📝 Avaliação
Por que devo avaliar modelos?
Conheça Alex, um engenheiro de aprendizado de máquina em uma empresa de médio porte. Alex sabe que existem inúmeros modelos de IA disponíveis — GPTs, LLaMA e muitos outros — mas qual é o melhor para o trabalho em questão? Todos parecem impressionantes no papel, mas Alex não pode simplesmente confiar nos rankings públicos. Esses modelos funcionam de maneira diferente dependendo do contexto, e alguns modelos podem ter sido treinados no conjunto de dados de avaliação (espertinho!). Além disso, o estilo de escrita desses modelos às vezes pode parecer... estranho.
É aqui que o Open WebUI entra em cena. Ele dá a Alex e sua equipe uma maneira fácil de avaliar modelos com base em suas necessidades reais. Sem cálculos complicados. Sem esforço pesado. Apenas 'gostei' ou 'não gostei' enquanto interagem com os modelos.
Resumo rápido
- Por que as avaliações são importantes: Muitos modelos, mas nem todos atendem às suas necessidades específicas. Rankings públicos nem sempre são confiáveis.
- Como resolver isso: Open WebUI oferece um sistema de avaliação integrado. Use 'gostei/não gostei' para avaliar as respostas dos modelos.
- O que acontece nos bastidores: As avaliações ajustam seu ranking personalizado, e instantâneos de conversas avaliadas serão usados para futuras melhorias nos modelos!
- Opções de avaliação:
- Modelo Arena: Seleciona modelos aleatoriamente para você comparar.
- Interação Normal: Basta conversar como de costume e avaliar as respostas.
Por que a avaliação pública não é suficiente?
- Rankings públicos não são adaptados ao caso de uso específico para você.
- Alguns modelos são treinados em conjuntos de dados de avaliação, afetando a imparcialidade dos resultados.
- Um modelo pode ter bom desempenho geral, mas seu estilo de comunicação ou respostas simplesmente não se encaixam no "tom" desejado.
A solução: Avaliação personalizada com Open WebUI
O Open WebUI tem um recurso de avaliação integrado que permite a você e sua equipe descobrir o modelo mais adequado às suas necessidades específicas — tudo enquanto interagem com os modelos.
Como funciona? Simples!
- Durante as conversas, deixe um 'gostei' se você gostar de uma resposta, ou um 'não gostei' se não gostar. Se a mensagem tiver uma mensagem irmã (como uma resposta regenerada ou parte de uma comparação lado a lado entre modelos), você está contribuindo para seu ranking pessoal.
- Rankings são facilmente acessíveis na seção de Administração, ajudando você a acompanhar quais modelos estão se saindo melhor de acordo com sua equipe.
Um recurso interessante? Sempre que você avalia uma resposta, o sistema captura um instantâneo daquela conversa, que será usado posteriormente para melhorar os modelos ou até mesmo para treinar modelos futuros. (Nota: isso ainda está sendo desenvolvido!)
Duas maneiras de avaliar um modelo de IA
O Open WebUI oferece duas abordagens diretas para avaliar modelos de IA.
1. Modelo Arena
O Modelo Arena seleciona aleatoriamente de um pool de modelos disponíveis, garantindo que a avaliação seja justa e imparcial. Isso ajuda a eliminar um possível problema na comparação manual: validade ecológica – garantir que você não favoreça conscientemente ou inconscientemente um modelo.
Como usar:
- Selecione um modelo na opção Modelo Arena.
- Use-o como faria normalmente, mas agora você está no modo 'arena'.
Para que seu feedback impacte o ranking, você precisa de uma mensagem irmã. O que é uma mensagem irmã? Uma mensagem irmã é qualquer resposta alternativa gerada pela mesma consulta (pense em regenerações de mensagens ou em ter vários modelos gerando respostas lado a lado). Assim, você está comparando as respostas cara a cara.
