🦙開始使用 Llama.cpp
概覽
Open WebUI 讓連接並管理本地 Llama.cpp 伺服器來運行高效的量化語言模型變得簡單且靈活。無論您自己編譯了 Llama.cpp 還是使用預編譯二進制文件��,本指南將引導您完成以下操作:
- 設置您的 Llama.cpp 伺服器
- 在本地載入大型模型
- 與 Open WebUI 集成以獲得無縫介面
讓我們開始吧!
步驟 1:安裝 Llama.cpp
要使用 Llama.cpp 運行模型,首先需要在本地安裝 Llama.cpp 伺服器。
您可以選擇以下方式:
- 📦 下載預編譯二進制文件
- 🛠️ 或按照官方編譯指導從源碼進行編譯
安裝完成後,確保 llama-server 在您的本地系統路徑中可用,或者記下它的位置。
步驟 2:下載支持的模型
您可以使用 Llama.cpp 載入並運行各種 GGUF 格式的量化大型語言模型。例如,由 UnslothAI 優化的 DeepSeek-R1 1.58-bit 模型是一個很好的選擇。下載此版本的方法:
- 訪問 Hugging Face 上的 Unsloth DeepSeek-R1 資源庫
- 下載 1.58-bit 量化版本 — 大約 131GB。
或者,使用 Python 編程式下載:
# pip install huggingface_hub hf_transfer
from huggingface_hub import snapshot_download
snapshot_download(
repo_id = "unsloth/DeepSeek-R1-GGUF",
local_dir = "DeepSeek-R1-GGUF",
allow_patterns = ["*UD-IQ1_S*"], # 僅下載 1.58-bit 版本
)
這將把模型文件下載到如下目錄:
DeepSeek-R1-GGUF/
└── DeepSeek-R1-UD-IQ1_S/
├── DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf
├── DeepSeek-R1-UD-IQ1_S-00002-of-00003.gguf
└── DeepSeek-R1-UD-IQ1_S-00003-of-00003.gguf
