📝 Évaluation
Pourquoi devrais-je évaluer des modèles ?
Voici Alex, un ingénieur en apprentissage automatique dans une entreprise de taille moyenne. Alex sait qu'il existe de nombreux modèles d'IA – GPTs, LLaMA, et bien d'autres – mais lequel fonctionne le mieux pour la tâche à accomplir ? Ils semblent tous impressionnants sur le papier, mais Alex ne peut pas se fier uniquement aux tableaux de classement publics. Ces modèles se comportent différemment en fonction du contexte, et certains modèles peuvent avoir été formés sur le jeu de données d'évaluation (malin !). De plus, la manière dont ces modèles écrivent peut parfois sembler... étrange.
C'est là qu'Open WebUI entre en jeu. Il offre à Alex et à son équipe un moyen simple d'évaluer les modèles en fonction de leurs besoins réels. Pas de mathématiques complexes. Pas de travail laborieux. Juste un pouce vers le haut ou vers le bas en interagissant avec les modèles.
TL;DR
- Pourquoi les évaluations sont importantes : Trop de modèles, mais tous ne répondent pas à vos besoins spécifiques. Les tableaux de classement publics ne sont pas toujours fiables.
- Comment résoudre cela : Open WebUI offre un système d'évaluation intégré. Utilisez un pouce vers le haut/bas pour noter les réponses des modèles.
- Ce qui se passe en coulisses : Les notes ajustent votre tableau de classement personnalisé, et les instantanés des discussions notées seront utilisés pour affiner les modèles à l'avenir !
- Options d'évaluation :
- Mode Arène : Sélectionne des modèles au hasard pour que vous les compariez.
- Interaction normale : Discutez normalement et notez les réponses.
Pourquoi l'évaluation publique ne suffit-elle pas ?
- Les tableaux de classement publics ne sont pas adaptés à votre cas d'utilisation spécifique.
- Certains modèles sont entraînés sur des ensembles de données d'évaluation, ce qui affecte l'équité des résultats.
- Un modèle peut bien performer globalement, mais son style de communication ou ses réponses peuvent ne pas correspondre à l'ambiance que vous souhaitez.
La solution : l'évaluation personnalisée avec Open WebUI
Open WebUI dispose d'une fonction d'évaluation intégrée qui permet à vous et votre équipe de découvrir le modèle le plus adapté à vos besoins particuliers, tout en interagissant avec les modèles.
Comment ça marche ? Simple !
- Pendant les discussions, laissez un pouce vers le haut si vous aimez une réponse, ou un pouce vers le bas si vous ne l'aimez pas. Si le message a un message sibling (comme une réponse régénérée ou une partie d'une comparaison côte à côte de modèles), vous contribuez à votre tableau de classement personnel.
- Les tableaux de classement sont facilement accessibles dans la section Admin, vous permettant de suivre quels modèles performent le mieux selon votre équipe.
Une fonctionnalité intéressante ? Chaque fois que vous notez une réponse, le système capture un instantané de cette conversation, qui sera ensuite utilisé pour affiner les modèles ou même pour former des modèles futurs. (Notez que cela est encore en cours de développement !)
Deux manières d'évaluer un modèle d'IA
Open WebUI propose deux approches simples pour évaluer les modèles d'IA.
1. Mode Arène
Le Mode Arène sélectionne aléatoirement parmi une liste de modèles disponibles, garantissant que l'évaluation est équitable et impartiale. Cela aide à éliminer un défaut potentiel de la comparaison manuelle : validité écologique – s'assurer que vous ne favorisez pas consciemment ou inconsciemment un modèle.
Comment l'utiliser :
- Sélectionnez un modèle dans le sélecteur Mode Arène.
- Utilisez-le comme vous le feriez normalement, mais maintenant vous êtes en “mode arène”.
Pour que votre retour affecte le tableau de classement, vous avez besoin de ce qu'on appelle un message sibling. Qu'est-ce qu'un message sibling ? C'est simplement une réponse alternative générée par la même requête (pensez à des régénérations de message ou à plusieurs modèles générant des réponses côte à côte). De cette façon, vous comparez les réponses directement.