- Dica de pontuação: Quando você dá um 'gostei' a uma resposta, a outra automaticamente recebe um 'não gostei'. Então, preste atenção e opte pela resposta que você realmente acredita ser a melhor!
- Depois de avaliar as respostas, você pode conferir o ranking para ver como os modelos estão sendo classificados.
Aqui está uma prévia de como funciona a interface do Modelo Arena:
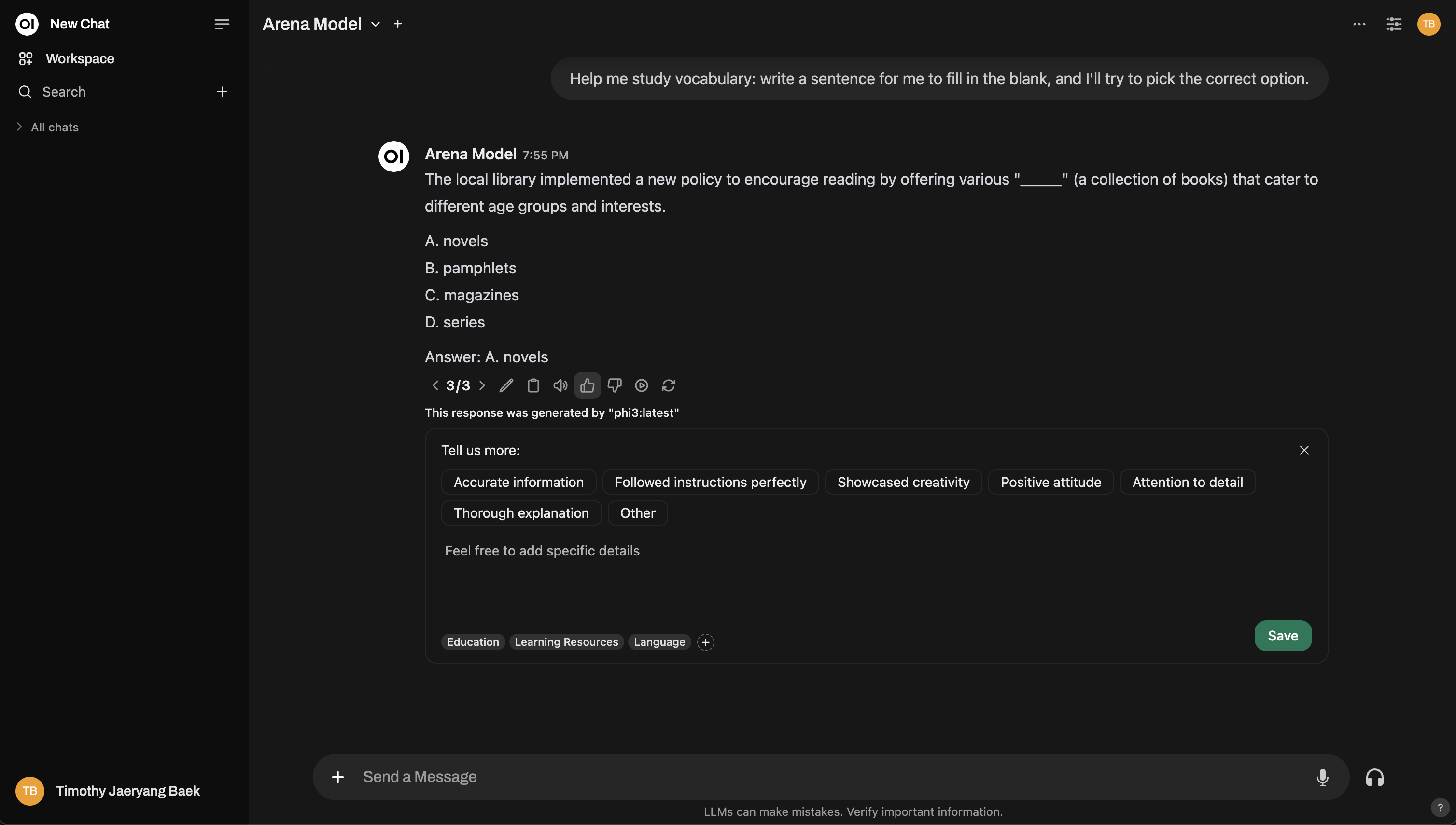
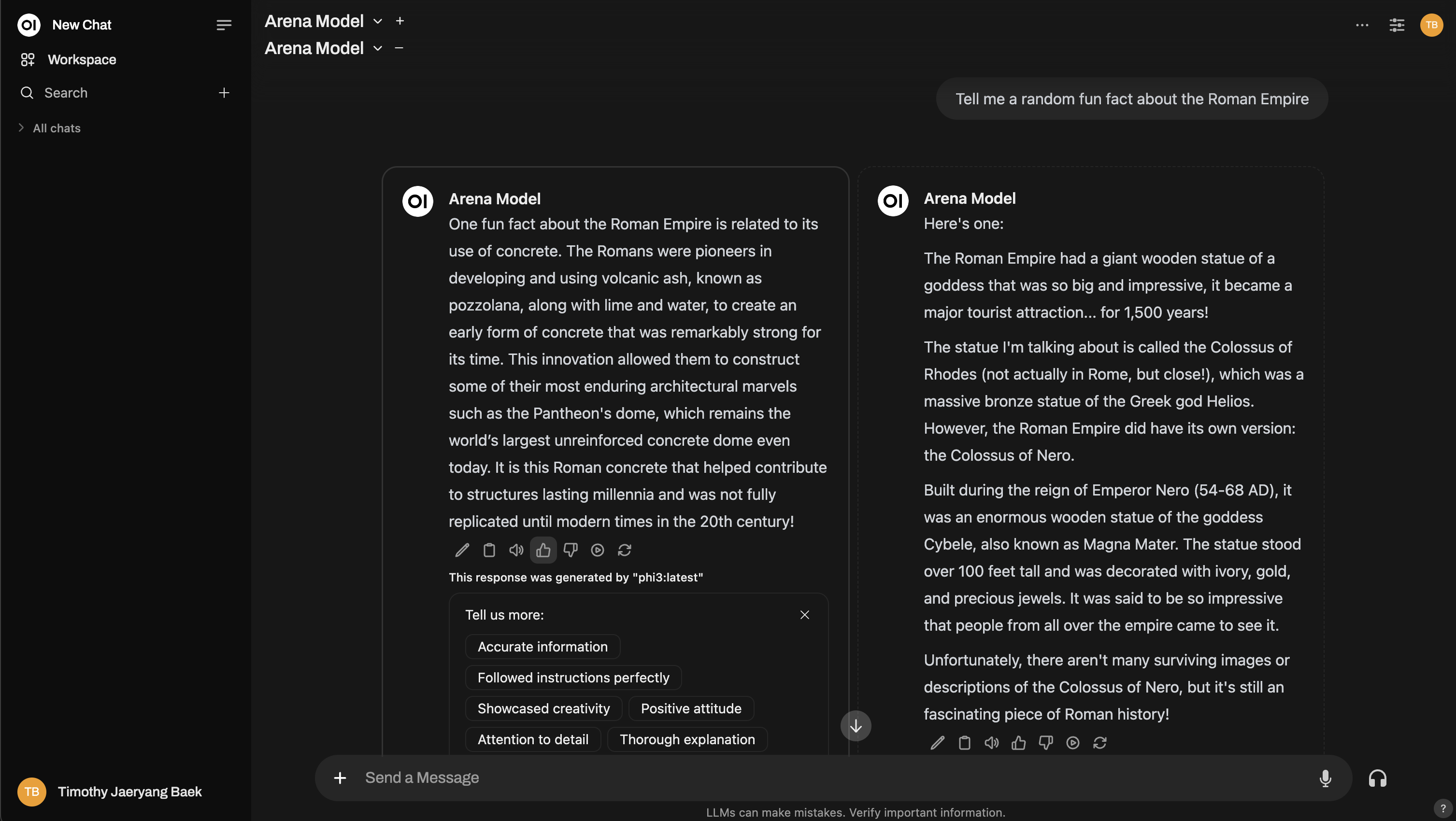
Precisa de mais profundidade? Você pode até mesmo replicar uma configuração no estilo Chatbot Arena!
