📝 評估
為什麼需要評估模型?
來認識一下 Alex,一位在中型公司工作的機器學習工程師。Alex 知道市面上有很多 AI 模型——GPTs、LLaMA,還有其他許多模型——但哪個模型最適合當前的工作呢?這些模型在紙面上看起來都很厲害,但 Alex 不能僅僅依賴公開排行榜。這些模型根據上下文表現有所不同,還有一些模型可能已經在評估數據集上進行過訓練(小心!)。此外,這些模型生成的文字有時候感覺...不太對味。
這時 Open WebUI 派上用場。它為 Alex 和他的團隊提供了一個簡便的方法,用於根據實際需求來評估模型。不需要複雜的計算,也不需要繁重的工作。只需在與模型交互時給出讚或踩的評價即可。
TL;DR (簡而言之)
- 為什麼評估很重要:模型太多了,但不是所有都適合你的特定需求。公開排行榜並不總是可靠的。
- 如何解決:Open WebUI 提供內置評估系統。使用讚或踩來評價模型的回應。
- 幕後發生什麼:評分會調整你的個性化排行榜,同時受評價聊天的快照將用於未來模型的微調!
- 評估模式:
- 競技場模式:隨機選擇模型供你比較。
- 普通互動:像平常聊天一樣,然後評價回應。
為什麼公開評估不夠呢?
- 公開排行榜並沒有針對 你的 特定使用場景。
- 有些模型在評估數據集上進行過訓練,導致結果的公平性受到影響。
- 某些模型可能整體表現很好,但其溝通方式或回應的“風格”並不符合你所需的氛圍。
解決方案:使用 Open WebUI 進行個性化評估
Open WebUI 擁有內置的評估功能,讓你和你的團隊可以在與模型互動的過程中,發現最適合你需求的模型。
它怎麼運作?很簡單!
- 在聊天過程中,如果你喜歡某個回應,就給讚;如果不喜歡,就給踩。如果消息有 兄弟消息(如重新生成的回應或模型對比中的另一回應),你的評分會加入到你的 個性化排行榜 中。
- 排行榜 可在管理區域輕鬆訪問,幫助你跟蹤哪些模型表現最佳。
一項酷功能?每當你評分某個回應,系統會捕捉該聊天的 快照,未來可用於改進模型甚至驅動模型訓練。(請注意,此功能仍在開發中!)
評估 AI 模型的兩種方式
Open WebUI 提供了兩種簡便方法來評估 AI 模型。
1. 競技場模式
競技場模式 從可用模型池中隨機選擇模型,確保評估是公平且不偏頗的。這有助於消除手動比較中的潛在缺陷:生態效度——確保你不會有意或無意地偏向某個模型。
使用方法:
- 從競技場模型選擇器中選擇一個模型。
- 像平常使用模型一樣,但現在你處於“競技場模式”。
你的反饋需要 兄弟消息 才能影響排行榜。什麼是兄弟消息?兄弟消息是指通過相同查詢生成的任何替代回應(比如消息再生,或多個模型生成的並列回應)。這樣,你就是在 正面比較 回應了。
- 評分提示:當你給某個回應讚時,另一個回應會自動獲得踩。所以要慎重,只給真正認為是最佳的消息讚!
