходного кода, следуя официальным инструкциям по сборке
После установки убедитесь, что llama-server доступен в системном пути или запишите его расположение.
Шаг 2: Загрузите поддерживаемую модель
С помощью Llama.cpp можно загружать и запускать различные квантованные языковые модели в формате GGUF. Один впечатляющий пример – модель DeepSeek-R1 с глубиной квантования 1.58 бита, оптимизированная UnslothAI. Чтобы скачать эту модель:
- Перейдите в репозиторий Unsloth DeepSeek-R1 на Hugging Face
- Скачайте квантованную версию с глубиной 1.58 бита – размер около 131GB.
Или загрузите программно с помощью Python:
# pip install huggingface_hub hf_transfer
from huggingface_hub import snapshot_download
snapshot_download(
repo_id = "unsloth/DeepSeek-R1-GGUF",
local_dir = "DeepSeek-R1-GGUF",
allow_patterns = ["*UD-IQ1_S*"], # Скачивание только варианта с глубиной квантования 1.58 бита
)
Файлы модели будут скачаны в каталог, подобный:
DeepSeek-R1-GGUF/
└── DeepSeek-R1-UD-IQ1_S/
├── DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf
├── DeepSeek-R1-UD-IQ1_S-00002-of-00003.gguf
└── DeepSeek-R1-UD-IQ1_S-00003-of-00003.gguf
📍 Запишите полный путь к первому файлу GGUF — он понадобится в шаге 3.
Шаг 3: Запустите модель с помощью Llama.cpp
Запустите сервер модели с помощью двоичного файла llama-server. Перейдите в папку llama.cpp (например, build/bin) и выполните команду:
./llama-server \
--model /ваш/полный/путь/к/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
--port 10000 \
--ctx-size 1024 \
--n-gpu-layers 40
🛠️ Настройте параметры в соответствии с вашей системой:
- --model: Путь к вашему файлу .gguf
- --port: 10000 (или выберите другой свободный порт)
- --ctx-size: Длина контекста токенов (может быть увеличена при наличии достаточного объема оперативной памяти)
- --n-gpu-layers: Слои, перенесенные на GPU для повышения производительности
По�сле запуска сервер предоставит локальный API, совместимый с OpenAI, по адресу:
http://127.0.0.1:10000
Шаг 4: Подключение Llama.cpp к Open WebUI
Чтобы управлять запущенной моделью и отправлять запросы прямо из Open WebUI:
- Откройте Open WebUI в вашем браузере
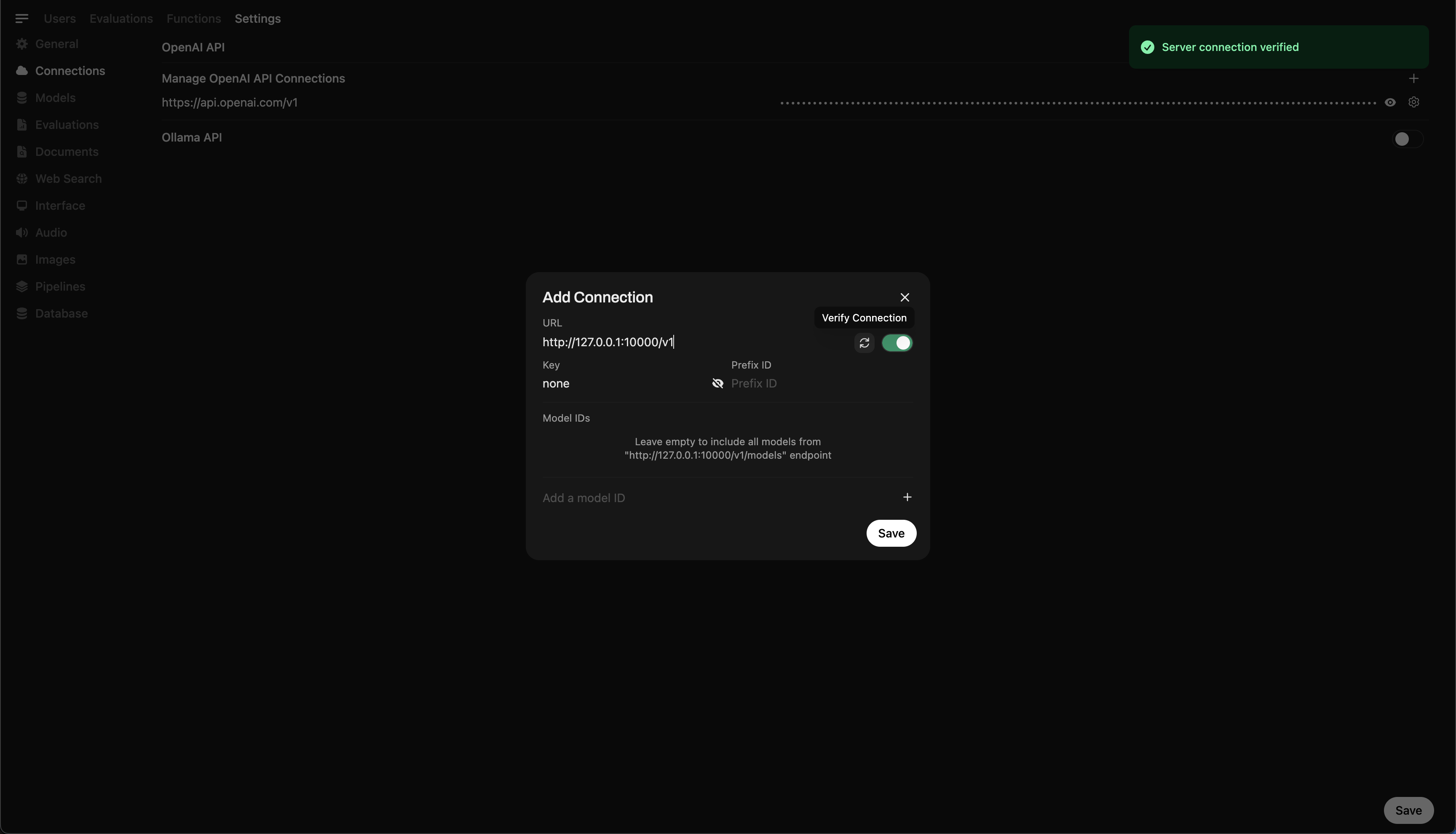
- Перейдите в ⚙️ Настройки администратора → Соединения → Соединения OpenAI
- Нажмите ➕ Добавить соединение и введите:
- URL:
http://127.0.0.1:10000/v1
(Или используйтеhttp://host.docker.internal:10000/v1, если запускаете WebUI в Docker) - API Key:
none(оставьте поле пустым)
💡 После сохранения Open WebUI начнет использовать ваш локальный сервер Llama.cpp как бэкенд!