2. Interação Normal
Não é necessário mudar para o modo 'arena' se você não quiser. Você pode usar o Open WebUI normalmente e avaliar as respostas do modelo de IA como faria em operações cotidianas. Basta usar 'gostei/não gostei' nas respostas do modelo, sempre que achar relevante. No entanto, se quiser que seu feedback seja usado para o ranking no leaderboard, será necessário trocar o modelo e interagir com um diferente. Isso garante que haja uma resposta irmã para compará-lo – apenas comparações entre dois modelos diferentes influenciarão os rankings.
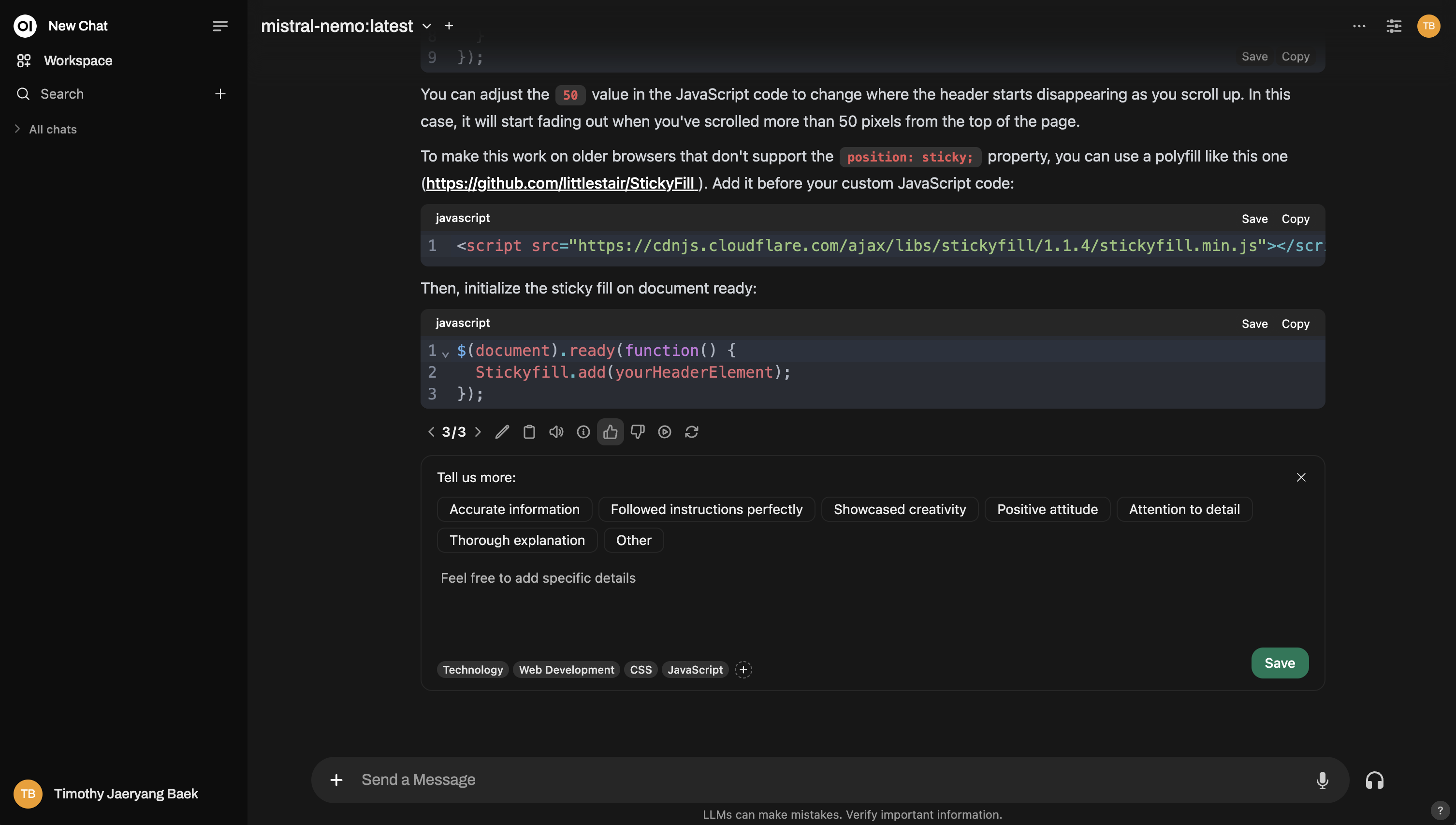
Por exemplo, veja como você pode avaliar durante uma interação normal:
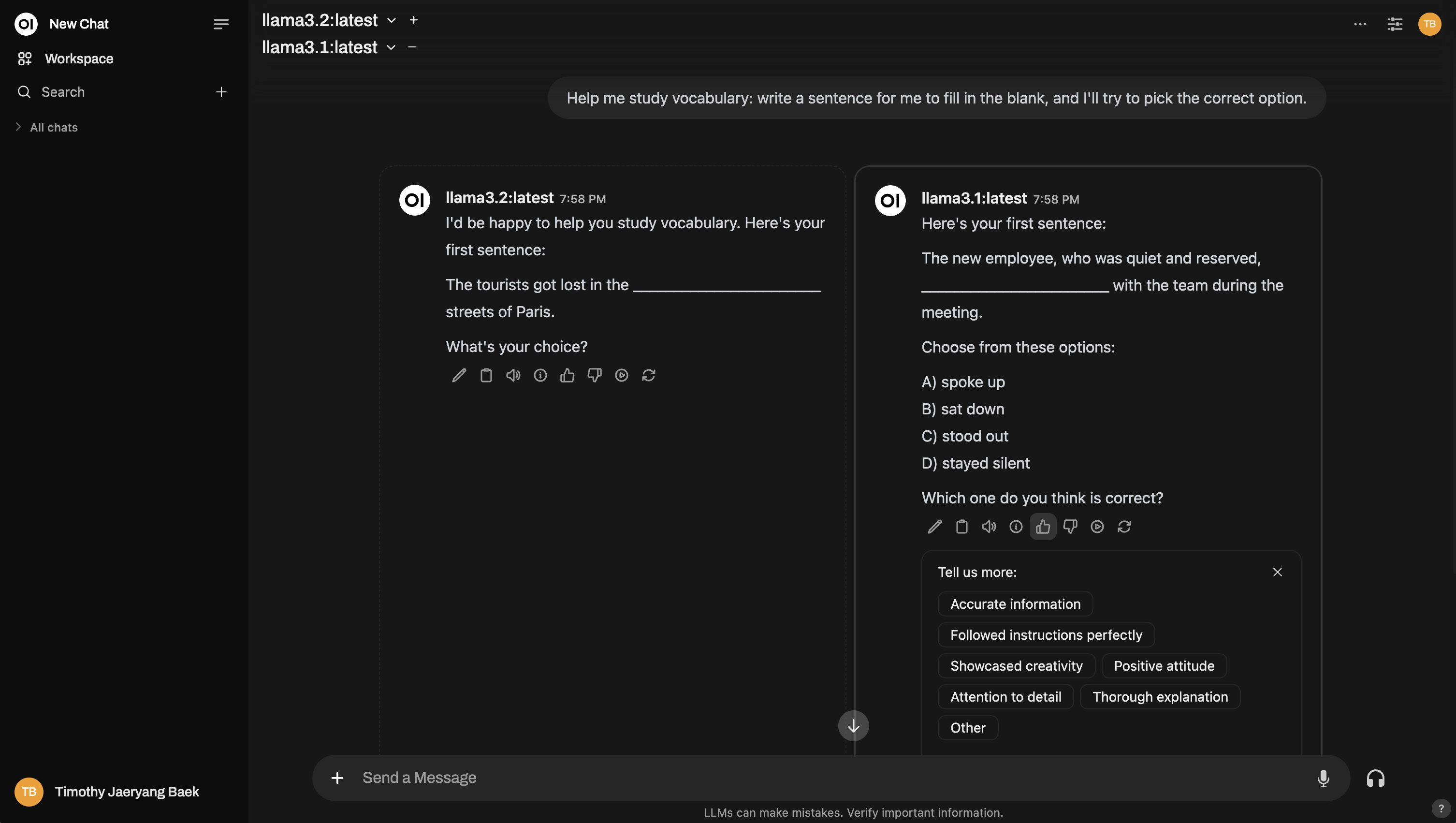