- 一旦你評分了回應,就可以查看排行榜以了解模型的表現如何。
以下是競技場模式界面的示例:
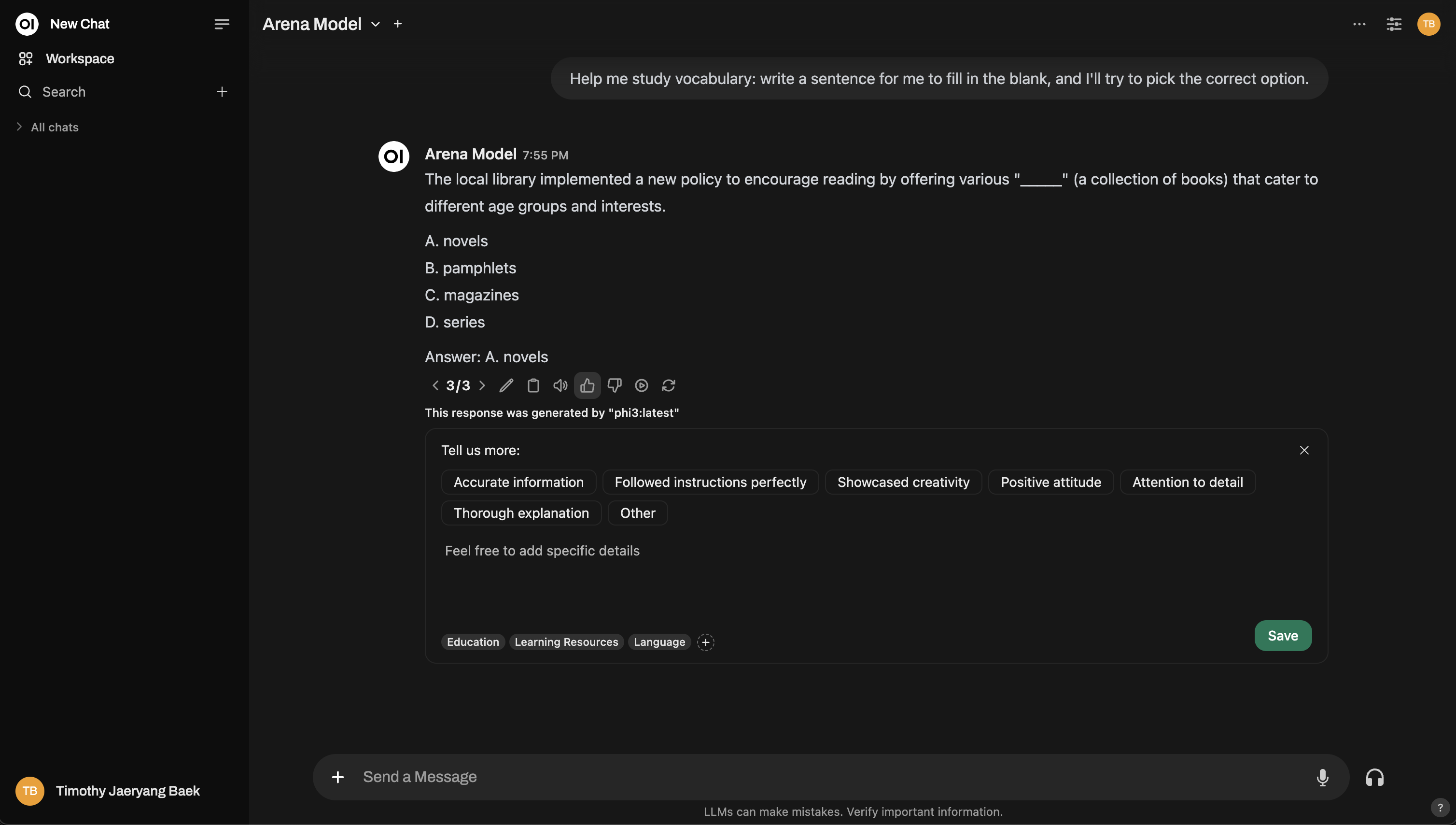
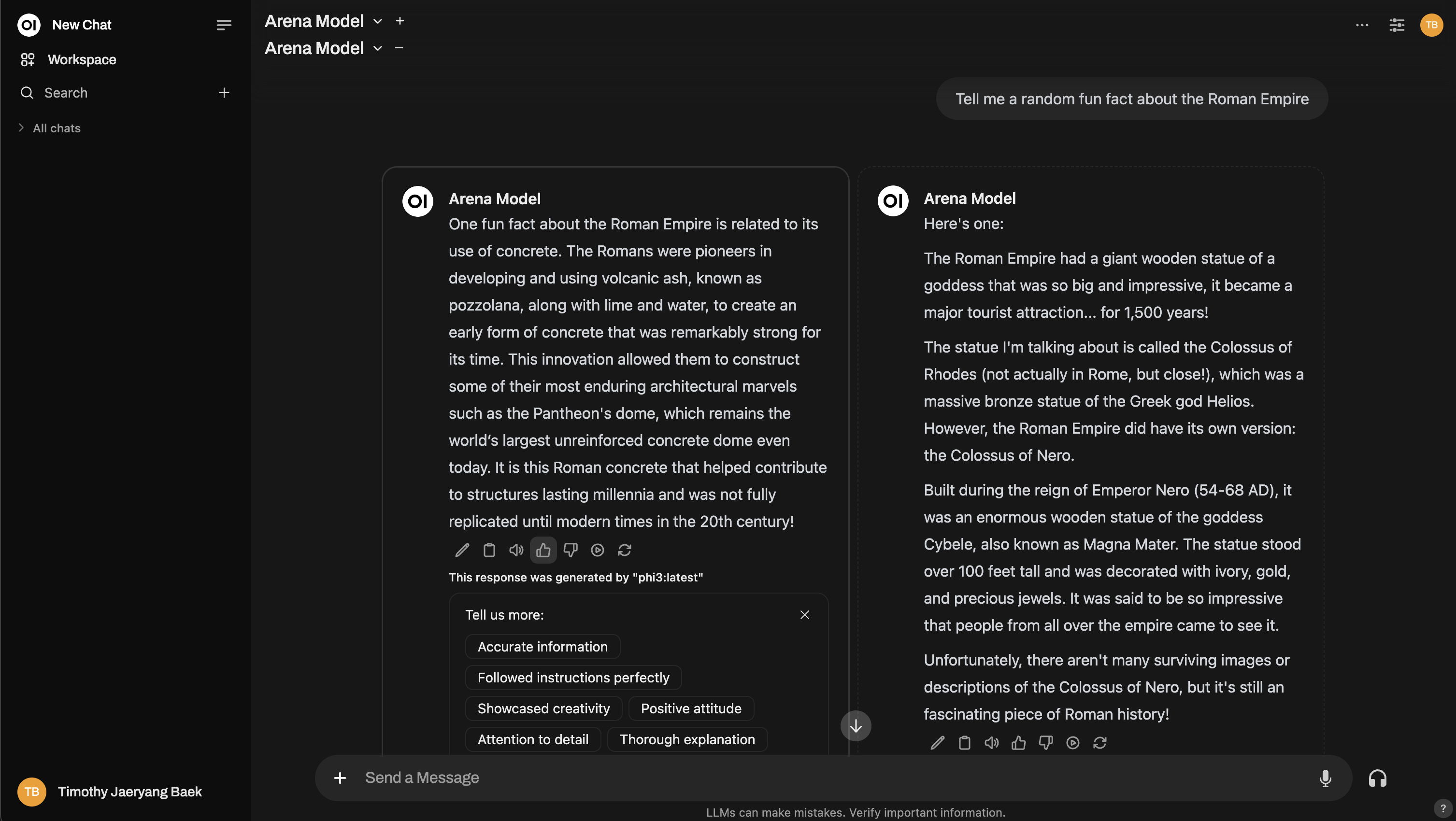
需要更深入的功能?你甚至可以模仿 聊天機器人競技場的設定!
2. 普通互動
如果你不想切換到“競技場模式”,你可以正常使用 Open WebUI,並根據日常操作來評價 AI 模型回應。