📍 記下第一個 GGUF 文件的完整路徑 — 您在步驟 3 中會需要它。
步驟 3:使用 Llama.cpp 執行模型
使用 llama-server 二進制文件啟動模型伺服器。進入您的 Llama.cpp 文件夾 (例如 build/bin) 並運行:
./llama-server \
--model /your/full/path/to/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
--port 10000 \
--ctx-size 1024 \
--n-gpu-layers 40
🛠️ 根據您的機器調整這些參數:
- --model:您的 .gguf 模型文件的路徑
- --port:10000 (或選擇其他開放端口)
- --ctx-size:Token 上下文長度 (如果 RAM 允許,可以增加)
- --n-gpu-layers:卸載到 GPU 的層數以提高性能
伺服器啟動後,它將通過以下本地 OpenAI 兼容 API 進行訪問:
http://127.0.0.1:10000
步驟 4:將 Llama.cpp 連接到 Open WebUI
要直接從 Open WebUI 控制並查詢您的本地運行模型:
- 在瀏覽器中打開 Open WebUI
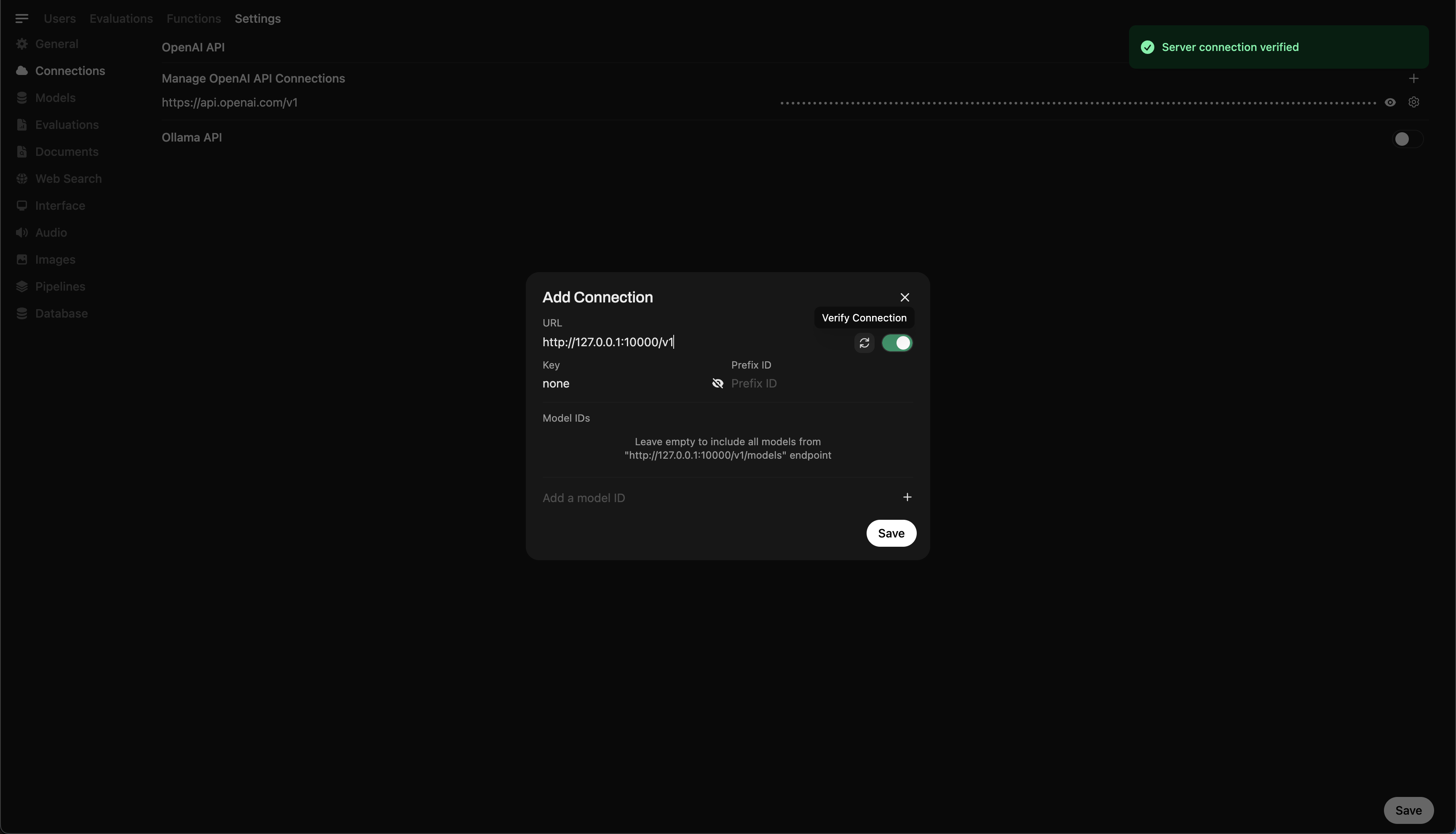
- 進入 ⚙️ 管理設置 → 連接 → OpenAI 連接
- 點擊 ➕ 添加連接並輸入以下信息:
- URL:
http://127.0.0.1:10000/v1
(如果在 Docker 中運行 WebUI,請使用http://host.docker.internal:10000/v1) - API Key:
none(留空即可)
💡 保存後,Open WebUI 將開始使用您的本地 Llama.cpp 伺服器作為後端!
小提示:通過聊天介面嘗試模型
連接後,從 Open WebUI 聊天菜單中選擇模型並開始互動!
您已準備就緒!
配置完成後,Open WebUI 讓您可以輕鬆:
- 管理並切換由 Llama.cpp 提供服務的本地模型
- 使用無需密鑰的 OpenAI 兼容 API
- 在您的機器上嘗試使用像 DeepSeek-R1 這樣的大型模型!
🚀 祝您玩得愉快並成功構建!