📝 Evaluación
¿Por Qué Debo Evaluar Modelos?
Conoce a Alex, un ingeniero de aprendizaje automático en una empresa de tamaño medio. Alex sabe que hay numerosos modelos de IA por ahí—GPTs, LLaMA y muchos más—pero, ¿cuál funciona mejor para el trabajo? Todos suenan impresionantes en papel, pero Alex no puede confiar únicamente en los rankings públicos. Estos modelos se comportan de manera diferente dependiendo del contexto, y algunos modelos podrían haber sido entrenados con el conjunto de datos de evaluación (¡astutos!). Además, la forma en que estos modelos escriben a veces puede sentirse... desajustada.
Es ahí donde entra Open WebUI. Ofrece a Alex y su equipo una forma fácil de evaluar modelos basándose en sus necesidades reales. Sin matemáticas complejas. Sin carga pesada. Solo pulgares arriba o abajo mientras interactúan con los modelos.
Resumen
- Por qué importa la evaluación: Hay demasiados modelos, pero no todos se ajustan a tus necesidades específicas. Los rankings públicos generales no siempre son confiables.
- Cómo resolverlo: Open WebUI ofrece un sistema de evaluación integrado. Usa pulgares arriba/abajo para calificar las respuestas del modelo.
- Qué sucede detrás de escena: Las calificaciones ajustan tu ranking personalizado, y capturas de chats calificados serán utilizadas para futuros ajustes finos del modelo.
- Opciones de evaluación:
- Modelo Arena: Selecciona modelos al azar para que los compares.
- Interacción Normal: Simplemente chatea como de costumbre y califica las respuestas.
¿Por Qué La Evaluación Pública No Es Suficiente?
- Los rankings públicos no están adaptados a tu caso de uso específico.
- Algunos modelos están entrenados con conjuntos de datos de evaluación, afectando la justicia de los resultados.
- Un modelo puede desempeñarse bien en general, pero su estilo de comunicación o respuestas simplemente no se ajustan al "tono" que deseas.
La Solución: Evaluación Personalizada con Open WebUI
Open WebUI tiene una función integrada de evaluación que permite a ti y tu equipo descubrir el modelo más adecuado para tus necesidades particulares, todo mientras interactúan con los modelos.
¿Cómo funciona? ¡Simple!
- Durante los chats, deja un pulgar arriba si te gusta una respuesta, o un pulgar abajo si no. Si el mensaje tiene un mensaje hermano (como una respuesta generada nuevamente o parte de una comparación de modelos lado a lado), estás contribuyendo a tu ranking personal.
- Los rankings son fácilmente accesibles en la sección de Administrador, ayudándote a rastrear qué modelos tienen el mejor rendimiento según tu equipo.
¿Una característica interesante? Cada vez que calificas una respuesta, el sistema captura una instantánea de esa conversación, que luego se usará para refinar modelos o incluso para entrenar futuros modelos. (Ten en cuenta que aún se está desarrollando).
Dos Formas de Evaluar un Modelo de IA
Open WebUI ofrece dos enfoques simples para evaluar modelos de IA.
1. Modelo Arena
El Modelo Arena selecciona al azar de un grupo de modelos disponibles, asegurando que la evaluación sea justa e imparcial. Esto ayuda a eliminar una posible falla en la comparación manual: validez ecológica – asegurarte de no favorecer un modelo consciente o inconscientemente.
Cómo usarlo:
- Selecciona un modelo del selector de Modelo Arena.
- Úsalo como lo harías normalmente, pero ahora estás en "modo arena".
Para que tu feedback afecte el ranking, necesitas lo que se llama un mensaje hermano. ¿Qué es un mensaje hermano? Un mensaje hermano es simplemente cualquier respuesta alternativa generada por la misma consulta (piensa en regeneraciones de mensajes o tener múltiples modelos generando respuestas lado a lado). Así, estás comparando respuestas cara a cara.