只需在模型回應上點讚或踩,隨時隨地都可以。然而,如果你希望你的反饋用於排行榜的排名,你需要 更換模型並與不同的模型互動。這能確保有 兄弟回應 作為比較——只有兩個不同模型之間的比較才會影響排名。
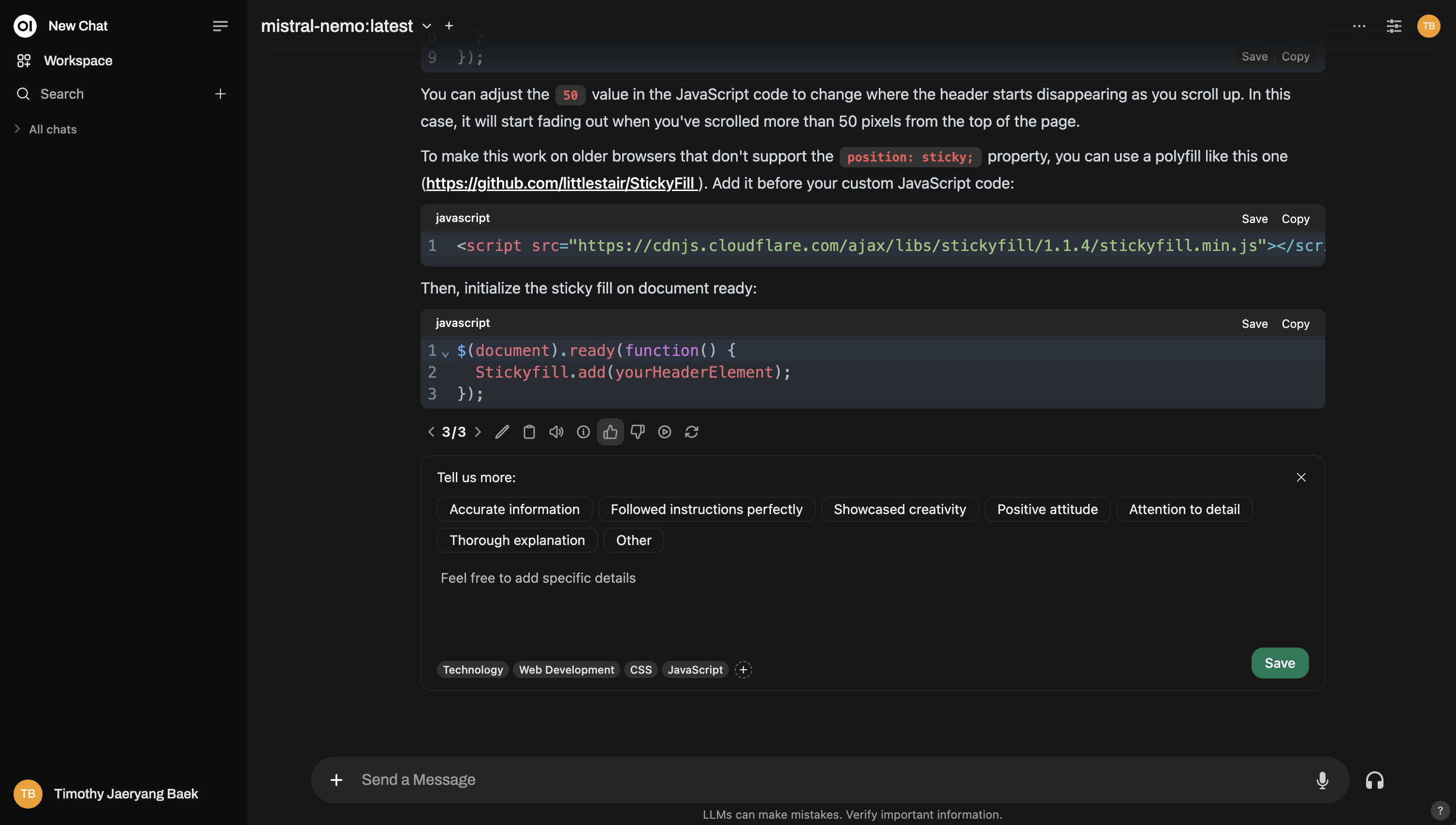
以下是普通互動中的評分示例:
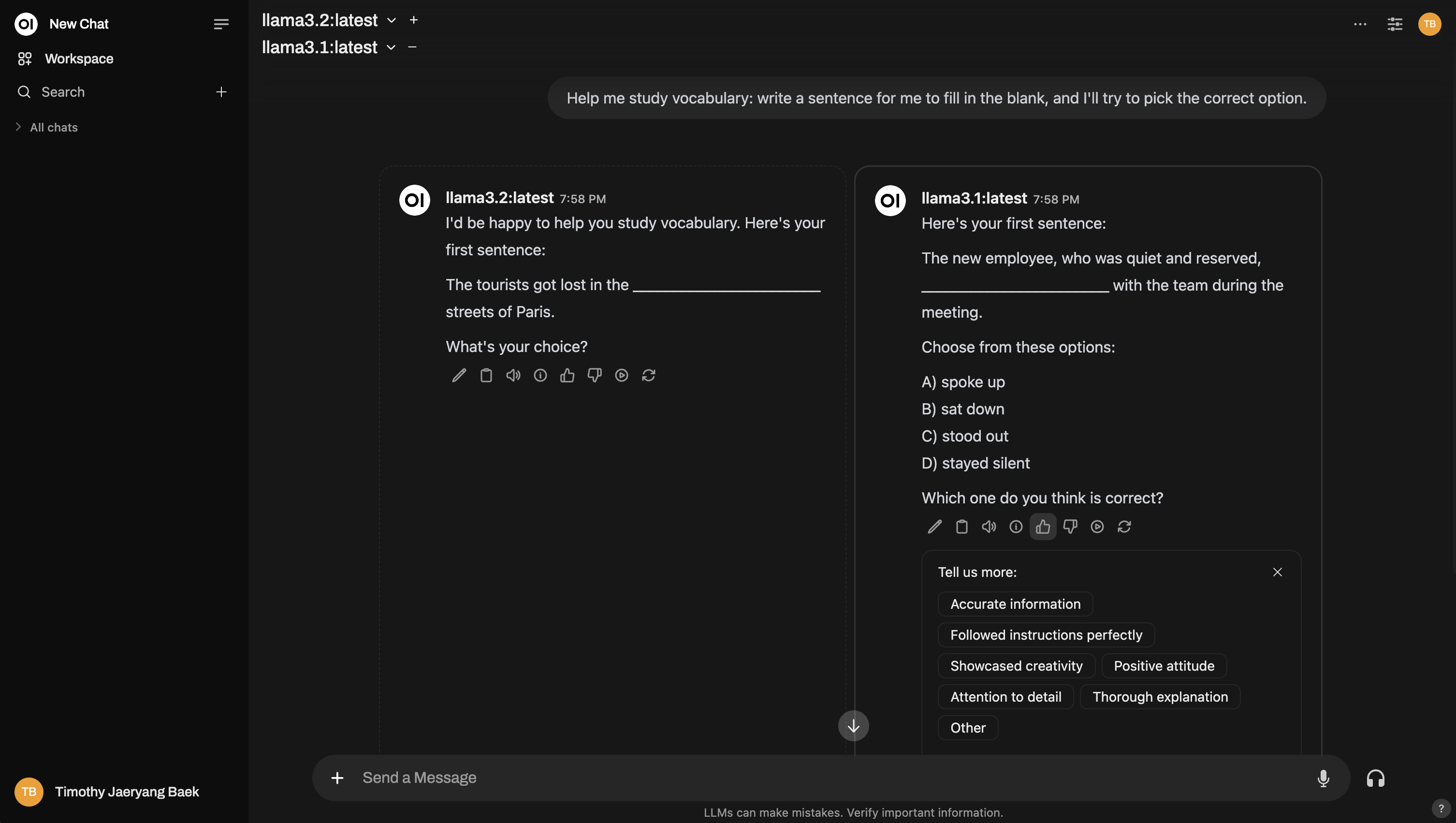
