🌐 Einstieg mit OpenAI-kompatiblen Servern
Überblick
Open WebUI ist nicht nur für OpenAI/Ollama/Llama.cpp gedacht – Sie können jeden Server nutzen, der die OpenAI-kompatible API implementiert, sei es lokal oder remote. Dies ist ideal, wenn Sie verschiedene Sprachmodelle ausführen möchten oder bereits ein bevorzugtes Backend oder Ökosystem haben. Dieser Leitfaden zeigt Ihnen:
- Wie Sie einen OpenAI-kompatiblen Server einrichten (mit einigen beliebten Optionen)
- Wie Sie ihn mit Open WebUI verbinden
- Wie Sie direkt loschatten können
Schritt 1: Wählen Sie einen OpenAI-kompatiblen Server
Es gibt viele Server und Tools, die eine OpenAI-kompatible API bereitstellen. Hier sind einige der beliebtesten:
- Llama.cpp: Extrem effizient, läuft auf CPU und GPU
- Ollama: Super benutzerfreundlich und plattformübergreifend
- LM Studio: Funktionsreiche Desktop-App für Windows/Mac/Linux
- Lemonade (ONNX TurnkeyML): Schnelles ONNX-basiertes Backend mit NPU/iGPU-Beschleunigung
Wählen Sie, was zu Ihrem Workflow passt!
🍋 Erste Schritte mit Lemonade (ONNX TurnkeyML)
Lemonade ist ein Plug-and-Play-Server auf ONNX-Basis, der mit OpenAI kompatibel ist. So können Sie ihn auf Windows ausprobieren:
-
Führen Sie
Lemonade_Server_Installer.exeaus -
Installieren Sie Lemonade und laden Sie ein Modell mit dem Installer herunter
-
Sobald der Server läuft, lautet Ihr API-Endpunkt:
http://localhost:8000/api/v0
Details finden Sie in deren Dokumentation.
Schritt 2: Verbinden Sie Ihren Server mit Open WebUI
-
Öffnen Sie Open WebUI in Ihrem Browser.
-
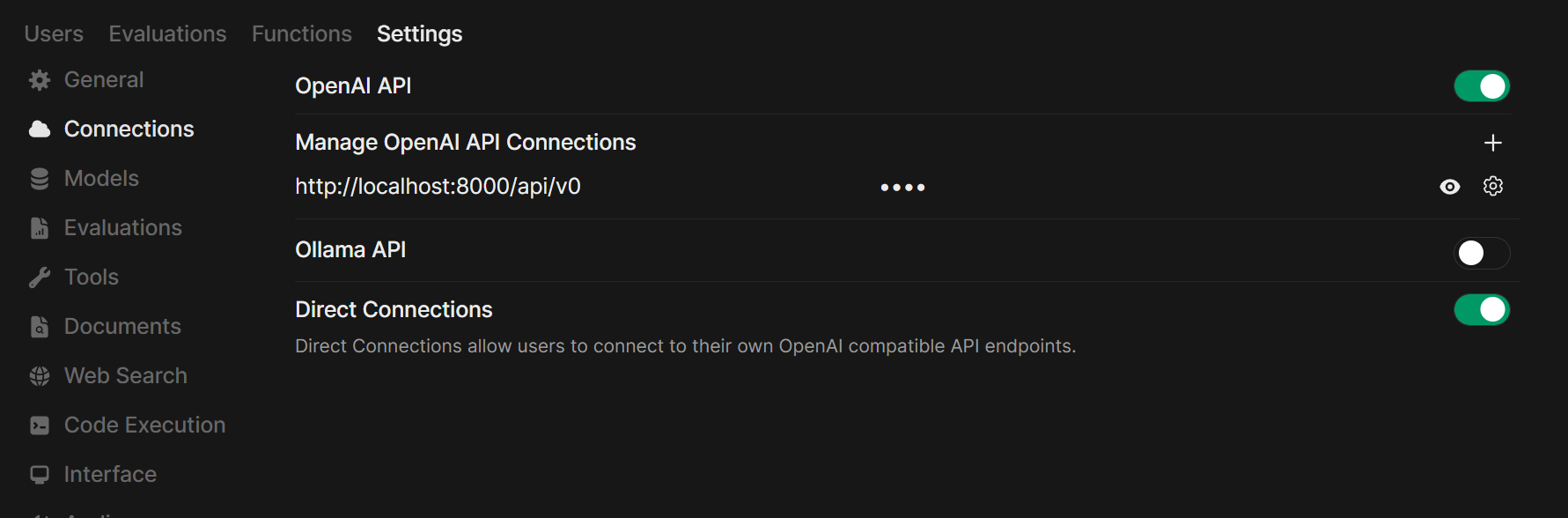
Gehen Sie zu ⚙️ Admin-Einstellungen → Verbindungen → OpenAI-Verbindungen.
-
Klicken Sie auf ➕ Verbindung hinzufügen.
- URL: Verwenden Sie den API-Endpunkt Ihres Servers (zum Beispiel
http://localhost:11434/v1für Ollama oder die Adresse Ihres eigenen Llama.cpp-Servers). - API-Schlüssel: Leer lassen, es sei denn, es wird benötigt.
- URL: Verwenden Sie den API-Endpunkt Ihres Servers (zum Beispiel
-
Klicken Sie auf Speichern.
Tipp: Wenn Sie Open WebUI in Docker ausführen und Ihr Modellserver auf Ihrem Host-Rechner läuft, verwenden Sie http://host.docker.internal:<Ihr-Port>/v1.
Für Lemonade: Verwenden Sie beim Hinzufügen von Lemonade http://localhost:8000/api/v0 als URL.
Schritt 3: Loschatten!
Wählen Sie das Modell Ihres verbundenen Servers im Chat-Menü und legen Sie los!
Das war's! Egal, ob Sie Llama.cpp, Ollama, LM Studio oder Lemonade wählen, Sie können problemlos mit mehreren Modellservern experimentieren und diese verwalten – alles in Open WebUI.
🚀 Viel Spaß beim Aufbau Ihres perfekten lokalen KI-Setups!