- Consejo para calificar: Cuando le das pulgar arriba a una respuesta, la otra automáticamente obtendrá un pulgar abajo. Así que, sé cuidadoso y solo vota a favor del mensaje que consideres genuinamente el mejor.
- Una vez que califiques las respuestas, puedes revisar el ranking para ver cómo se comparan los modelos.
Aquí tienes una vista preliminar de cómo funciona la interfaz del Modelo Arena:
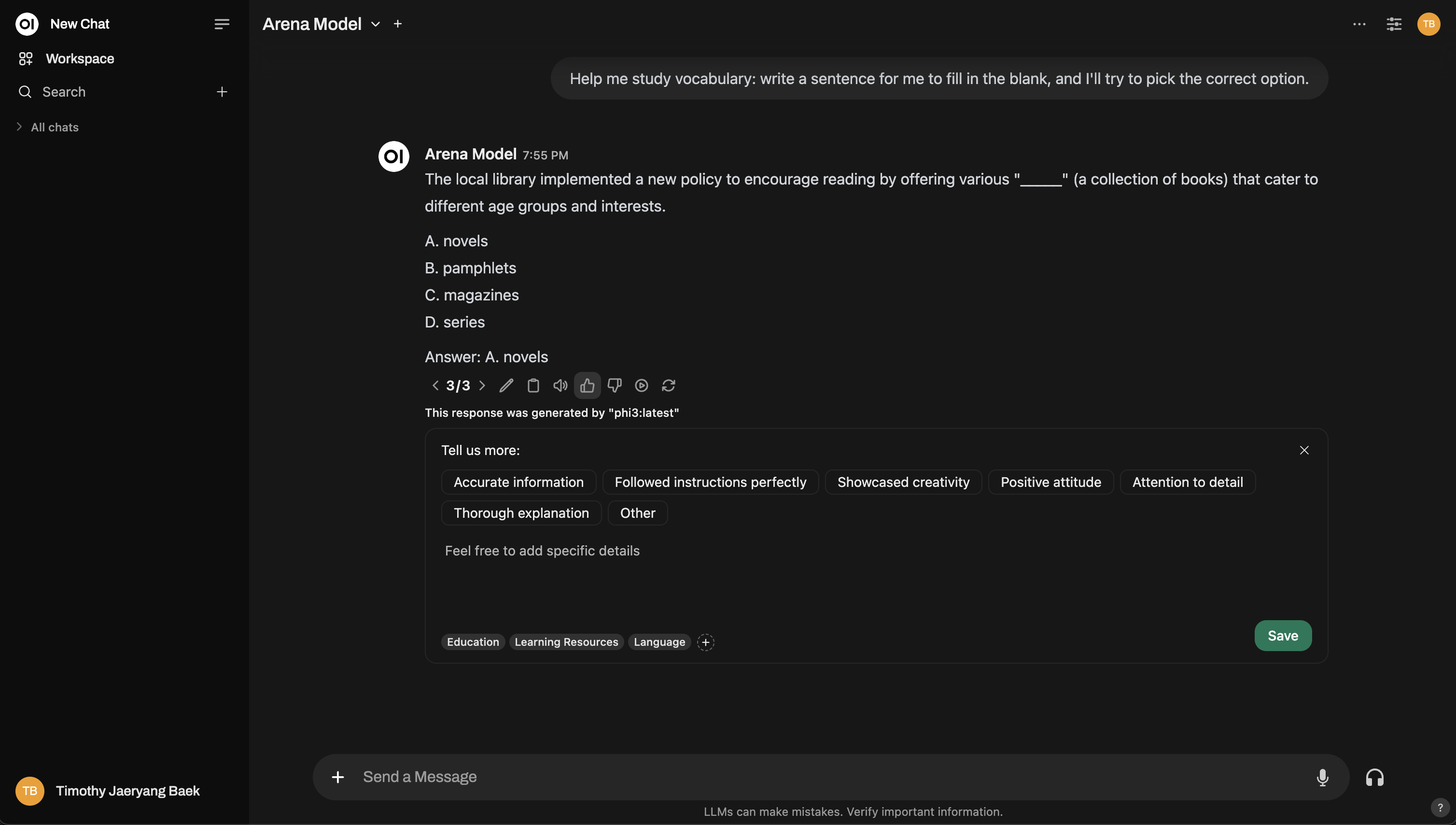
¿Necesitas más detalle? Incluso puedes replicar una configuración estilo Chatbot Arena!
