🦙Começando com Llama.cpp
Visão Geral
Open WebUI torna simples e flexível conectar e gerenciar um servidor local Llama.cpp para executar modelos de linguagem eficientes e quantificados. Seja você compilando Llama.cpp por conta própria ou usando binários pré-compilados, este guia irá orientá-lo sobre como:
- Configurar seu servidor Llama.cpp
- Carregar modelos grandes localmente
- Integrar com Open WebUI para uma interface perfeita
Vamos começar!
Etapa 1: Instalar o Llama.cpp
Para executar modelos com Llama.cpp, você primeiro precisa instalar o servidor Llama.cpp localmente.
Você pode:
- 📦 Baixar binários pré-compilados
- 🛠️ Ou compilá-lo a partir do código-fonte seguindo as instruções oficiais de compilação
Após a instalação, certifique-se de que llama-server está disponível no caminho local do sistema ou anote sua localização.
Etapa 2: Baixar um Modelo Suportado
Você pode carregar e executar vários LLMs quantificados no formato GGUF usando Llama.cpp. Um exemplo impressionante é o modelo DeepSeek-R1 1.58-bit otimizado pela UnslothAI. Para baixar esta versão:
- Visite o repositório Unsloth DeepSeek-R1 no Hugging Face
- Baixe a versão quantificada de 1.58-bit – cerca de 131GB.
Alternativamente, use Python para baixar programaticamente:
# pip install huggingface_hub hf_transfer
from huggingface_hub import snapshot_download
snapshot_download(
repo_id = "unsloth/DeepSeek-R1-GGUF",
local_dir = "DeepSeek-R1-GGUF",
allow_patterns = ["*UD-IQ1_S*"], # Baixar apenas a variante de 1.58-bit
)
Isso irá baixar os arquivos do modelo para um diretório como:
DeepSeek-R1-GGUF/
└── DeepSeek-R1-UD-IQ1_S/
├── DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf
├── DeepSeek-R1-UD-IQ1_S-00002-of-00003.gguf
└── DeepSeek-R1-UD-IQ1_S-00003-of-00003.gguf
📍 Anote o caminho completo para o primeiro arquivo GGUF — você precisará dele na Etapa 3.
