📝 評価
なぜモデルを評価する必要があるのか?
中規模企業の機械学習エンジニアであるAlexをご紹介します。Alexは世の中に多数のAIモデル—GPTs、LLaMAなど—が存在することを知っていますが、どれが現在のタスクに最適なのかを判断する必要があります。これらのモデルは紙の上では素晴らしいように聞こえますが、Alexは公共のリーダーボードだけを頼りにすることはできません。それらのモデルは文脈や条件によって異なる性能を発揮し、評価データセットでトレーニングされているモデルもあるかもしれません(注意が必要です!)。さらに、これらのモデルが生成する文章が時々…違和感を覚えることもあります。
そこでOpen WebUIが登場します。これにより、Alexとそのチームは自分たちの実際のニーズに基づいてモデルを簡単に評価する方法を提供します。複雑な数式なし。面倒な操作もなし。ただ単にモデルと対話しながら親指で評価するだけ。
TL;DR
- 評価の重要性: モデルが多すぎて、すべてが特定のニーズを満たすわけではありません。一般的な公共リー�ダーボードは常に信頼できるわけではありません。
- 問題解決方法: Open WebUIは内蔵された評価システムを提供します。サムズアップ/サムズダウンでモデルの応答を評価できます。
- 舞台裏で何が起こるのか: 評価に応じてパーソナライズされたリーダーボードが調整され、評価されたチャットのスナップショットが将来のモデル微調整に使用されます!
- 評価オプション:
- Arena Model: モデルをランダムに選択して比較。
- 通常の対話: 通常のチャットを行い、応答を評価。
なぜ公共評価では十分ではないのか?
- 公共リーダーボードはあなたの特定のユースケースに合わせたものではありません。
- 一部のモデルは評価データセットでトレーニングされており、結果の公平性に影響を与える可能性があります。
- モデルは全体的には良好に動作するかもしれませんが、そのコミュニケーションスタイルや応答が求める「雰囲気」に合わないことがあります。
解決策: Open WebUIによるパーソナライズされた評価
Open WebUIには、モデルと対話しながら特定のニーズに最も適したモデルを見つけることができる内蔵の評価機能があります。
仕組みは簡単です!
- チャット中に、応答が気に入ったらサムズアップ、そうでなければサムズダウンを付けます。メッセージに兄弟メッセージ(例: 再生成された応答や並行比較の一部)が含まれる場合、これはあなたの個人リーダーボードに貢献しています。
- リーダーボードは管理セクションで簡単にアクセス可能で、あなたのチームにとって最も良い結果を出すモデルを追跡できます。
便利な機能? 応答を評価するとき、システムはその会話のスナップショットをキャプチャします。これが後にモデルの改善や将来のモデルトレーニングに使用されます。(注: 現在開発途中です!)
AIモデルを評価する2つの方法
Open WebUIはAIモデルを評価するための2つの簡単なアプローチを提供します。
1. Arena Model
Arena Modelは利用可能なモデルのプールからランダムにモデルを選択し、公平かつ偏らない評価を確保します。これにより、手動比較の潜在的な欠陥—生態学的妥当性(無意識、または意識的に特定のモデルを優先することを回避)—を排除するのに役立ちます。
使用方法:
- Arena Modelのセレクターからモデルを選択します。
- 通常通りモデルを使用しますが、これで「アリーナモード」に入りました。
リーダーボードにフィードバックを反映させるには、兄弟メッセージが必要です。兄弟メッセージとは何でしょうか?兄弟メッセージとは、同じクエリによって生成された代替応答(メッセージ再生成や複数モデルによる並行応答)を指します。この方法で、応答を直接比較できます。
- 採点のヒント: 1つの応答にサムズアップすると、もう1つは自動的にサムズダウンされます。ですので、慎重に判断し、真に優れていると思うメッセージのみをアップしてください!