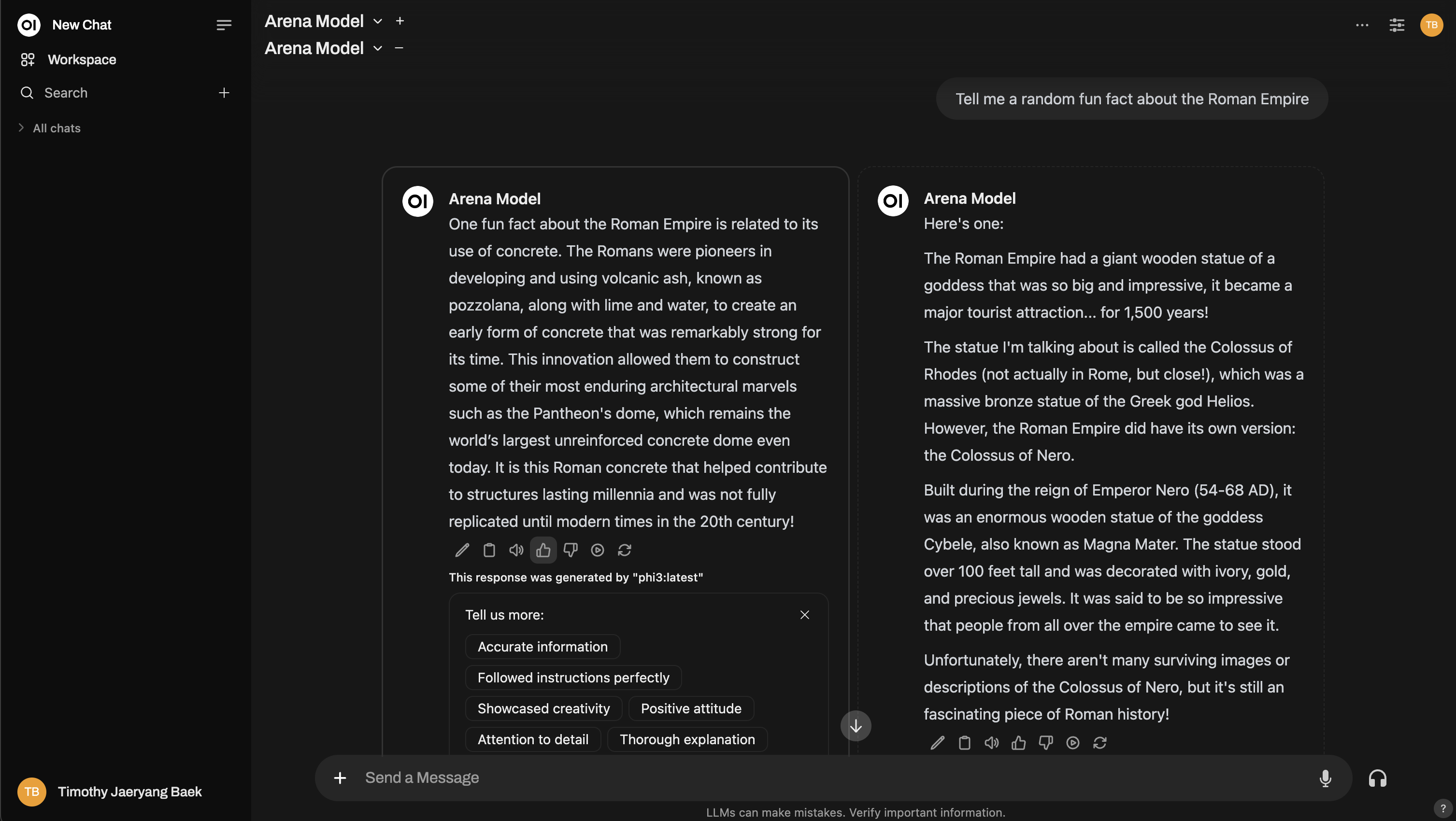
2. Interacción Normal
No necesitas cambiar a "modo arena" si no quieres. Puedes usar Open WebUI normalmente y calificar las respuestas del modelo de IA como lo harías en las operaciones diarias. Simplemente da pulgares arriba/abajo a las respuestas del modelo, cuando lo consideres oportuno. Sin embargo, si deseas que tus comentarios se utilicen para el ranking en el tablero, necesitarás cambiar el modelo e interactuar con uno diferente. Esto asegura que haya una respuesta hermana para compararla—solo las comparaciones entre dos modelos diferentes influirán en los rankings.