E aqui está um exemplo de configuração de comparação entre múltiplos modelos, semelhante à arena:
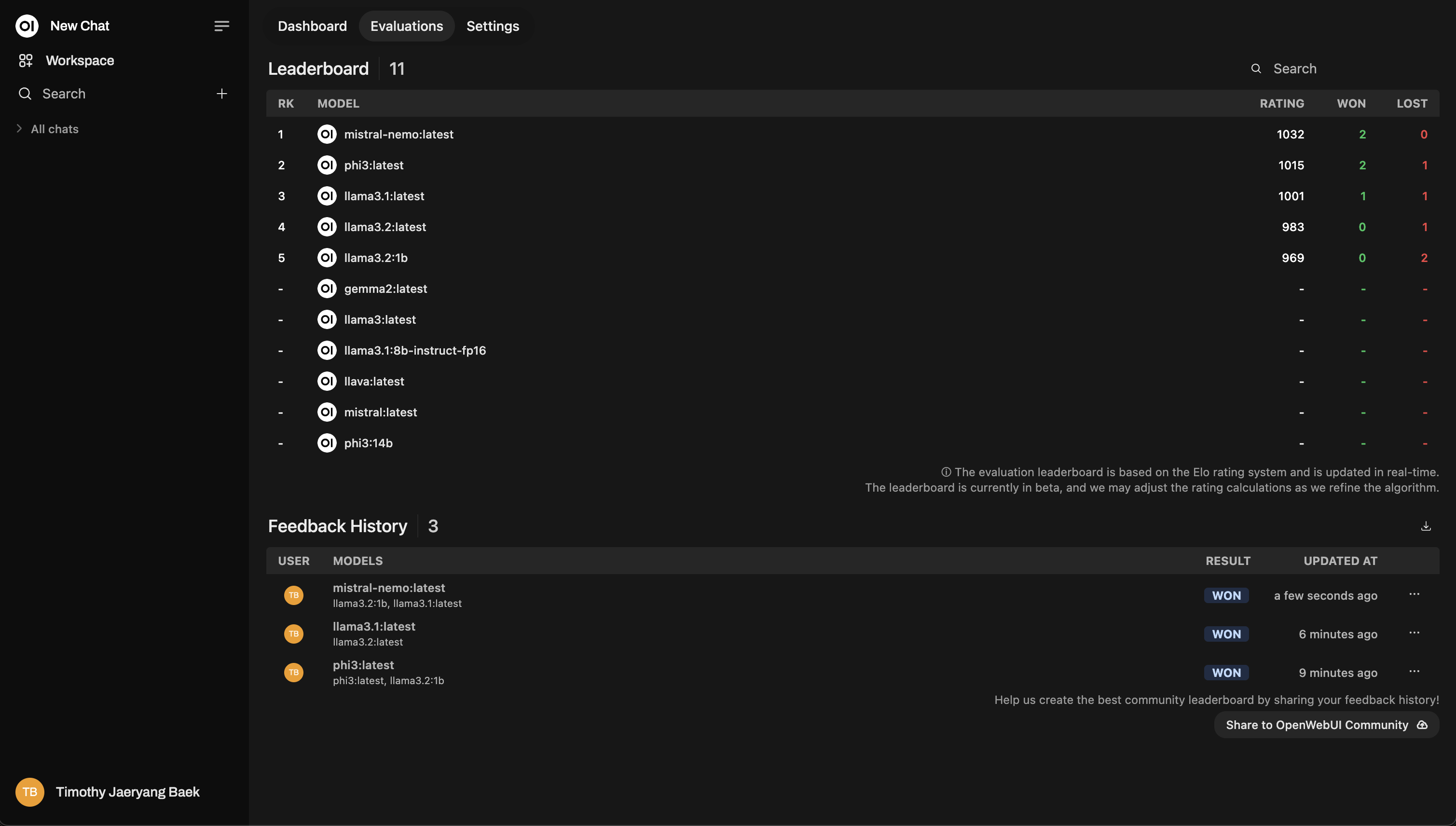
Ranking
Após avaliar, confira o Ranking no Painel Administrativo. É onde você verá visualmente como os modelos estão se saindo, classificados usando um sistema de classificação Elo (como rankings de xadrez!). Você terá uma visão real de quais modelos realmente se destacam durante as avaliações.
Este é um exemplo de layout do ranking:
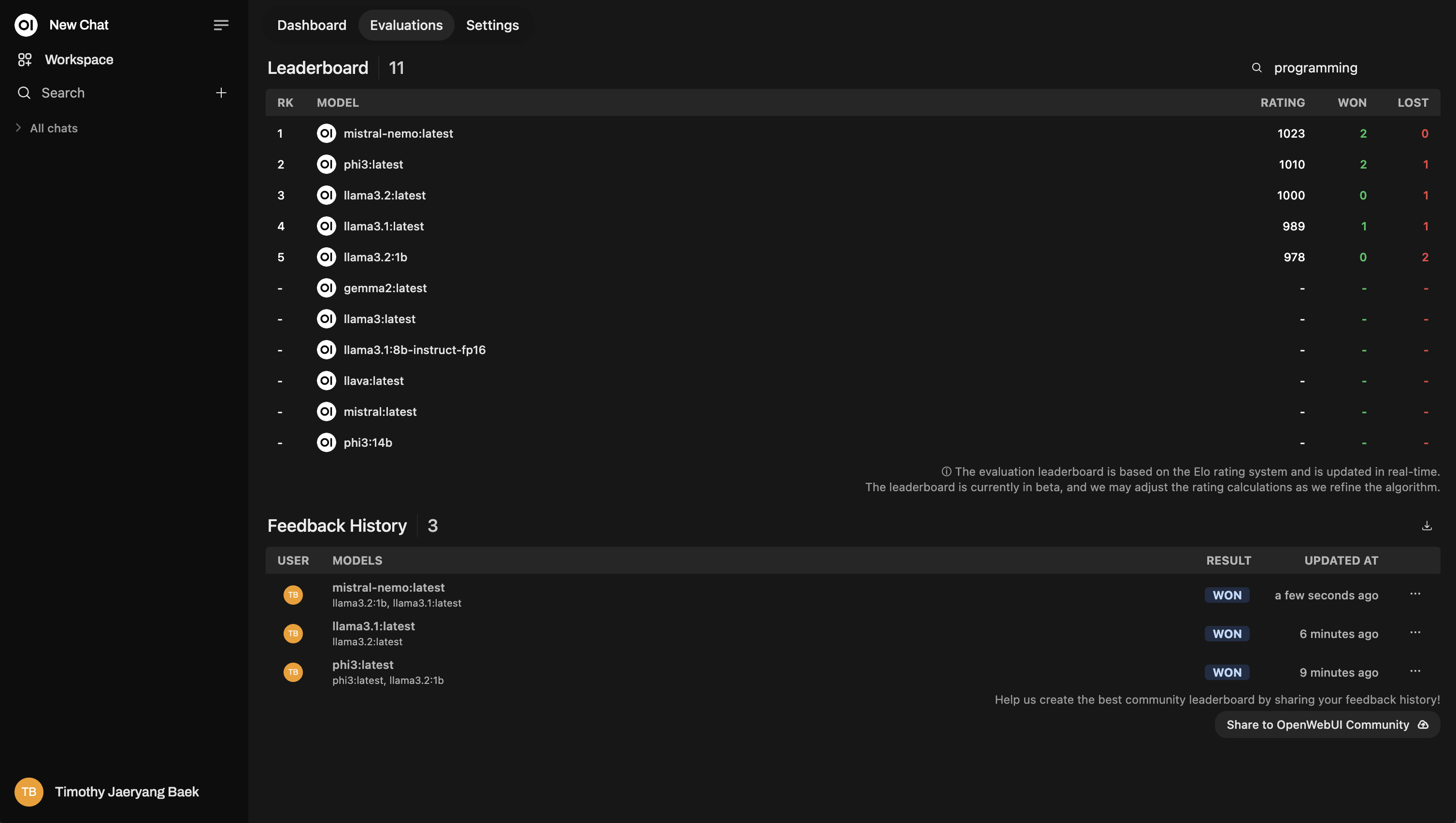
Reclassificação com Base em Tópicos
Ao avaliar os chats, você pode marcá-los por tópico para obter insights mais detalhados. Isso é especialmente útil se você