- 応答を評価したら、モデルがどのように順位付けされているかをリーダーボードで確認できます。
これがArena Modelインターフェースの例です:
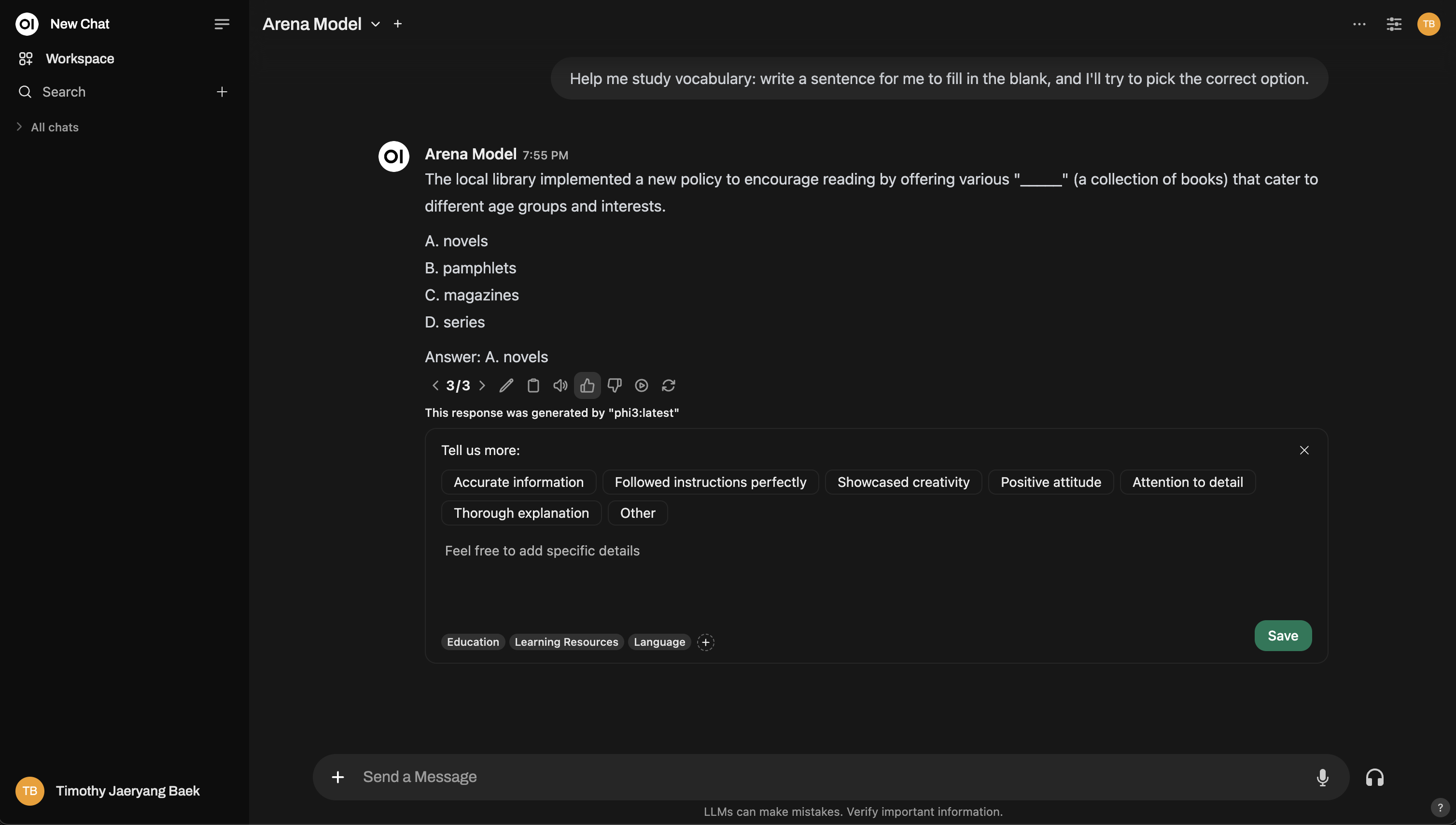
さらに深く知りたい?Chatbot Arenaのようなセットアップを再現することもできます!
