🦙Commencer avec Llama.cpp
Vue d'ensemble
Open WebUI rend simple et flexible la connexion et la gestion d'un serveur local Llama.cpp pour exécuter des modèles de langage efficaces et quantifiés. Que vous ayez compilé Llama.cpp vous-même ou que vous utilisiez des binaires précompilés, ce guide vous expliquera comment :
- Configurer votre serveur Llama.cpp
- Charger des modèles volumineux localement
- Intégrer avec Open WebUI pour une interface fluide
Commençons !
Étape 1 : Installer Llama.cpp
Pour exécuter des modèles avec Llama.cpp, vous devez d'abord installer localement le serveur Llama.cpp.
Vous pouvez soit :
- 📦 Télécharger des binaires précompilés
- 🛠️ Ou le compiler à partir du code source en suivant les instructions officielles de compilation
Après l'installation, assurez-vous que llama-server est disponible dans le chemin système local ou notez son emplacement.
Étape 2 : Télécharger un modèle pris en charge
Vous pouvez charger et exécuter divers modèles LLM quantifiés au format GGUF avec Llama.cpp. Un exemple impressionnant est le modèle DeepSeek-R1 1,58 bits optimisé par UnslothAI. Pour télécharger cette version :
- Rendez-vous sur le dépôt DeepSeek-R1 d'Unsloth sur Hugging Face
- Téléchargez la version quantifiée 1,58 bits – environ 131GB.
Sinon, utilisez Python pour télécharger de manière programmée :
# pip install huggingface_hub hf_transfer
from huggingface_hub import snapshot_download
snapshot_download(
repo_id = "unsloth/DeepSeek-R1-GGUF",
local_dir = "DeepSeek-R1-GGUF",
allow_patterns = ["*UD-IQ1_S*"], # Télécharger uniquement la variante 1,58 bits
)
Cela téléchargera les fichiers du modèle dans un répertoire comme :
DeepSeek-R1-GGUF/
└── DeepSeek-R1-UD-IQ1_S/
├── DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf
├── DeepSeek-R1-UD-IQ1_S-00002-of-00003.gguf
└── DeepSeek-R1-UD-IQ1_S-00003-of-00003.gguf