Etapa 3: Servir o Modelo com Llama.cpp
Inicie o servidor de modelos usando o binário llama-server. Navegue até sua pasta do Llama.cpp (por exemplo, build/bin) e execute:
./llama-server \
--model /seu/caminho/completo/para/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
--port 10000 \
--ctx-size 1024 \
--n-gpu-layers 40
🛠️ Ajuste os parâmetros para atender às necessidades de sua máquina:
- --model: Caminho para o arquivo de modelo .gguf
- --port: 10000 (ou escolha outra porta aberta)
- --ctx-size: Comprimento do contexto de token (pode aumentar se tiver RAM suficiente)
- --n-gpu-layers: Camadas descarregadas para GPU para desempenho mais rápido
Uma vez que o servidor esteja em execução, ele exporá uma API local compatível com OpenAI em:
http://127.0.0.1:10000
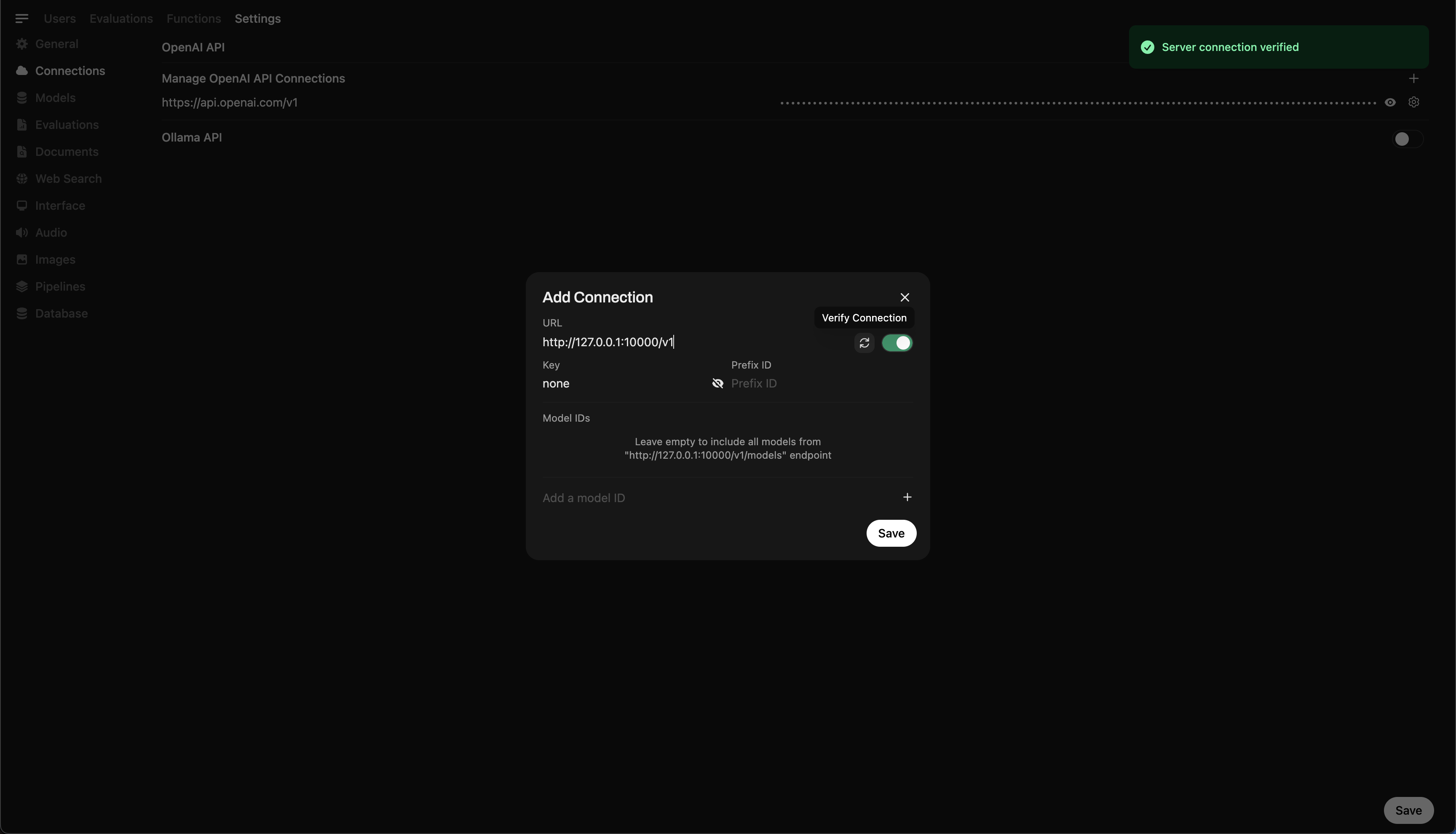
Etapa 4: Conectar Llama.cpp ao Open WebUI
Para controlar e consultar seu modelo em execução localmente diretamente do Open WebUI:
- Abra o Open WebUI no seu navegador
- Vá para ⚙️ Configurações Administrativas → Conexões → Conexões OpenAI
- Clique em ➕ Adicionar Conexão e insira:
- URL:
http://127.0.0.1:10000/v1
(Ou usehttp://host.docker.internal:10000/v1se estiver executando o WebUI dentro do Docker) - API Key:
none(deixe em branco)
💡 Uma vez salvo, o Open WebUI começará a usar seu servidor local Llama.cpp como backend!
Dica Rápida: Experimente o Modelo através da Interface de Chat
Uma vez conectado, selecione o modelo no menu de chat do Open WebUI e comece a interagir!
Você Está Pronto para Começar!
Depois de configurado, o Open WebUI facilita:
- Gerenciar e alternar entre modelos locais servidos pelo Llama.cpp
- Usar a API compatível com OpenAI sem precisar de uma chave
- Experimentar modelos massivos como o DeepSeek-R1 — diretamente do seu computador!
🚀 Divirta-se experimentando e construindo!