Por ejemplo, así es como puedes calificar durante una interacción normal:
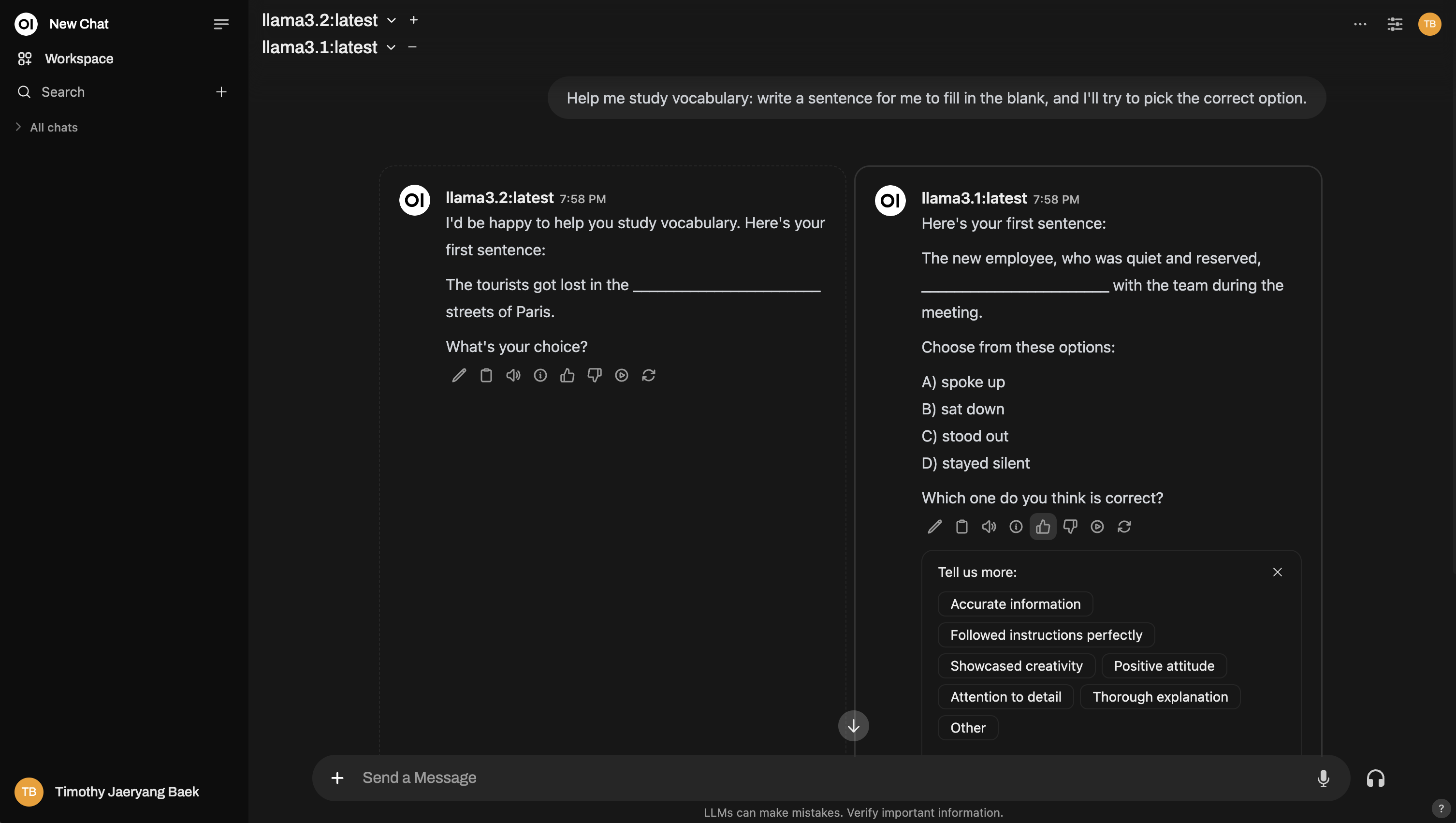
Y aquí hay un ejemplo de cómo configurar una comparación multi-modelo, similar a una arena:
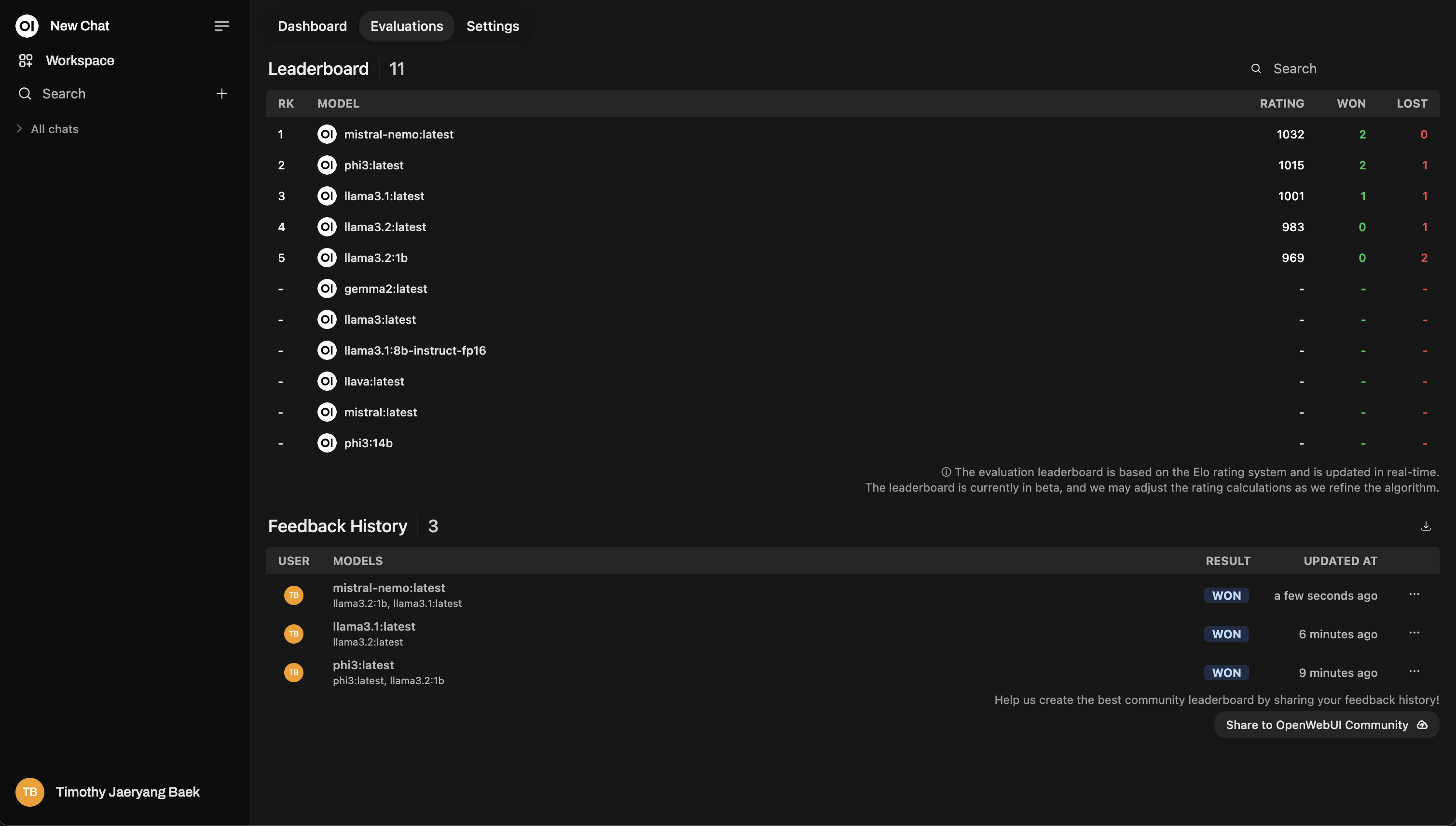
Tablero
Después de calificar, revisa el Leaderboard en el Panel de Administración. Aquí podrás ver visualmente cómo se desempeñan los modelos, clasificados usando un sistema de calificación Elo (¡similar al ranking de ajedrez!). Obtendrás una visión real de cuáles modelos realmente destacan durante las evaluaciones.
Este es un ejemplo del diseño de una tabla de clasificación:
Reordenación Basada en Temas