📍 Notez le chemin complet vers le premier fichier GGUF — vous en aurez besoin à l'étape 3.
Étape 3 : Servir le modèle avec Llama.cpp
Démarrez le serveur de modèle à l'aide du binaire llama-server. Naviguez vers votre dossier llama.cpp (par exemple, build/bin) et exécutez :
./llama-server \
--model /chemin/complet/vers/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
--port 10000 \
--ctx-size 1024 \
--n-gpu-layers 40
🛠️ Ajustez les paramètres pour convenir à votre machine :
- --model : Chemin vers votre fichier modèle .gguf
- --port : 10000 (ou choisissez un autre port ouvert)
- --ctx-size : Longueur de contexte de token (peut augmenter si la RAM le permet)
- --n-gpu-layers : Couches transférées au GPU pour des performances plus rapides
Une fois le serveur lancé, il exposera une API locale compatible OpenAI sur :
http://127.0.0.1:10000
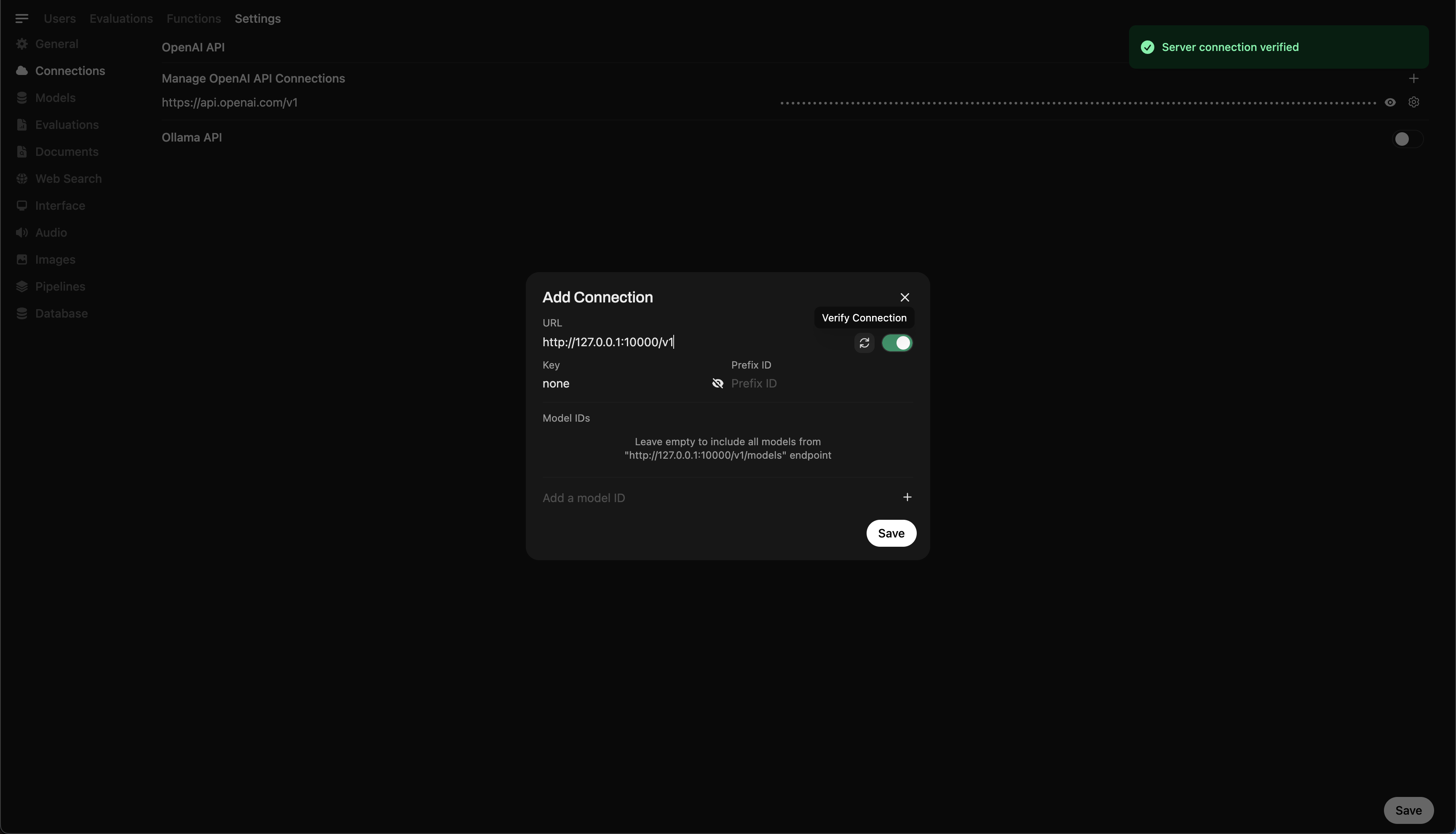
Étape 4 : Connecter Llama.cpp à Open WebUI
Pour contrôler et interroger votre modèle en cours d'exécution localement à partir d'Open WebUI :
- Ouvrez Open WebUI dans votre navigateur
- Accédez à ⚙️ Paramètres Admin → Connexions → Connexions OpenAI
- Cliquez sur ➕ Ajouter une connexion et entrez :
- URL :
http://127.0.0.1:10000/v1
(Ou utilisezhttp://host.docker.internal:10000/v1si vous exécutez WebUI dans Docker) - Clé API :
none(laissez vide)
💡 Une fois enregistré, Open WebUI commencera à utiliser votre serveur local Llama.cpp comme backend !
Astuce rapide : Essayez le modèle via l'interface de chat
Une fois connecté, sélectionnez le modèle dans le menu de chat Open WebUI et commencez à interagir !
Vous êtes prêt !
Une fois configuré, Open WebUI permet de :
- Gérer et basculer entre les modèles locaux servis par Llama.cpp
- Utiliser l'API compatible OpenAI sans clé nécessaire
- Expérimenter des modèles massifs comme DeepSeek-R1 — directement depuis votre machine !
🚀 Amusez-vous à expérimenter et à créer !