以下是設置多模型比較類似競技場的示例:
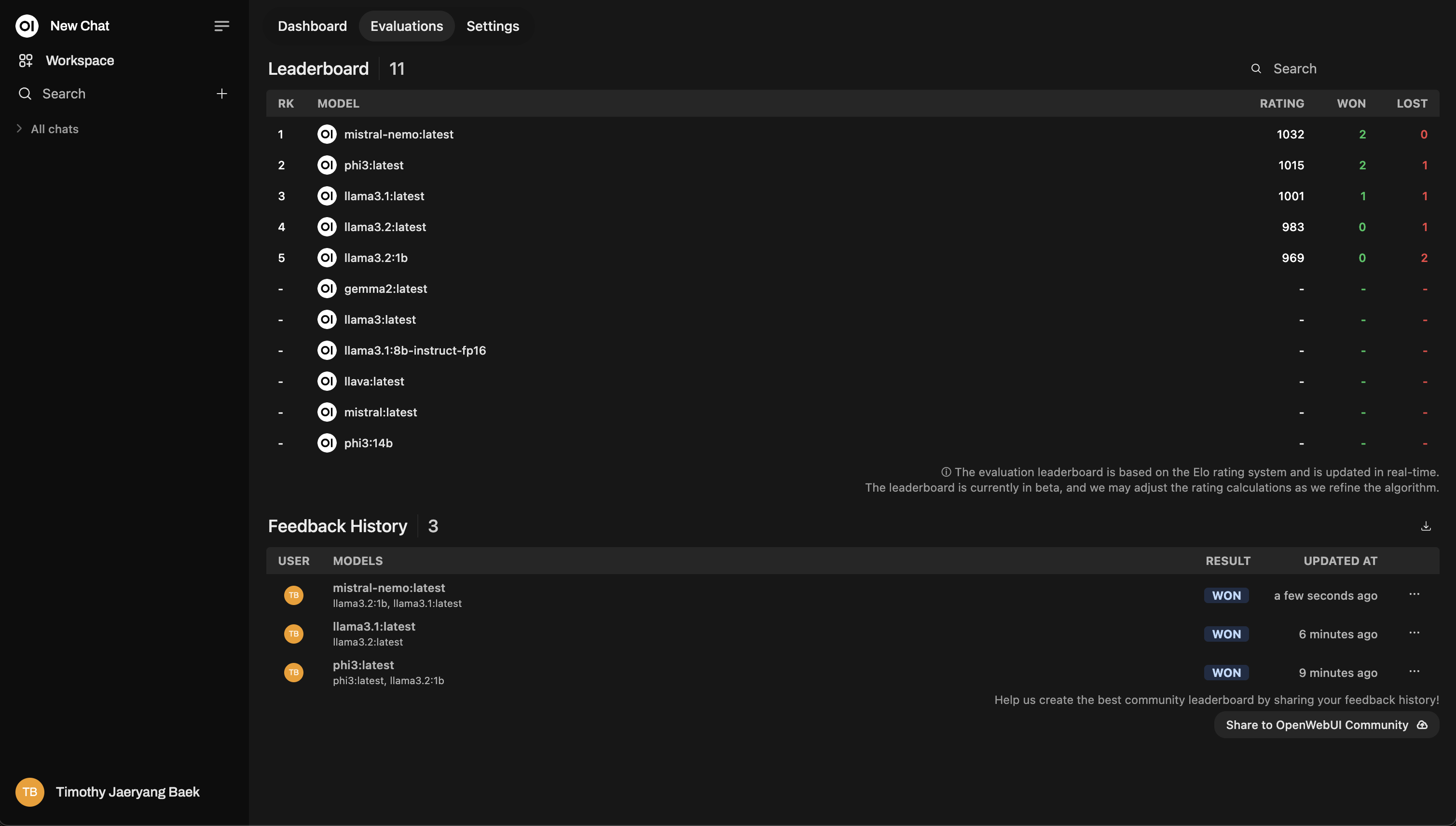
排行榜
評分後,到管理面板下的排行榜查看結果。在這裡,您將以視覺化的方式看到模型的執行情況,排名基於Elo 評分系統(類似國際象棋排名!)。您將能真實了解哪個模型在評估中表現最為突出。
這是一個排行榜範例布局:
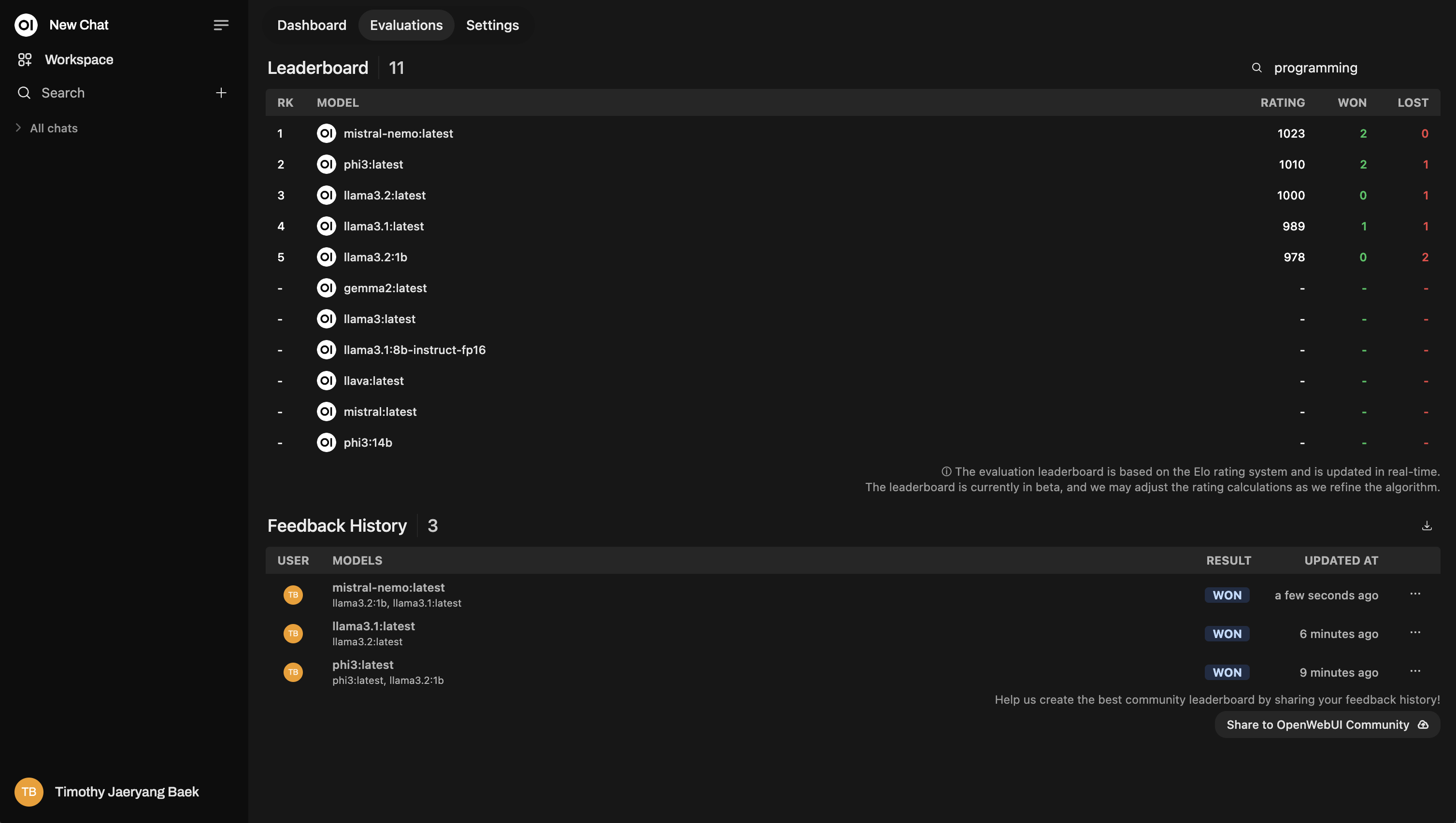