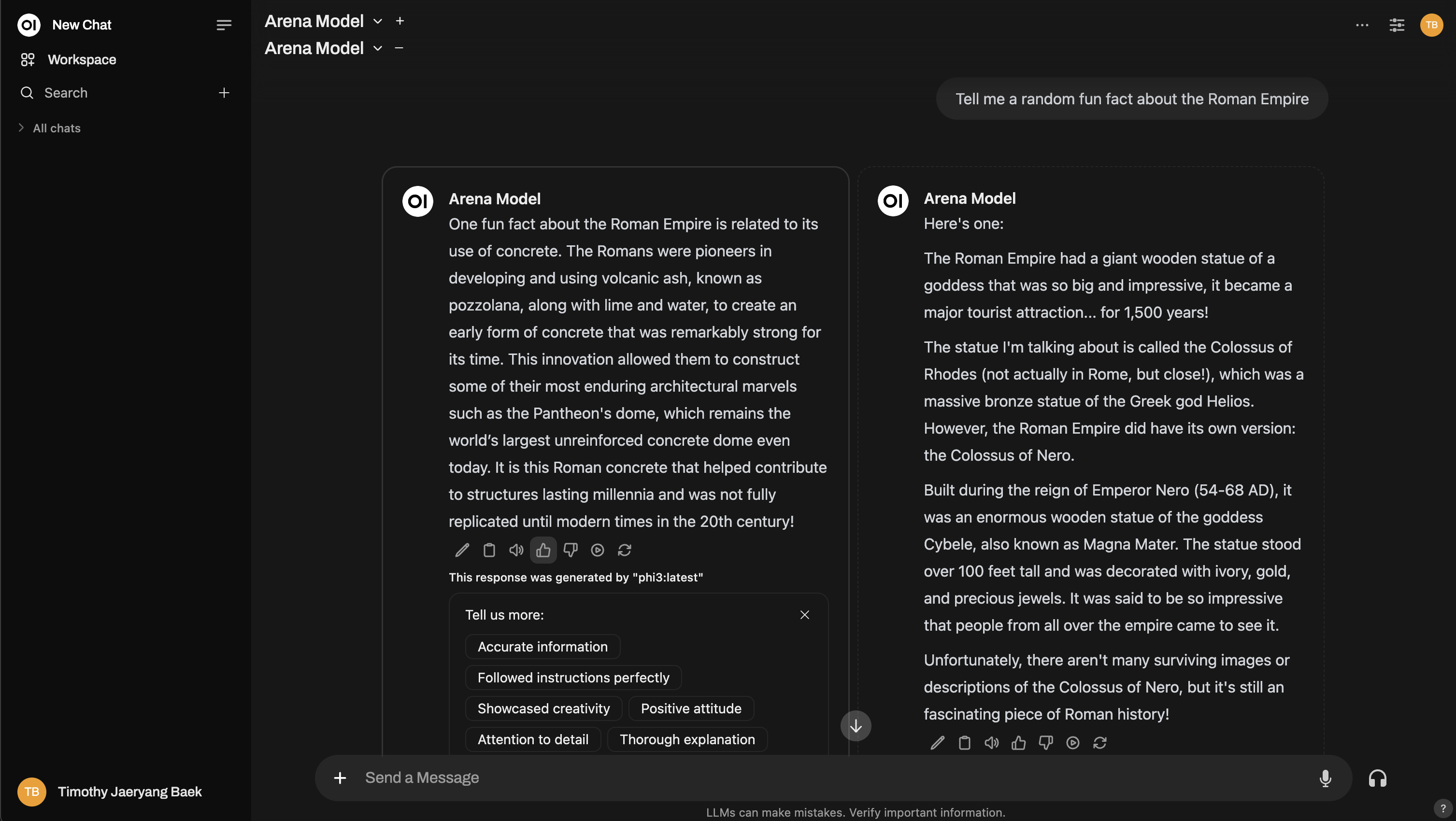
2. 通常の対話
「アリーナモード」に切り替えずとも、Open WebUIを通常通り利用し、日常的な操作中にAIモデルの応答を評価することが可能です。モデル応答に対してサムズアップ/サムズダウンをいつでも気軽に行うことができます。ただし、リーダーボード評価にフィードバックを利用したい場合は、モデルを切り替え、別のモデルと対話する必要があります。これにより、兄弟応答が生じ、2つの異なるモデル間の比較のみがランキングに影響を与えるようにします。
例えば、通常の対話中の評価方法は以下の通りです:
そして、アリーナに似たマルチモデル比較の設定例はこちらです:
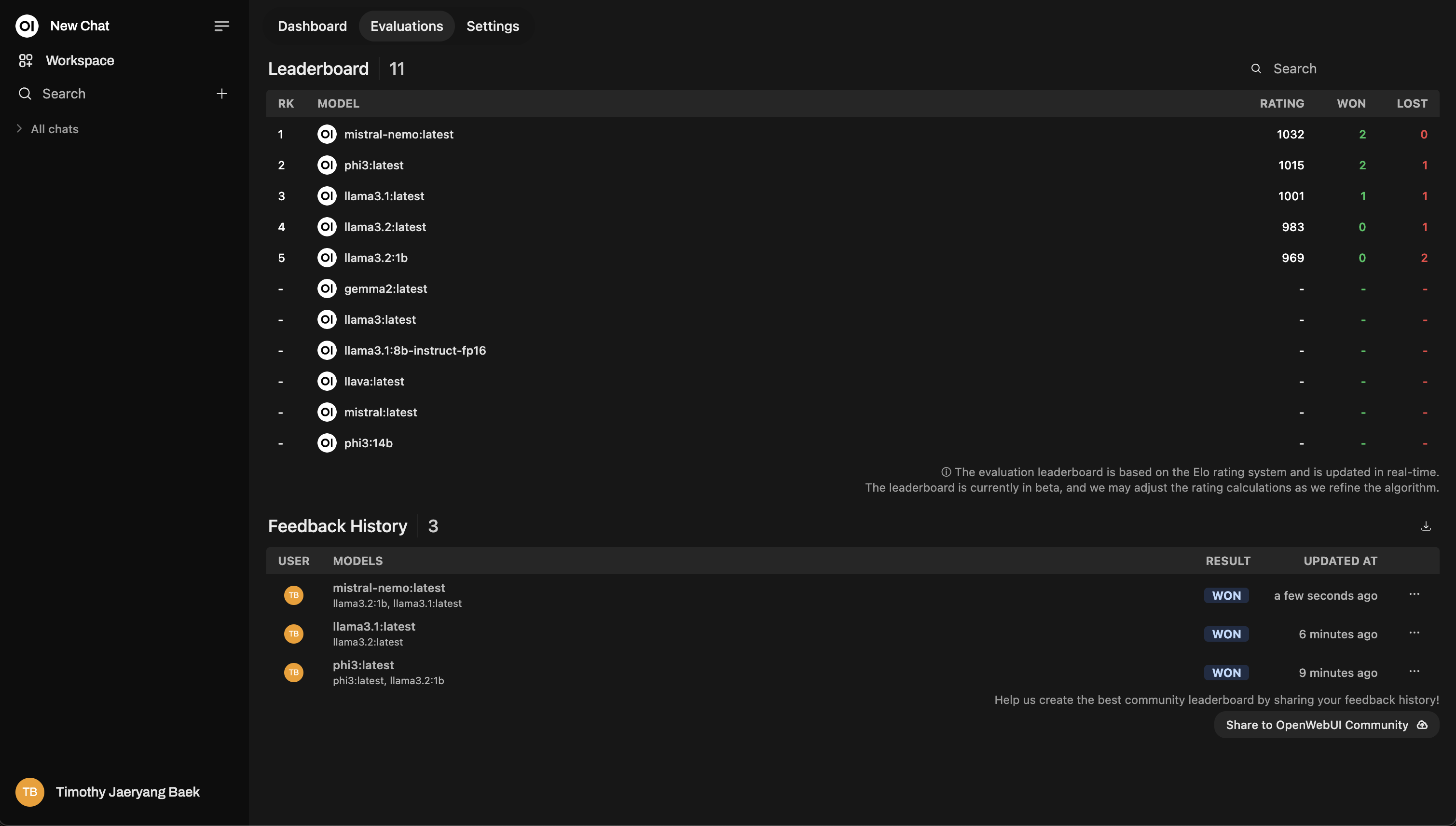
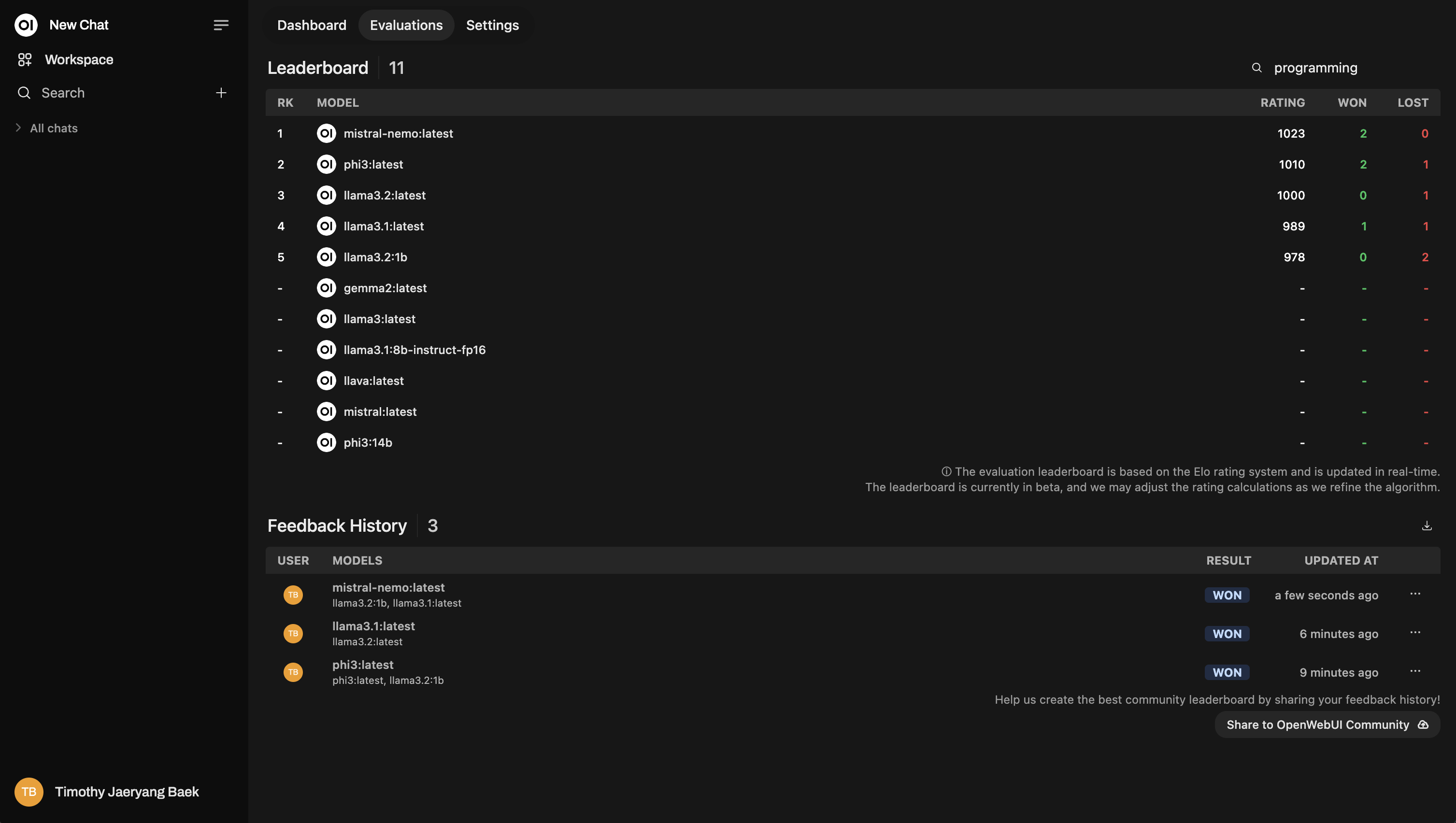
リーダーボード
評価した後、管理パネルのランキングボードをチェックしてみてください。ここで、モデルがどのようにパフォーマンスを発揮しているかを視覚的に確認できます。イロレーティングシ�ステム(チェスのランキングのようなもの)を使って順位付けされています。評価中にどのモデルが本当に際立っているのかをリアルに見ることができます。