Cuando calificas chats, puedes etiquetarlos por tema para obtener información más detallada. Esto es especialmente útil si trabajas en diferentes dominios como servicio al cliente, escritura creativa, soporte técnico, etc.
Etiquetado Automático
Open WebUI intenta etiquetar automáticamente los chats según el tema de la conversación. Sin embargo, dependiendo del modelo que estés utilizando, la función de etiquetado automático podría fallar ocasionalmente o malinterpretar la conversación. Cuando esto suceda, es una buena práctica etiquetar manualmente tus chats para garantizar que la retroalimentación sea precisa.
- Cómo etiquetar manualmente: Cuando califiques una respuesta, tendrás la opción de añadir tus propias etiquetas según el contexto de la conversación.
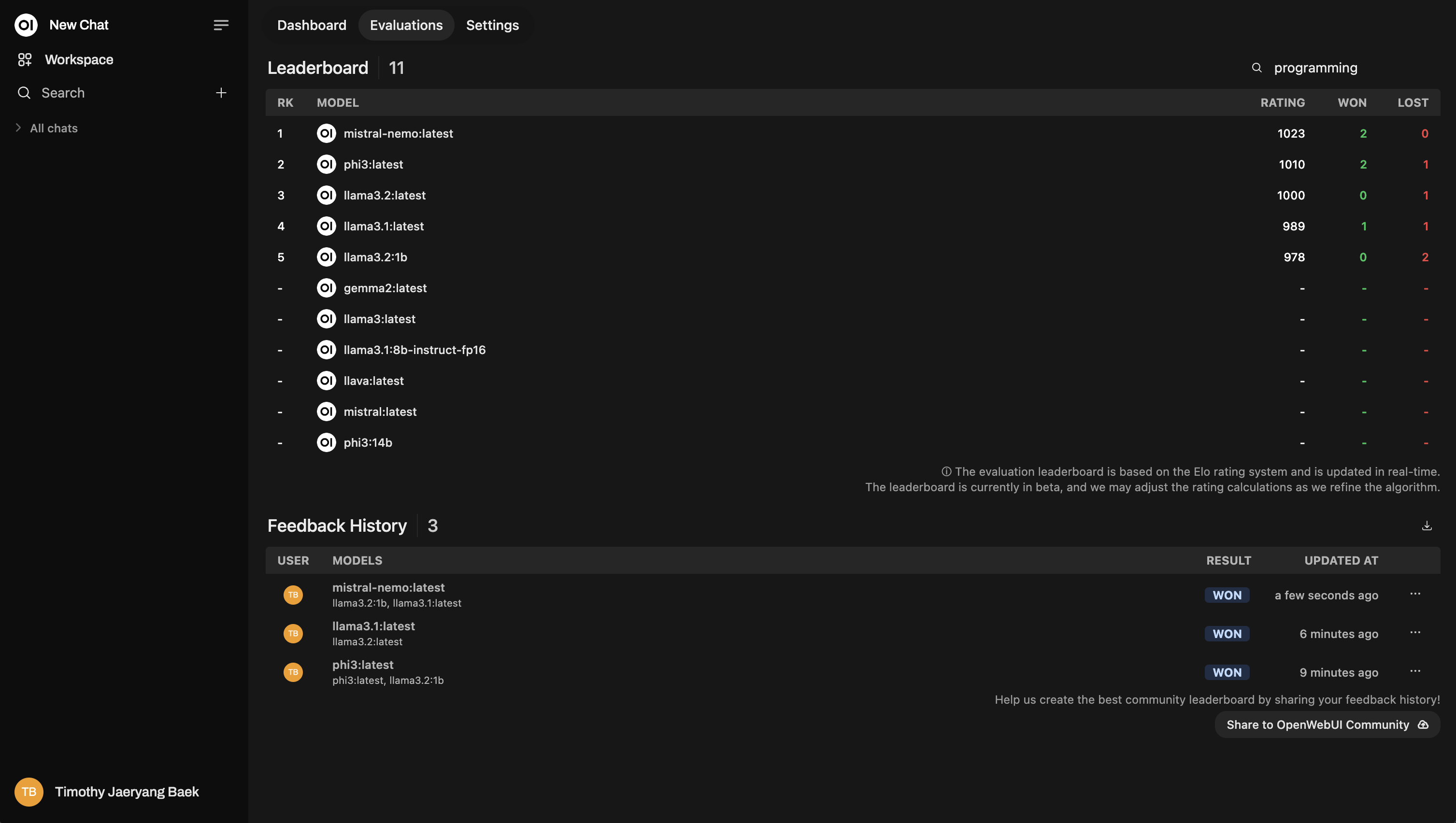