- Conseil pour noter : Lorsque vous donnez un pouce vers le haut à une réponse, l'autre reçoit automatiquement un pouce vers le bas. Soyez donc attentif et n'approuvez que le message que vous jugez véritablement le meilleur !
- Une fois que vous avez noté les réponses, vous pouvez consulter le tableau de classement pour voir comment les modèles se classent.
Voici un aperçu de l'interface du Mode Arène :
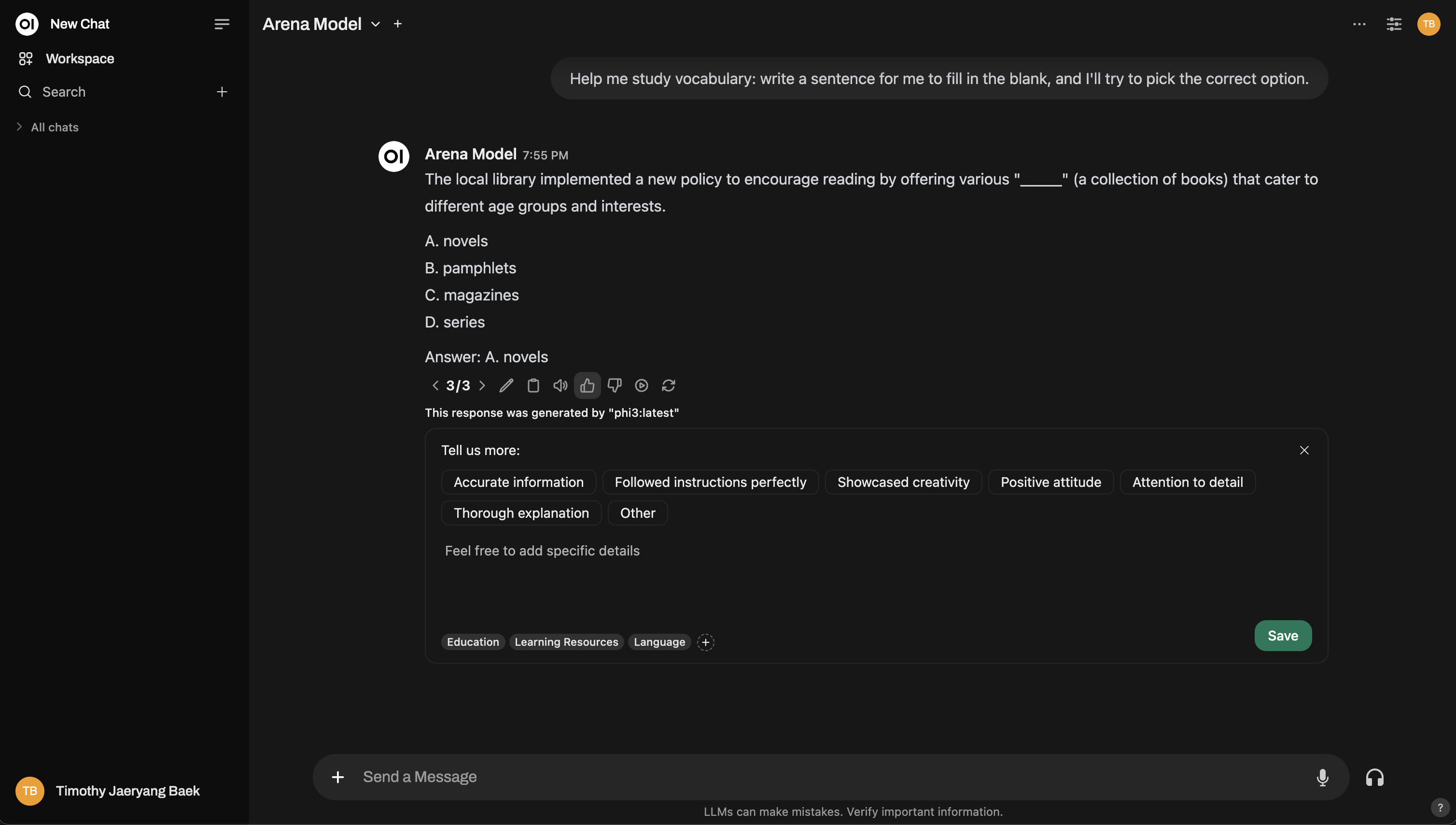
Besoin de plus de profondeur ? Vous pouvez même reproduire une configuration de Chatbot Arena !