基於主題的重排名
當您對聊天進行評分時,您可以按主題標記它們以獲得更細緻的洞察。這在處理不同領域(如客戶服務、創意寫作、技術支持等)時特別有用。
自動標記
Open WebUI 嘗試根據對話主題自動標記聊天。但是,根據您使用的模型,自動標記功能可能會有時失敗或誤解對話。在這種情況下,最好手動標記聊天以確保反饋準確。
- 如何手動標記:當您評分回應時,您可以根據對話的上下文添加自己的標記。
不要跳過這一步!標記非常強大,因為它允許您基於特定主題重排名模型。例如,您可能想看看哪個模型在回答技術支持問題方面表現最佳,而另一個模型在回答一般客戶諮詢時表現更好。
這是重排名結果的範例:
附註:用於模型微調的聊天快照
每當您評分模型的回應時,Open WebUI 會捕捉該聊天的快照。這些快照最終可用於微調您自己的模型��——您的評估結果可以促進 AI 的持續改進。
(敬請期待此功能的更多更新,目前正在積極開發中!)
摘要
簡而言之,Open WebUI 的評估系統有兩個明確的目標:
- 幫助您輕鬆比較模型。
- 最終找到最符合您個人需求的模型。
該系統的核心宗旨是讓 AI 模型的評估變得簡單、透明且可定制,適合每位用戶的需求。無論是透過競技場模式還是普通聊天互動,您完全掌控決定哪個 AI 模型最適合您的具體場景!
一如既往,您的所有數據都安全地保存在您的實例中,除非您特別選擇加入社區共享,否則不會分享任何數據。您的隱私和數據自主權始終被優先考慮。