estiver trabalhando em diferentes domínios, como atendimento ao cliente, redação criativa, suporte técnico, etc.
Marcação Automática
O Open WebUI tenta marcar chats automaticamente com base no tópico da conversa. No entanto, dependendo do modelo que você está utilizando, o recurso de marcação automática pode às vezes falhar ou interpretar de forma incorreta a conversa. Quando isso acontecer, é recomendável marcar manualmente seus chats para garantir que o feedback seja preciso.
- Como marcar manualmente: Ao avaliar uma resposta, você terá a opção de adicionar suas próprias marcas com base no contexto da conversa.
Não pule esta etapa! Marcar é extremamente poderoso porque permite reclassificar modelos com base em tópicos específicos. Por exemplo, você pode querer ver qual modelo se sai melhor ao responder perguntas de suporte técnico versus consultas gerais de clientes.
Aqui está um exemplo de como a reclassificação se parece:
Nota Adicional: Snapshots de Chats para Aperfeiçoamento de Modelos
Sempre que você avalia a resposta de um modelo, o Open WebUI captura um snapshot daquele chat. Esses snapshots podem eventualmente ser usados para aperfeiçoar seus próprios modelos—assim, suas avaliações alimentam o contínuo aprimoramento da IA.
(Fique atento para mais atualizações sobre este recurso, ele está sendo ativamente desenvolvido!)
Resumo
Em resumo, o sistema de avaliação do Open WebUI tem dois objetivos claros:
- Ajudar você a comparar modelos com facilidade.
- No final, encontrar o modelo que melhor se adapta às suas necessidades individuais.
No fundo, o sistema se trata de tornar a avaliação de modelos de IA simples, transparente e personalizável para cada usuário. Seja através do Modo Arena ou da Interação Normal de Chat, você tem total controle para determinar qual modelo de IA funciona melhor para o seu caso de uso específico!
Como sempre, todos os seus dados permanecem seguros na sua instância, e nada é compartilhado a menos que você especificamente opte por compartilhar com a comunidade. Sua privacidade e autonomia de dados são sempre priorizadas.