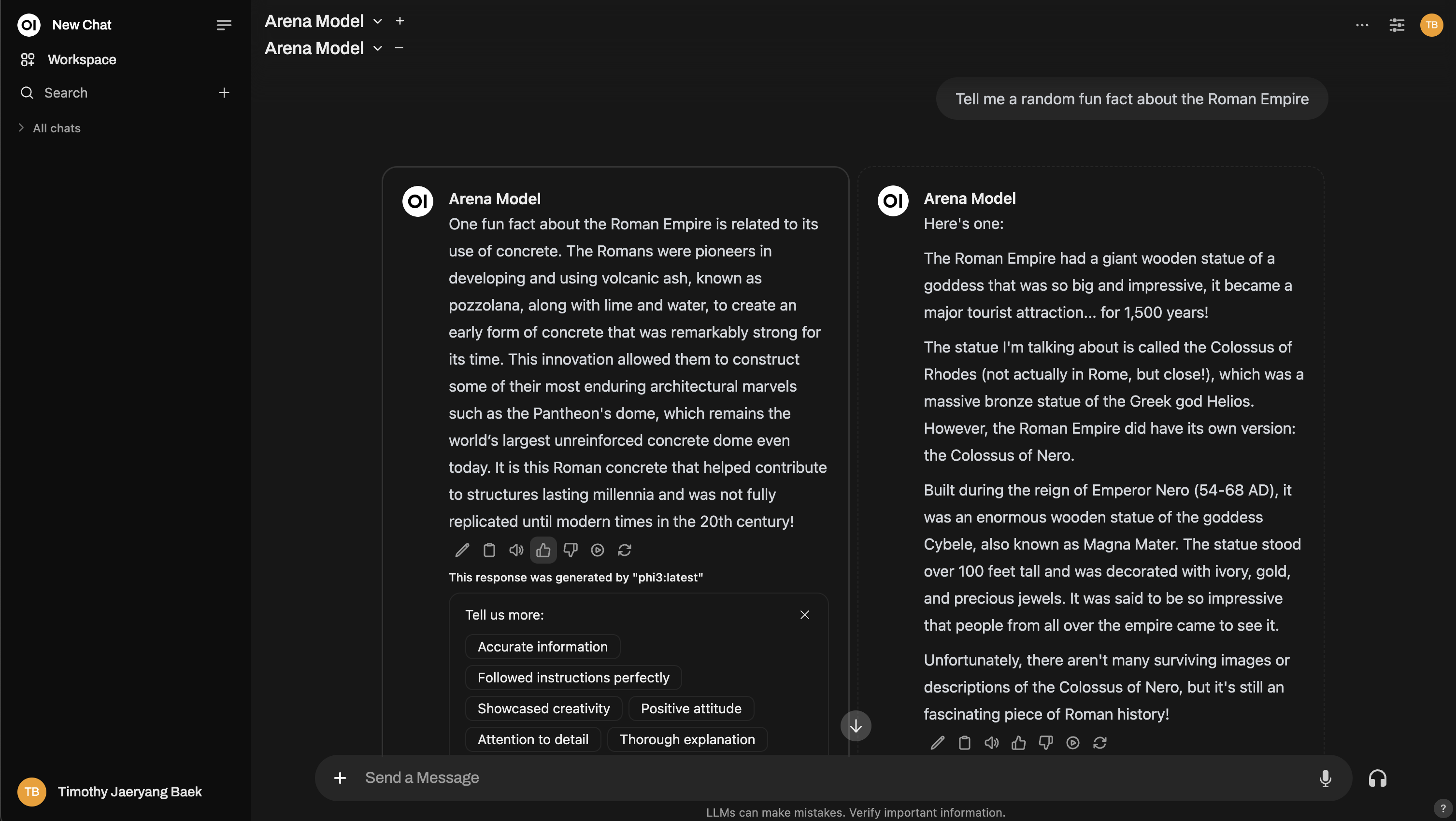
2. Interaction normale
Pas besoin de passer en “mode arène” si vous ne le souhaitez pas. Vous pouvez utiliser Open WebUI normalement et évaluer les réponses des modèles d'IA comme vous le feriez dans vos opérations quotidiennes. Il suffit de donner un pouce vers le haut/bas aux réponses des modèles, à tout moment. Cependant, si vous voulez que votre retour soit utilisé pour le classement sur le tableau de bord, vous devez changer de modèle et interagir avec un autre. Cela garantit qu'il y a une réponse parallèle à comparer – seules les comparaisons entre deux modèles différents influenceront les classements.