これはランキングボードのサンプルレイアウトです:
トピックベースのリランキング
チャットを評価する際に、トピックごとにタグ付けすることで、より詳細な洞察を得ることができます。これは、顧客サービス、クリエイティブライティング、技術サポートなど、異なる分野で作業している場合に特に便利です。
自動タグ付け
Open WebUIは、会話のトピックに基づいて自動的にチャットをタグ付けしようとします。ただし、使用しているモデルによっては、自動タグ付け機能が失敗したり会話を誤解することがあります。その場合は、フィードバックを正確にするために手動でチャットにタグ付けをするのが最善です。
- 手動でタグ付けする方法:レスポンスを評価するとき、会話のコン�テキストに基づいて独自のタグを追加するオプションがあります。
これを省略しないでください!タグ付けは非常に強力で、特定のトピックに基づいてモデルを再ランク付けすることができます。たとえば、技術サポートの質問に答えるうえでどのモデルが最適か、または一般的な顧客問い合わせでどのモデルが優れているかを確認したい場合に役立ちます。
リランキングの例は次のようになります:
サイドノート: モデルのファインチューニング用のチャットスナップショット
モデルのレスポンスを評価するたびに、Open WebUIはそのチャットのスナップショットをキャプチャします。これらのスナップショットは、最終的に独自のモデルをファインチューニングするために使用できます——つまり、評価がAIの継続的な改善に貢献するのです。
(この機能は現在積極的に開発されていますので、続報をお楽しみに!)
まとめ
要約すると、Open WebUIの評価システムには2つの明確な目標があります:
- モデルを簡単に比較する手助けをすること。
- 最終的には、あなたの個別のニーズに最も適したモデルを見つけること。
このシステムの核心には、AIモデルの評価をシンプル、透明、カスタマイズ可能にするということがあります。アリーナモデルまたは通常のチャットインタラクションのいずれを使用しても、特定のユースケースに最適なAIモデルを決定するためのコントロールを完全に握っています!
いつでも、すべてのデータはあなたのインスタンスに安全に保存され、あなたが特にコミュニティ共有を選択しない限り共有されることはありません。あなたのプライバシーとデータの自主性が常に優先されます。