🦙Comenzando con Llama.cpp
Resumen
Open WebUI lo hace simple y flexible para conectar y gestionar un servidor local de Llama.cpp para ejecutar modelos de lenguaje eficientes y cuantificados. Ya sea que hayas compilado Llama.cpp tú mismo o que estés usando binarios precompilados, esta guía te guiará a través de cómo:
- Configurar tu servidor Llama.cpp
- Cargar grandes modelos localmente
- Integrar con Open WebUI para una interfaz fluida
¡Empecemos!
Paso 1: Instalar Llama.cpp
Para ejecutar modelos con Llama.cpp, primero necesitas instalar el servidor Llama.cpp localmente.
Puedes:
- 📦 Descargar binarios precompilados
- 🛠️ O compilarlo desde el código fuente siguiendo las instrucciones oficiales de compilación
Después de instalar, asegúrate de que llama-server esté disponible en tu ruta del sistema local o toma nota de su ubicación.
Paso 2: Descargar un Modelo Compatible
Puedes cargar y ejecutar varios modelos LLM cuantificados en formato GGUF usando Llama.cpp. Un ejemplo impresionante es el modelo DeepSeek-R1 optimizado a 1.58 bits por UnslothAI. Para descargar esta versión:
- Visita el repositorio Unsloth DeepSeek-R1 en Hugging Face
- Descarga la versión cuantificada de 1.58 bits (aproximadamente 131GB).
Alternativamente, usa Python para descargarlo programáticamente:
# pip install huggingface_hub hf_transfer
from huggingface_hub import snapshot_download
snapshot_download(
repo_id = "unsloth/DeepSeek-R1-GGUF",
local_dir = "DeepSeek-R1-GGUF",
allow_patterns = ["*UD-IQ1_S*"], # Descargar solo la variante de 1.58 bits
)
Esto descargará los archivos del modelo en un directorio como:
DeepSeek-R1-GGUF/
└── DeepSeek-R1-UD-IQ1_S/
├── DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf
├── DeepSeek-R1-UD-IQ1_S-00002-of-00003.gguf
└── DeepSeek-R1-UD-IQ1_S-00003-of-00003.gguf
📍 Toma nota de la ruta completa al primer archivo GGUF, lo necesitarás en el Paso 3.
Paso 3: Servir el Modelo con Llama.cpp
Inicia el servidor del modelo usando el binario llama-server. Navega a tu carpeta llama.cpp (por ejemplo, build/bin) y ejecuta:
./llama-server \
--model /ruta/completa/al/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
--port 10000 \
--ctx-size 1024 \
--n-gpu-layers 40
🛠️ Ajusta los parámetros para adaptarlos a tu máquina:
- --model: Ruta al archivo .gguf del modelo
- --port: 10000 (o elige otro puerto abierto)
- --ctx-size: Longitud del contexto de tokens (puede aumentar si la RAM lo permite)
- --n-gpu-layers: Capas transferidas a la GPU para un rendimiento más rápido
Una vez que el servidor esté en ejecución, expondrá una API local compatible con OpenAI en:
http://127.0.0.1:10000
Paso 4: Conectar Llama.cpp a Open WebUI
Para controlar y consultar tu modelo ejecutándose localmente directamente desde Open WebUI:
- Abre Open WebUI en tu navegador
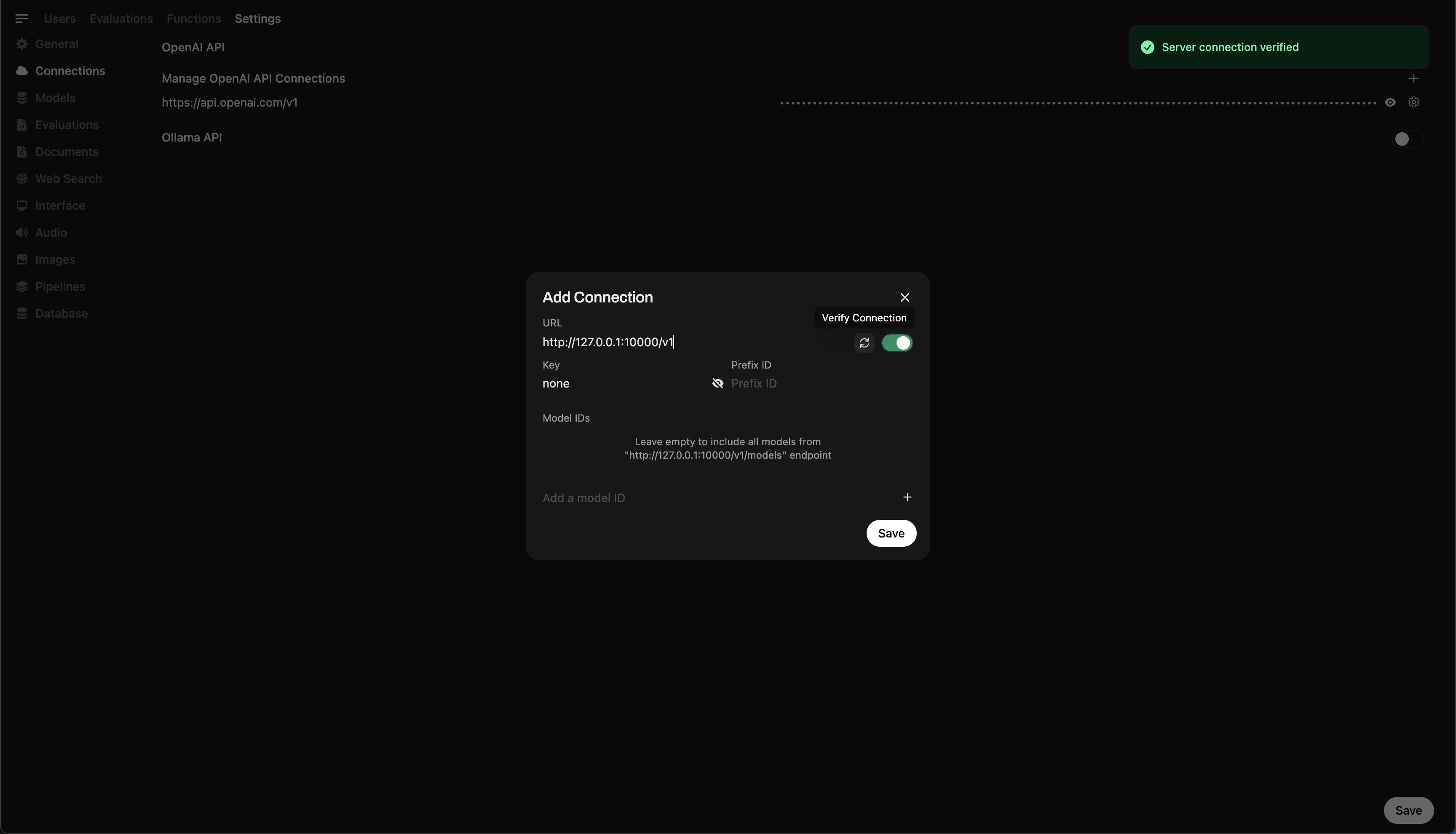
- Ve a ⚙️ Configuración de Administración → Conexiones → Conexiones OpenAI
- Haz clic en ➕ Agregar conexión e ingresa:
- URL:
http://127.0.0.1:10000/v1
(O usahttp://host.docker.internal:10000/v1si estás ejecutando WebUI dentro de Docker) - API Key:
none(déjalo en blanco)
💡 Una vez guardado, Open WebUI comenzará a usar tu servidor local de Llama.cpp como backend.