Par exemple, voici comment vous pouvez noter lors d'une interaction normale :
Et voici un exemple de configuration d'une comparaison multi-modèles, similaire à une arène :
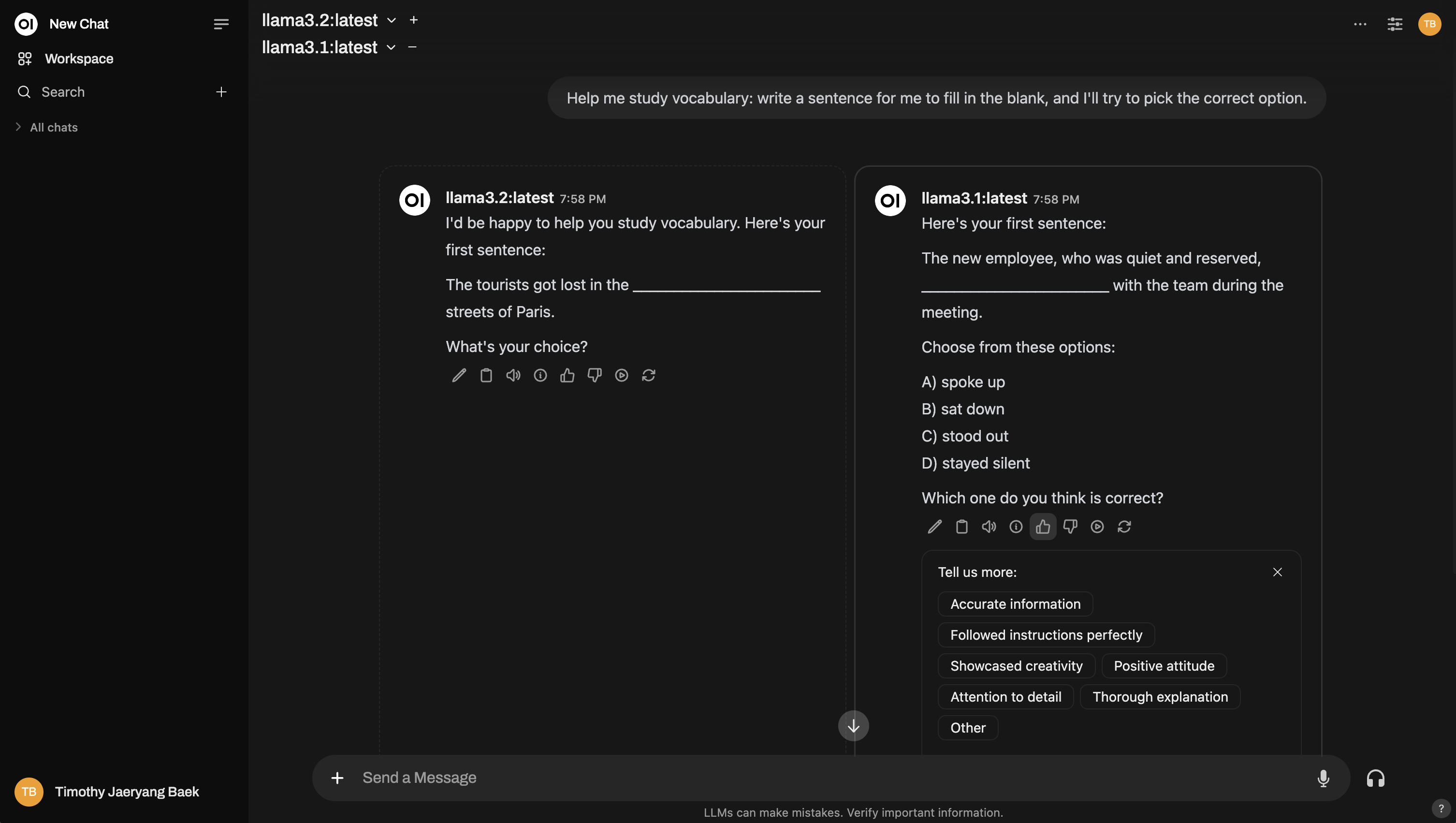
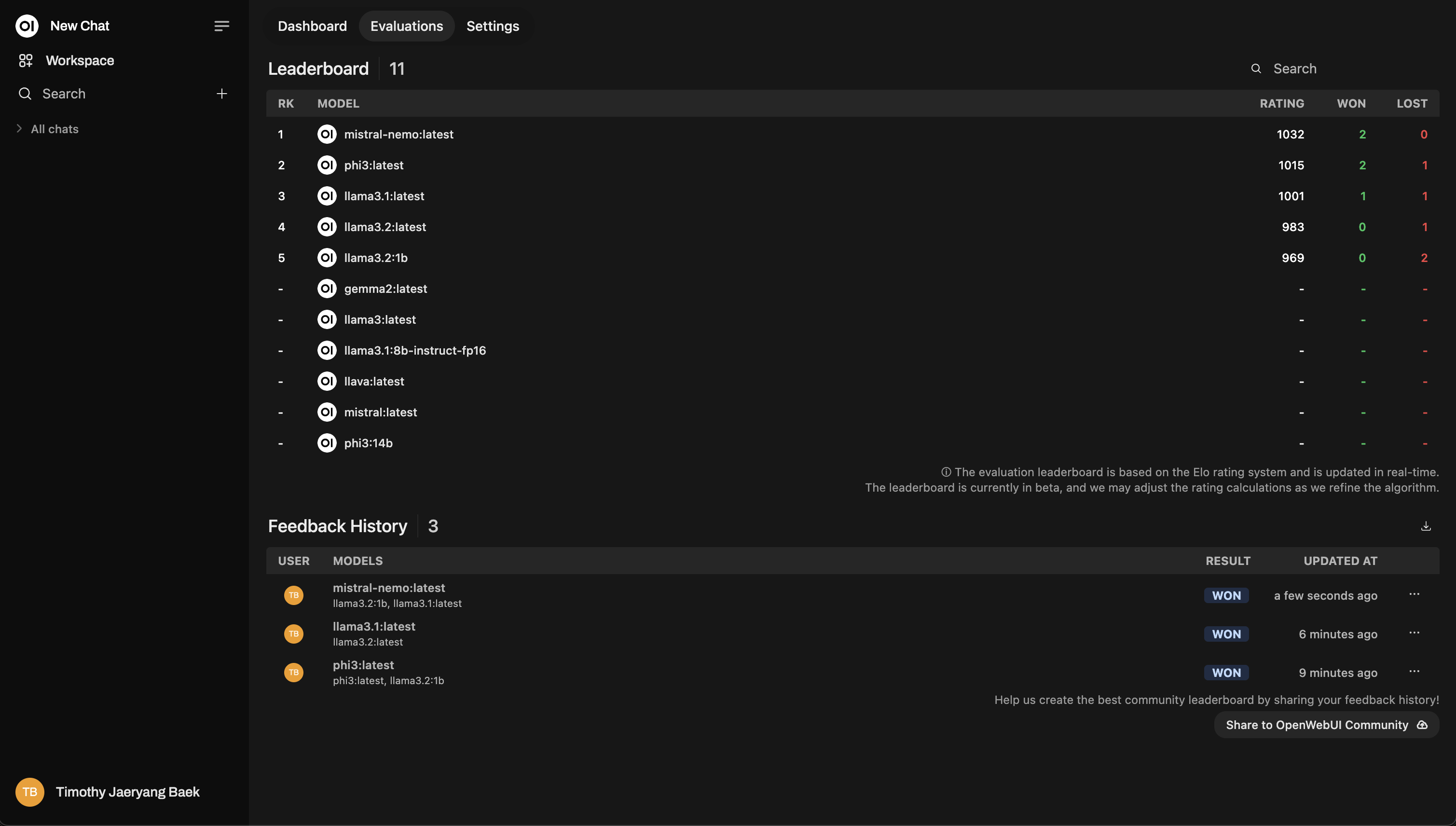
Tableau de classement
Après avoir évalué, consultez le Tableau des leaders dans le Panneau d'administration. C'est là que vous verrez visuellement les performances des modèles, classées selon un système de classement Elo (pensez aux classements d'échecs !) Vous aurez une vue réelle de quels modèles se distinguent véritablement lors des évaluations.
Voici un exemple de mise en page du tableau des leaders :
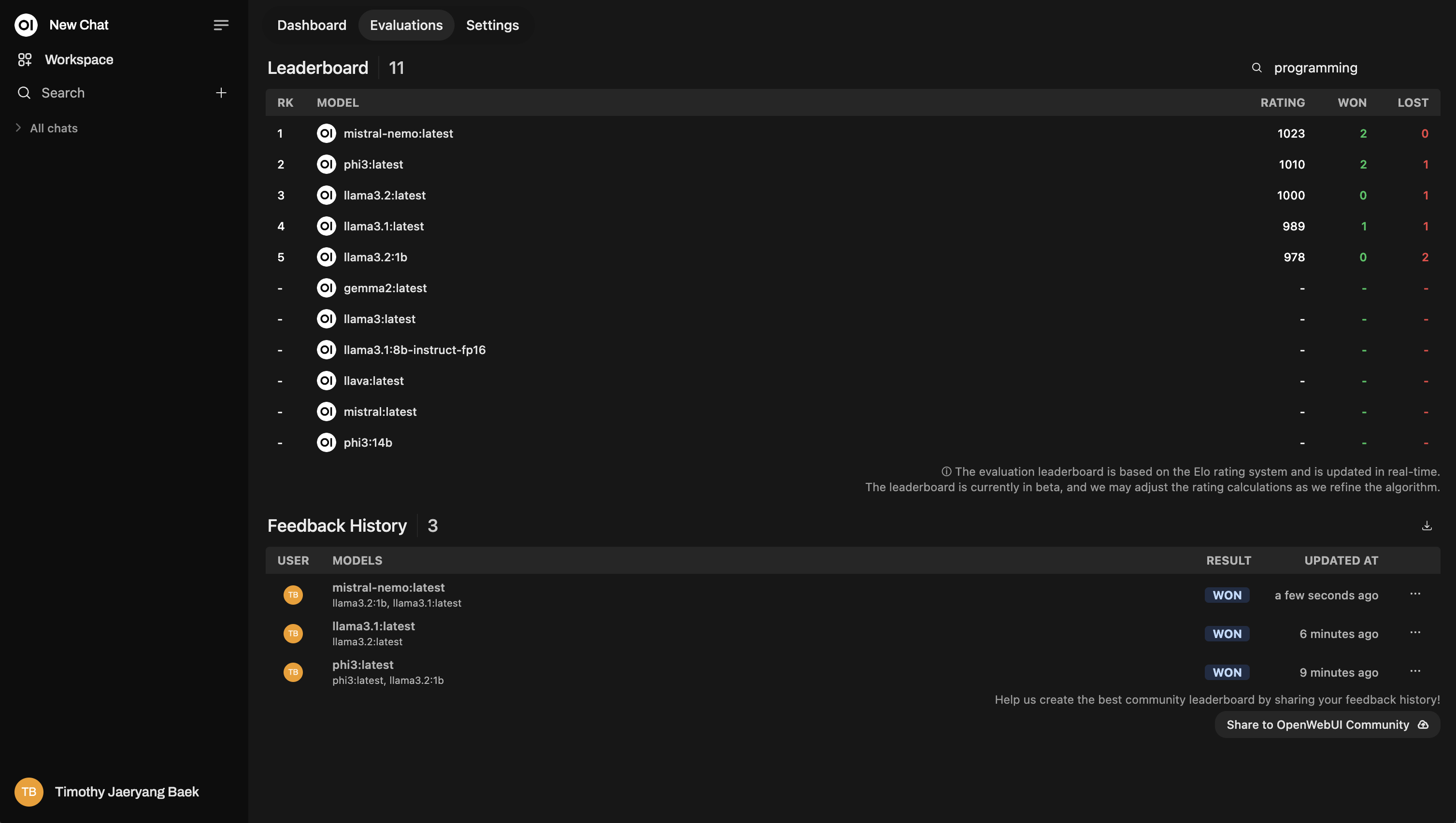
Reclassement basé sur les sujets