¡No te saltes este paso! El etiquetado es muy poderoso porque te permite reordenar los modelos según temas específicos. Por ejemplo, podrías querer ver qué modelo funciona mejor al responder preguntas de soporte técnico en comparación con consultas generales de clientes.
Aquí tienes un ejemplo de cómo se ve la reordenación:
Nota Adicional: Capturas de Conversaciones para Ajuste de Modelos
Cada vez que calificas la respuesta de un modelo, Open WebUI captura una instantánea de ese chat. Estas instantáneas eventualmente pueden usarse para ajustar tus propios modelos—por lo que tus evaluaciones contribuyen a la mejora continua de la IA.
¡Mantente atento para más actualizaciones sobre esta función, se está desarrollando activamente!
Resumen
En resumen, el sistema de evaluación de Open WebUI tiene dos objetivos claros:
- Ayudarte a comparar modelos fácilmente.
- Finalmente encontrar el modelo que mejor se adapte a tus necesidades individuales.
En su esencia, el sistema se trata de hacer que la evaluación de modelos de IA sea simple, transparente y personalizable para cada usuario. Ya sea a través del Modelo de Arena o la Interacción Normal en el Chat, tienes el control total para determinar qué modelo de IA funciona mejor para tu caso de uso específico.
Como siempre, todos tus datos permanecen de forma segura en tu instancia, y nada se comparte a menos que específicamente optes por compartirlos con la comunidad. Tu privacidad y autonomía sobre los datos siempre son prioritarias.