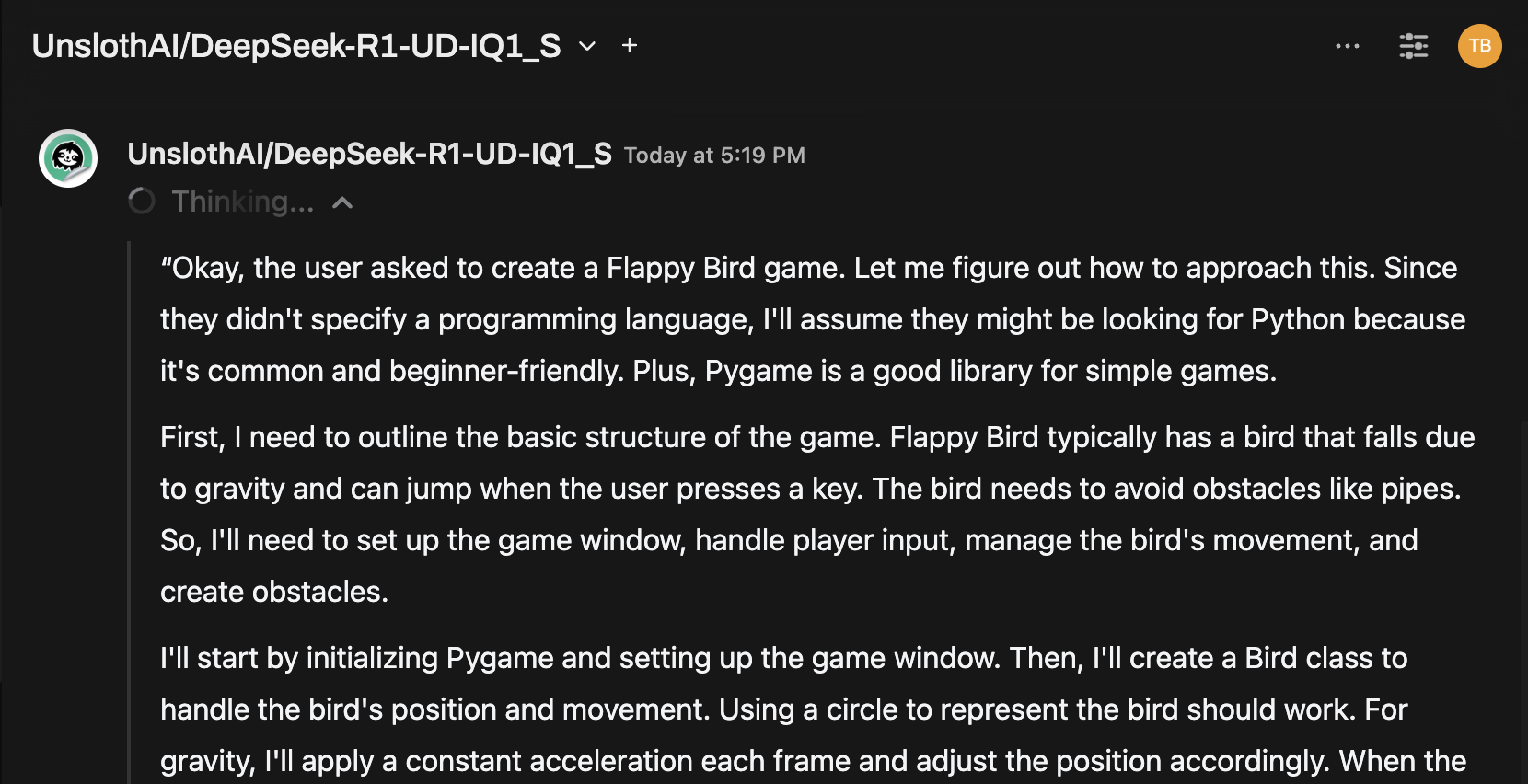
Быстрая подсказка: протестируйте модель через интерфейс чата
После подключения выберите модель в меню чата Open WebUI и начните взаимодействие!
Вы готовы к работе!
После настройки Open WebUI позволит вам легко:
- Управлять и переключаться между локальными моделями, запущенными через Llama.cpp
- Использовать API, совместимый с OpenAI, без необходимости ввода ключа
- Экспериментировать с крупными моделями, такими как DeepSeek-R1 — прямо на вашем компьютере!
🚀 Наслаждайтесь экспериментами и разработкой!