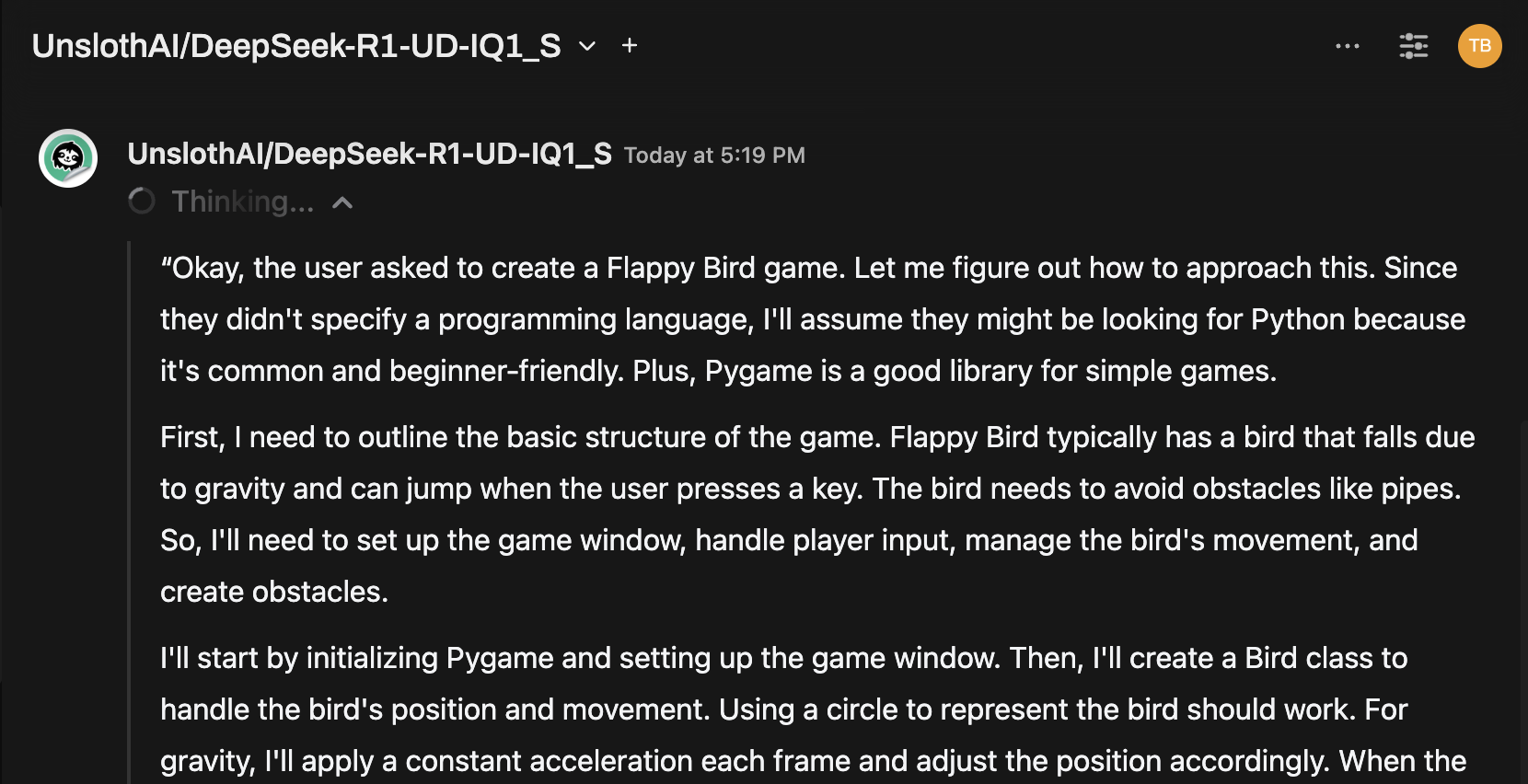
Consejo Rápido: Prueba el Modelo a través de la Interfaz de Chat
Una vez conectado, selecciona el modelo desde el menú de chat de Open WebUI y comienza a interactuar.
¡Estás Listo para Comenzar!
Una vez configurado, Open WebUI hace que sea fácil:
- Gestionar y alternar entre modelos locales servidos por Llama.cpp
- Usar la API compatible con OpenAI sin necesidad de clave
- Experimentar con modelos masivos como DeepSeek-R1, ¡directamente desde tu máquina!
🚀 ¡Diviértete experimentando y construyendo!