Lorsque vous évaluez des conversations, vous pouvez les taguer par sujet pour obtenir des informations plus détaillées. Cela est particulièrement utile si vous travaillez dans différents domaines comme service client, écriture créative, support technique, etc.
Tagging automatique
Open WebUI tente de taguer automatiquement les conversations en fonction du sujet de la discussion. Cependant, selon le modèle que vous utilisez, la fonctionnalité de tagging automatique peut parfois échouer ou mal interpréter la conversation. Lorsque cela arrive, il est préférable de taguer manuellement vos conversations pour garantir la précision du retour.
- Comment taguer manuellement : Lorsque vous évaluez une réponse, vous aurez la possibilité d'ajouter vos propres tags en fonction du contexte de la conversation.
Ne sautez pas cette étape ! Le tagging est extrêmement puissant car il vous permet de reclasser les modèles en fonction de sujets spécifiques. Par exemple, vous pourriez vouloir voir quel modèle performe le mieux pour répondre à des questions de support technique par rapport à des demandes générales des clients.
Voici un exemple de comment le reclassement apparaît :
Note complémentaire : Captures instantanées de discussion pour le perfectionnement des modèles
Chaque fois que vous évaluez une réponse de modèle, Open WebUI capture un instantané de cette discussion. Ces instantanés peuvent éventuellement être utilisés pour perfectionner vos propres modèles, permettant ainsi à vos évaluations de contribuer à l'amélioration continue de l'IA.
(Restez informés pour plus de mises à jour sur cette fonctionnalité, elle est en cours de développement !)
Résumé
En résumé, le système d'évaluation de Open WebUI a deux objectifs clairs :
- Vous aider à comparer facilement les modèles.
- Trouver, en fin de compte, le modèle qui correspond le mieux à vos besoins individuels.
Au cœur du système, tout tourne autour de rendre l'évaluation des modèles d'IA simple, transparente et personnalisable pour chaque utilisateur. Que ce soit via l'Arène des modèles ou l'Interaction de conversation normale, vous avez le contrôle total pour déterminer quel modèle d'IA fonctionne le mieux pour votre cas d'utilisation spécifique !
Comme toujours, toutes vos données restent sécurisées sur votre instance, et rien n'est partagé sauf si vous choisissez spécifiquement d'opter pour le partage communautaire. Votre confidentialité et autonomie des données sont toujours prioritaires.